

By Eduardo Silva, Fluentd Maintainer

When deploying applications – either for development or production purposes – there are several steps one needs to take to have a healthy environment. One such step is making sure you have logging capabilities from the application to its environment. This is mandatory if you want to perform continuous monitoring and have the ability to troubleshoot any anomaly during or after runtime.
Regardless of your environment, logging can be complex. System services and specific application logs need to be consumed different ways and the data retrieved likely comes in a variety of different formats, which presents an interest challenge. In the Cloud Native era, we see this complexity increase when deployment happens at scale. At this point having a non-generic logging tool is not enough to solve the problem. Instead a custom solution capable to integrate, understand and connect the dots between different end-points is highly recommended; that’s why Fluentd was created.
Unified Logging Layer
Fluentd allows you to implement an unified logging layer in any type of environment. It was designed with flexibility in mind, with a pluggable architecture of more than 600 extensions provided by the community, and can collect, parse, filter and deliver logs from any source to most of the well known destinations like local databases or cloud services:
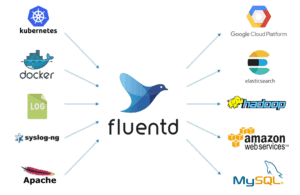
Looking to the future
When the project was started in 2011 by Treasure Data, its primary goal was to solve the data collection problem. Due to its Open Source nature and quick adoption by the industry, it experienced amazing organic growth. Today, we can see Fluentd integrated in Docker and Kubernetes ecosystems and running in thousands of environments, but still there is plenty of room to grow.
From a project and technical perspective, better integration with different cloud native environments is a future goal, as well as establishing a formal and closed relationship with core teams of related projects would help Fluentd maintainers better understand their needs and align development efforts. Since openness and collaboration is part of the Fluentd DNA, the core team decided it was time to take the next big step and join a Foundation.
Fluentd joins CNCF
When the core team decided to join a Foundation, we evaluated many different options and found the Cloud Native Computing Foundation (CNCF) to be a really good fit. The Foundation provides enough flexibility to let the project grow organically, but the benefit of attracting resources that would better Fluentd from a technical and community aspect.
In mid 2016, the core team started our application process with the CNCF Technical Oversight Committee (TOC). It took a few months of positive technical discussions to met the general requirements. Finally, the day before the inaugural CloudNativeCon/KubeCon (November 7th), the TOC approved and welcomed Fluentd as an official CNCF project:

Note, Fluentd is a whole ecosystem with 35 repositories including Fluentd service, plugins, language SDKs and complementary projects such as Fluent Bit (lightweight forwarder) on our Github Organization. All of them are part of CNCF now!
What’s next ?
We are committed to improving all Logging aspects of Cloud Native projects. Currently, the core Fluentd team is participating in the Kubernetes sig-instrumentation group and looking forward to an integration with Prometheus and other projects of the stack.
We expect to release Fluentd v1.0 near Q1 2017, which will bring exciting features such as an enhanced API for plugins, Windows Support and Compression/Authentication for network transfers within others.
The Fluentd community will continue to participate actively at open source events such as CloudNativeCon. We invite everyone to join us and want to hear from you! Feel free to reach us through the usual communication channels:
- Slack: http://slack.fluentd.org
- Twitter: http://twitter.com/fluentd
- Mailing List: https://groups.google.com/forum/#!forum/fluentd
Thanks again and Happy Logging!