

Guest post from Kiran Mova and Chuck Piercey, MayaData
BigData, AI/ML and modern analytics permeate the business world and have become a critical element of enterprise strategies to serve customers better, innovate faster and stay ahead of the competition. Data is core to all of this. In this blog, we focus on how the Kubernetes and related container native storage technologies are enabling the data engineers (aka DataOps teams) to build scalable, agile data infrastructure that achieves these goals.
Being a Data-Driven Enterprise is Strategic
Enterprises are increasing their spending to enable data driven decisions and foster a data driven culture. A recent survey of enterprise executives’ investments showed the importance of data-driven analytics to the C-suite.

One data point to highlight is the fact that people and process pose greater challenges to adoption than technology and tools.

What is DataOps
Kubernetes has changed the landscape of application development. With emerging data operators in Kubernetes-managed data infrastructures, we have entered a new world of self-managed data infrastructures called DataOps. Inspired by DevOps, DataOps is a way to enable collaboration between distributed autonomous teams’ data analysts, data scientists and data engineers with shared KPIs.
“DataOps stems from the DevOps movement in the software engineering world which bridges the traditional gap between development, QA, and operations so the technical teams can deliver high-quality output at an ever-faster pace. Similarly, DataOps brings together data stakeholders, such as data architects, data engineers, data scientists, data analysts, application developers, and IT operations….DataOps applies rigor to developing, testing, and deploying code that manages data flows and creates analytic solutions.” – Wayne W. Eckerson DataOps white paper
A key aspect of Kubernetes success is that DevOps can drive everything through versioned-managed Intent/YAML files (aka GitOps) to manage infrastructures the same way IT manages code reproducibly and scalably. The same approach can be applied to DataOps.
Siloed Teams & Processes Fail at DataOps
Data pipelines produced by organizational silos built around specialized teams (still in use by many businesses today) will suffer from having the delivery responsibility split across those functional groups. The organizational structure constrains the development process to something that can bridge the gaps between tools and this approach will ineluctably be prone to failures caused by the bureaucracy itself.
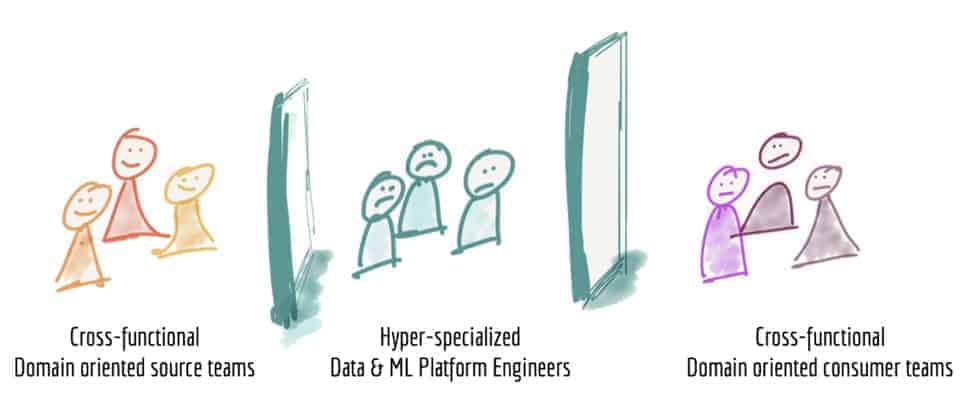
Integrated Teams & Processes Succeed at DataOps
A recent article on Distributed Data Mesh proposes many organizational and technical changes to how Data Engineering / Science teams can become more effective and agile, like the success seen by product development teams using DevOps/SRE culture. A shift from a tool focus to a CI/CD process focus is core to the paradigm. Both process and development execution necessarily co-evolve and, unsurprisingly, such teams often are themselves distributed, much like the architecture they build on. In her paper, Zhamak Dehghani proposes an approach for managing data as a product that parallels the DevOps techniques applied to commercial software products and teams.
The core of her approach is to redefine the team and its responsibilities by shifting the architectural milieu from a focus on technology and tools (like Data Engineers, ML Engineers, Analytics Engineers) to a more interdisciplinary concept structured around treating Data itself as a Product. In this structure, each Data Product has an independent team that can innovate, select tools, and implement while exposing data results using a standard API contract.
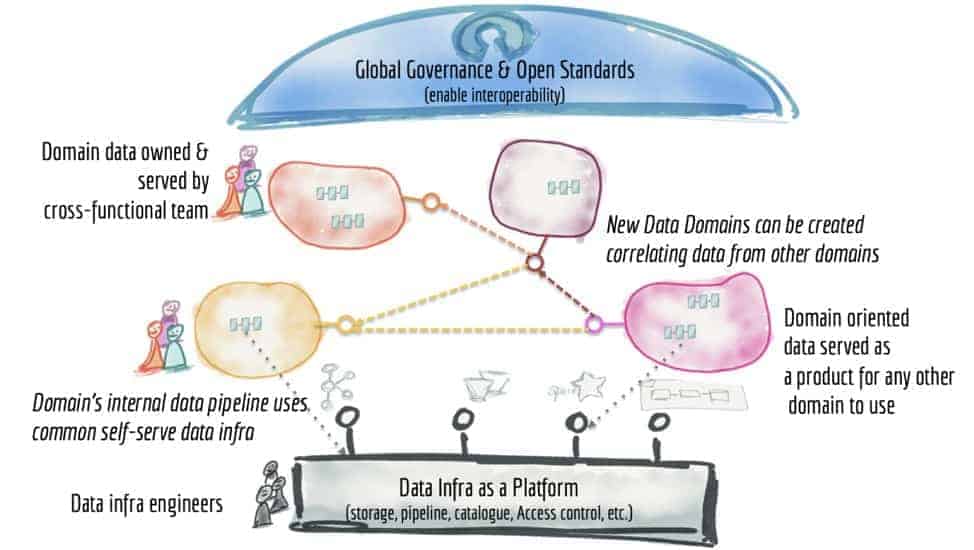
These teams consist of a variety of skill sets: data engineers, data scientists, data analysts, ML engineers, decision makers, data collection specialists, data product managers, and reliability engineers (while the roles for successful data product teams are clear, individuals can simultaneously fulfill multiple roles). Critically, all team members interact with a shared set of DataOps processes.
Declarative Data Infrastructure
DataOps relies on a data infrastructure that can abstract away platform-specific features and allow product teams to focus on the data they own while leveraging shared resources. The key enabling technology for DataOps is Declarative Data Infrastructure (DDI). DDI refers to both the data and the storage infrastructure running on Kubernetes and is the technology stack that converts compute, network, and storage into a scalable, resilient and self-managed global resource that each autonomous team can use without having to wait on approvals from central storage administrators. Kubernetes and related technologies have emerged as a standard that enables the DDI technology stack.
For example, the data infrastructure in the data mesh example above is comprised of three layers:
- A Data Pipeline – like the Airflow framework
- A Data Access Layer – like Apache Kafka or Postgres
- A Data Storage Layer – like OpenEBS.
In the past couple of years, we have seen quite a few technologies under the Data Pipeline and Data Access Layer move towards Kubernetes. For instance, it isn’t uncommon for data engineering teams to move away from Hadoop-based systems to something like Pachyderm, moving their data pipelines into Kubernetes with Airflow to reduce the cost of infrastructure and create reproducible, resilient and extensible data pipelines.
Kubernetes projects like Airflow have reached maturity on the data pipelines’ implementation and orchestration over the past two years and are being adopted at companies like Lyft, Airbnb, Bloomberg.
Correspondingly, data pipeline’s adoption has triggered and enabled a new breed of products and tools for the Data Access and Storage Layers it feeds.
An excellent example that demonstrates the move of Data Access Layer into Kubernetes is the Yolean prebuilt Kafka cluster on Kubernetes that delivers a production-quality, customizable Kafka-as-a-service Kubernetes cluster. Recently, Intuit used this template to rehost all their financial applications onto Kubernetes.
Two components have made the data access layer easier. The first is a shim layer that provides declarative YAMLs for instantiating the Data Access Layer (like Kafka) for either an on-prem version or a managed service version. This approach to running the Data Access Layer helps users migrate from current implementations into Kubernetes. It suffers by locking users into specific implementations. An alternate approach is to have the Operators build the data access layer so that it can run on any storage layer, thereby avoiding cloud vendor lock-in.
The data storage layer is seeing a similar shift, responding in part to the rise of new, inherently distributed workloads and the emergence of a new set of users as well. There are several Kubernetes native storage solutions that are built using the same declarative philosophy and managed by Kubernetes itself, that we refer as the Declarative Data Plane.
Declarative Data Plane
The data plane is composed of two parts:
- An Access Layer which primarily concerns with the access to the storage, and
- Data Services like replication, snapshot, migration, compliance and so forth.
CSI, a standard Declarative Storage Access Layer
Kubernetes and the CNCF vendor and end user community have been able to achieve a vendor neutral standard in the form of CSI to enable any storage vendors to provide storage to the Kubernetes workloads. The workloads can be running on any type of container runtime – docker or hypervisors. In part, the success of some of the self-managed Data Access Layer products can be attributed to CSI as a standard and constructs like Storage Classes, PVCs and Customer Resources and Operators.
However, CSI leaves many core data infrastructure implementation details to vendors and service, such as:
- Data Locality and high availability
- Compliance for GDPR or HIPPA
- Multi-Cloud and Hybrid-Cloud deployments
- Analytics and Visibility into usage for various teams
Thankfully, the extensibility of Kubernetes via the customer resources and operators is enabling a new breed of storage technologies that are Kubernetes native and sometimes called Container Attached Storage (CAS). CAS declaratively manages data services down to the storage device.
Declarative (Composable) Data Services
Depending on the application requirements, a data plane can be constructed using one of the many options available. Kubernetes and containers have helped redefine the way Storage or the Data Plane is implemented.
For example, for distributed applications like Kafka, that has inbuilt replication, rebuilding, capabilities – a Local PV is just what is needed for the Data Plane. To use Local PVs in production, that typically involves provisioning, monitoring and managing backup/migration – data infrastructure engineers just need to enable deploying of the Kubernete native tools like – Operators (that can perform static or dynamic provisioning), Prometheus, Grafana, Jaeger for observability, Velero – for backup/restore.
For another set of applications, there may be a need to deploy a Data Plane that can perform replication – within a cluster, across clusters, across zones/clouds, and snapshots and cloning. By making use of the Customer Resources and Operators, Kubernetes native projects like Rancher, Longhorn and OpenEBS have emerged to combat cloud vendor lock-in for the Kubernetes ecosystem, not only providing a unified experience and tools for managing storage resources on-prem or cloud, but also leveraging and optimizing investments that Enterprises have already made in Legacy storage.
The Next Gen: Declarative Data Plane
With a unified experience and declarative interface to manage the storage/data services, data engineers can interact with Data Infrastructure in a standard way. Building on the CSI foundation, projects like OpenEBS, Velero, standards like KubeMove, SODA Foundation (aka Open Data Autonomy/OpenSDS) are focusing on implementing Easy-To-Use Kubernetes Storage Services for on-prem and cloud and are pushing forward standardization of Declarative Data Plane (aka DDP).
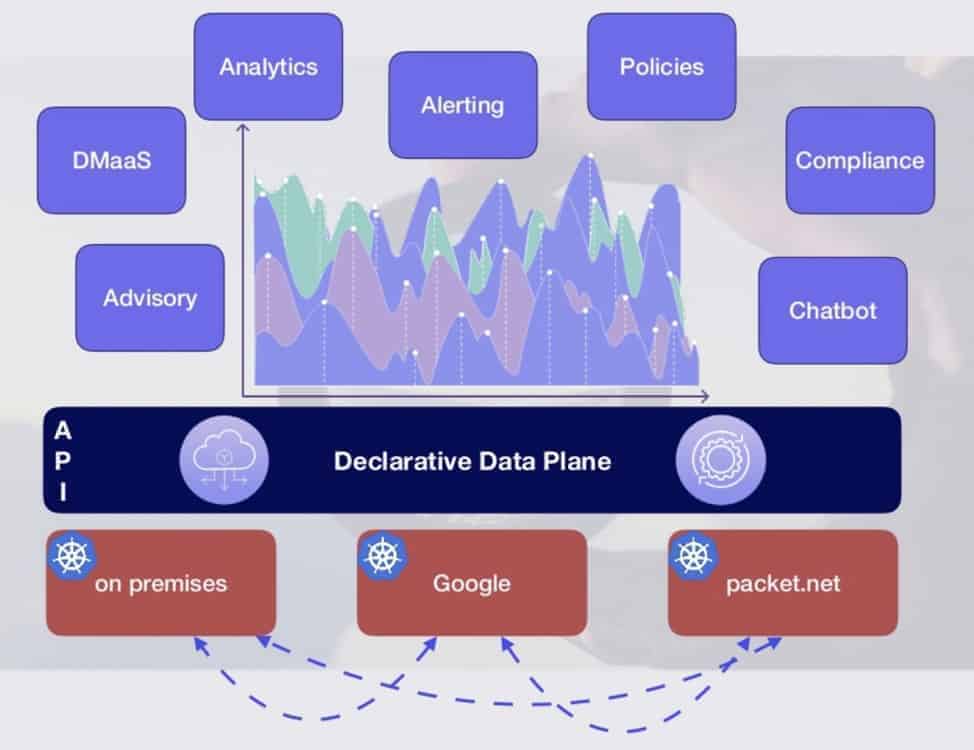
The DDP delivers several architecturally important elements for the next generation of distributed applications’ DataOps:
- Enabling autonomous teams to manage their own storage
- Scalable polyglot big data storage
- Encryption for data at rest and in motion
- Compute and data locality
- Compliance for GDPR or HIPPA
- Multi-Cloud and Hybrid-Cloud deployments
- Backup and Migration
- Analytics and Visibility into usage for various teams
The DDI project is backed by Infrastructure Teams in large Enterprises that have already adopted Kubernetes and are using Kubernetes and projects like OpenEBS to deliver:
- Etcd As a Service
- ElasticSearch As a Service
- PostgreSQL As a Service
- ML pipelines of many types (one promising one is MELTANO from GitHub)
- Kafka as a service
These implementations show that enterprise customers are taking full advantage of the capabilities delivered by a Declarative Data Infrastructure. Such enterprises are leveraging the significant architectural enhancements DDI at the data layer provides to deliver faster, better and competitively-differentiating enterprise analytics. DDI helps with optimal use of the
Infrastructure / Cost Optimization.
Declarative Data Infrastructures are Here to Stay
The declarative (GitOps) approach to managing data infrastructure is here to stay. We recently heard a top executive at a large enterprise say that unless the technology stack is declarative, it is not operable.