
Guest post originally published on the Kublr blog by Oleg Chunikhin
Cloud native and open source technologies have modernized how we develop software, and although they have led to unprecedented developer productivity and flexibility, they were not built with enterprise needs in mind.
A primary challenge is bridging the gap between cloud native and enterprise reality. Enterprises need a centralized Kubernetes management control plane with logging and monitoring that supports security and governance requirements extended through essential Kubernetes frameworks.
But the job doesn’t end with reliable, enterprise-grade Kubernetes clusters. Organizations are also struggling to define new practices around this new stack. They find they must adjust established practices and processes and learn how to manage these new modern applications. Managing roles and permissions is part of that learning process.
Role-based access control (RBAC) is critical, but it can cause quite a bit of confusion. Organizations seek guidance on where to start, what can be done, and what a real-life implementation looks like. In this first blog in a three-part series on Kubernetes RBAC, we’ll provide an overview of the terminology and available authentication and authorization methods. Part two and three will take a deeper dive into authentication and authorization.
RBAC is a broad topic. Keeping practicality in mind, we’ll focus on those methods that are most useful for enterprise users.
What is Kubernetes RBAC?
RBAC or access control is a way to define which users can do what within a Kubernetes cluster. These roles and permissions are defined either through various extensions or declaratively.
If you are familiar with Kubernetes, you already know that there are different resources and subjects. But if this is new to you, here is a quick summary.
Kubernetes provides a single API endpoint through which users manage containers across multiple distributed physical and virtual nodes. Following standard REST conventions, everything managed within Kubernetes is handled as a resource. Objects inside the Kubernetes master server are available through API objects like pods, nodes, config maps, secrets, deployments, etc.
In addition to resources, you also need to consider subjects and operations which are all connected through access control.

Operations and Subjects
Operations on resources are expressed through HTTP verbs sent to the API. Based on the REST URL called, Kubernetes will translate HTTP verbs from incoming HTTP requests into a wider set of operations. For example, while the GET verb applied to a specific Kubernetes object is interpreted as a “get” operation for that object; a GET verb applied to a class of objects in the Kubernetes API is interpreted as a “list” operation. This distinction is important when writing Kubernetes RBAC rules, as we’ll explain that in detail in part three (RBAC 101: Authorization).
Subjects represent actors in the Kubernetes API and RBAC, namely processes, users, or clients that call the API and perform operations on Kubernetes objects. There are three subject categories: users, groups, and service accounts. Technically, only service accounts exist as objects within a Kubernetes cluster API, users and groups are virtual — they don’t exist in the Kubernetes database, but Kubernetes identifies them by a string ID.
When sending an API request to the Kubernetes API, Kubernetes will first authenticate the request by identifying the user and group the sender belongs to. Depending on the authentication and method used, Kubernetes may also extract additional information and represent it as a map of key-value pairs associated with the subject.
Resource versus Non-Resource Requests
The Kubernetes API server adds an additional attribute to the request by tagging it as a resource or a non-resource request. This is necessary because, in addition to operating resources and objects via the Kubernetes API, users can also send requests to non-resource APIs endpoints, such as the “/version” URL, a list of available APIs, and other metadata.
For an API resource request, Kubernetes decodes the API request verb, namespace (in case of a namespaced resource), API group, resource name, and, if available, sub-resource. The set of attributes for API non-resource requests is smaller: an HTTP request verb and request path. The access control framework uses these attributes to analyze and decide whether a request should be authorized or not.
Kubernetes API Request Attributes
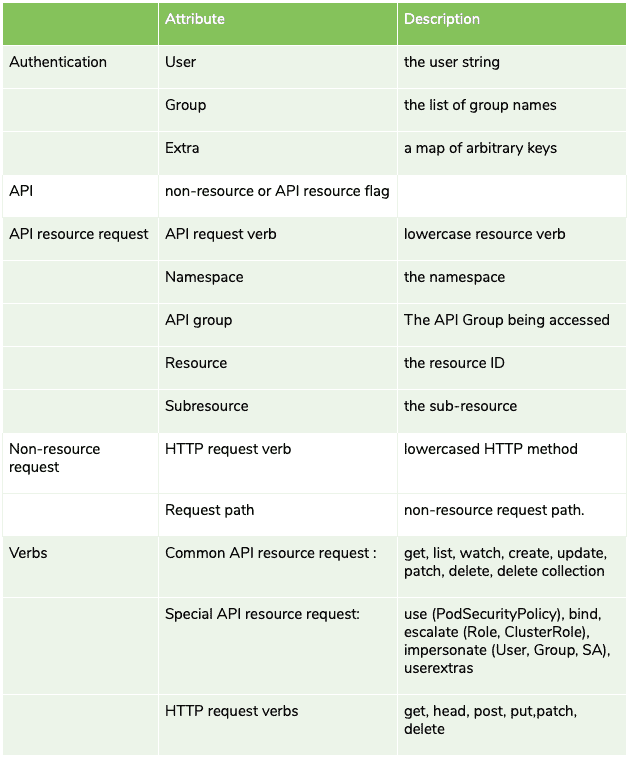
With non-resource requests, the HTTP request verb is obvious. In the case of resource requests, the verb gets mapped to an API resource action. The most common actions are get, list, create, delete. But there are also some less evident actions, such as watch, patch, bind, escalate, and use.
Authentication Methods for Kubernetes
There are a number of authentication mechanisms, from client certificates to bearer tokens to HTTP basic authentication to authentication proxy.
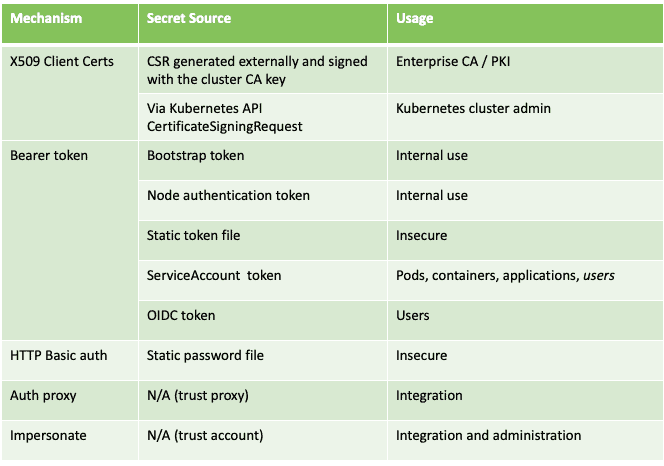
Client certificates. There are two ways to sign client certificates so clients can use them to authenticate their Kubernetes API server requests. One is the manual creation of CSR and signing by an administrator, or signing a certificate through an enterprise certificate authority PKI infrastructure, in which case the external infrastructure signs the client certificates.
Another way that doesn’t require an external infrastructure — although not suitable for large scale deployments — is leveraging Kubernetes, which can also sign client certificates.
Bearer token. There are a number of ways for getting a bearer token. There are bootstrap and node authentication tokens which we won’t cover as they are mostly used internally in Kubernetes for initialization and bootstrapping. Static token files is another option that we won’t discuss because they are considered bad practice and are insecure. The most practical and useful methods are from service accounts and OIDC and we’ll cover that in detail in our next blog.
HTTP basic auth. HTTP basic auth is considered insecure as it can only be done through static configuration files in Kubernetes.
Authentication proxy. Mainly used by vendors, authentication proxies are often applied to set up different Kubernetes architectures. A proxy server processes requests to the Kubernetes API and establishes a trusted connection between the Kubernetes API and proxy. That proxy will authenticate users and clients any way it likes and add user identification into the request headers for requests sent through to the Kubernetes API. This allows the Kubernetes API to know who calls it. Kublr, for example, uses this method to proxy dashboard requests, general web console requests, or provide a proxy Kubernetes API endpoint. Again, if you aren’t a vendor, you don’t really need to worry about this.
Impersonating: If you already have certain credentials providing access to the Kubernetes API, those credentials can be used to “impersonate” users by sending additional headers in the request with the impersonated user identity information. The Kubernetes API will switch your authentication context to that impersonated user based on the headers. Clearly this capability is only available if the “main” user account has permissions to impersonate.
Authorization Methods for Kubernetes
There are a few ways to manage authorization requests in Kubernetes.
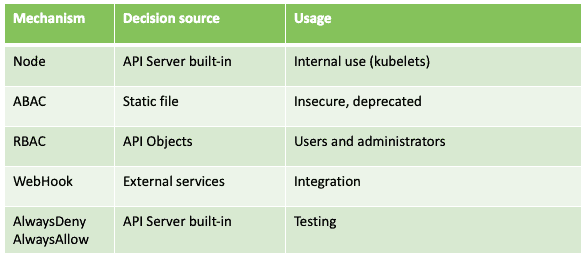
First, we will quickly scan through the methods that you will not see or use in the everyday Kubernetes administrator’s life. ;Node authorization is used internally to authorize kubelet’s API calls, and should never be used by other clients. Authorization methods, such as ABAC and AlwaysDeny / AlwaysAllow are rarely used in real-life clusters: ABAC is based on a static config file and is considered insecure, and AlwaysDeny / AlwaysAllow are generally used for testing and are not approaches you’d use for production deployments.
WebHook is an external service the Kubernetes API can call when it needs to decide whether a request should be allowed or not. The API for this service is well documented in the Kubernetes documentation. In fact, the Kubernetes API itself provides this API. The most common use case for this mechanism is extensions. Extension servers provide authorization webhook endpoints to the API server to authorize access to extension objects.
From a practical standpoint, the most useful authorization method is RBAC. RBAC is based on declarative definitions of permissions stores and managed as cluster API objects. The main objects are roles and cluster roles, both representing a set of permissions on certain objects in the API. These are identified by API groups, source names, and actions performed on those objects. You can have a number of rules within a role or cluster role object.
To properly authorize users in a production grade deployment, it’s important to use RBAC. In the next blogs in this series, we’ll discuss how you can set up and use RBAC.
Conclusion
As we’ve seen, everything managed by Kubernetes is referred to as a resource. Operations on those resources are expressed as HTTP verbs, and subjects are the actors who’ll need to be authenticated and authorized.
There are a few ways to authenticate subjects. Client certificates, bearer tokens, HTTP basic auth, auth proxy, or impersonation (which does require a previous authentication). But only client certificates are a viable option for production deployments. We’ll explore them in more detail in our next blog (Kubernetes RBAC 101: Authentication).
For authorization, you also have a few options. There is ABAC, AlwaysDeny / AlwaysAllow, WebHook, and RBAC. Here too, only one option is viable for external clients in production deployments and that is RBAC. We’ll cover it in detail in part three of this series (Kubernetes RBAC 101: Authorization).
If you’d like to experiment with RBAC, download Kublr and play around with its RBAC feature. The intuitive UI helps speed up the steep learning curve when dealing with RBAC YAML files.