

Guest post originally published on the Alluxio Engineering Blog by Rong Gu, associate researcher at Nanjing University, and Yang Che, is a senior technical expert at Alibaba Cloud, feat. the Alibaba Cloud Container Service Team Case Study
This article presents the collaboration of Alibaba, Alluxio, and Nanjing University in tackling the problem of Deep Learning model training in the cloud. Various performance bottlenecks are analyzed with detailed optimizations of each component in the architecture. Our goal was to reduce the cost and complexity of data access for Deep Learning training in a hybrid environment, which resulted in over 40% reduction in training time and cost.
1. New trends in AI: Kubernetes-Based Deep Learning in the Cloud
Background
Artificial neural networks are trained with increasingly massive amounts of data, driving innovative solutions to improve data processing. Distributed Deep Learning (DL) model training can take advantage of multiple technologies, such as:
- Cloud computing for elastic and scalable infrastructure
- Docker for isolation and agile iteration via containers and Kubernetes for orchestrating the deployment of containers
- Accelerated computing hardware, such as GPUs
The merger of these technologies as a combined solution is emerging as the industry trend for DL training.
Data access challenges of the conventional solutions
Data is often stored in private data centers rather than in the cloud for various reasons, such as security compliance, data sovereignty, or legacy infrastructure. A conventional solution for DL model training in the cloud typically involves synchronizing data between the private data storage and its cloud counterpart. As the size of data grows, the associated costs for maintaining this synchronization becomes overwhelming:
- Copying large datasets: Datasets continually grow, so eventually it becomes infeasible to copy the entire dataset into the cloud, even if copying to a distributed high-performance storage such as GlusterFS.
- Transfer costs: New or updated data needs to be continuously sent to the cloud to be processed. Not only does this incur transfer costs, but it is also costly to maintain because it is often a manually scripted process.
- Cloud storage costs: Keeping a copy of data in the cloud incurs the storage costs of the duplicated data.
A hybrid solution that connects private data centers to cloud platforms is needed to mitigate these unnecessary costs. Because the solution separates the storage and compute architectures, it introduces performance issues since remote data access will be limited by network bandwidth. In order for DL models to be efficiently trained in a hybrid architecture, the speed bump of inefficient data access must be addressed.
2. Container and data orchestration based architecture
A model training architecture was designed and implemented based on container and data orchestration technologies as shown below:
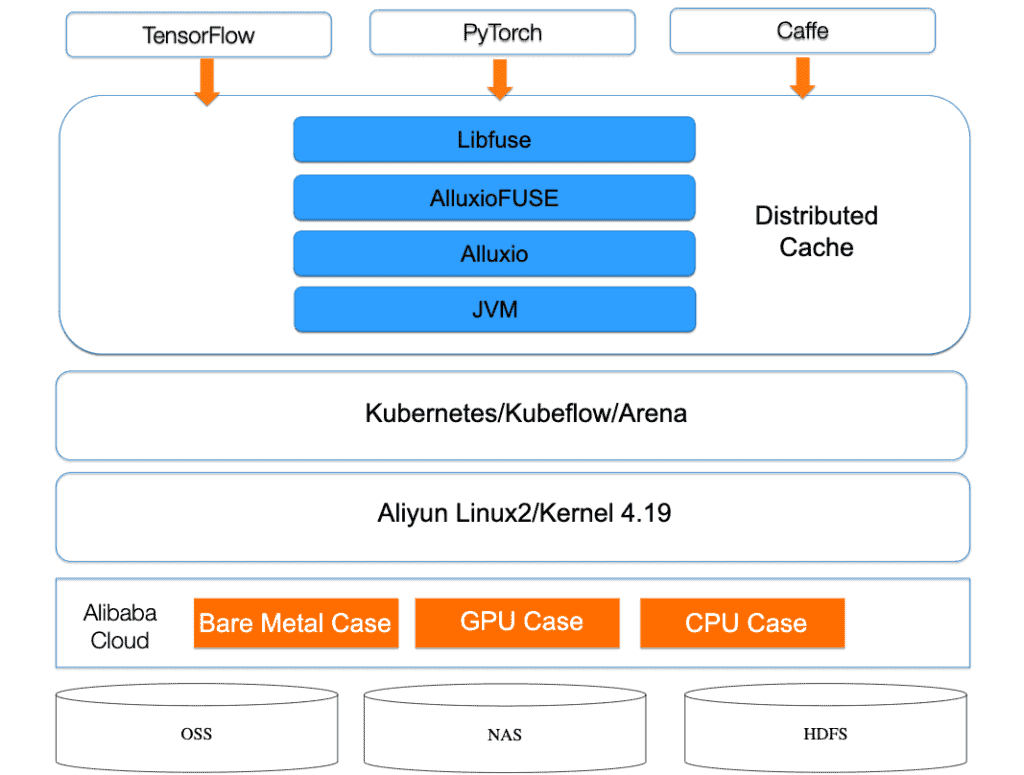
Core components of system architecture
- Kubernetes is a popular container orchestration platform, which provides the flexibility to use different machine learning frameworks through containers and the agility to scale as needed. Alibaba Cloud Kubernetes (ACK) is a Kubernetes service provided by Alibaba Cloud.
- Kubeflow is an open-source Kubernetes-based cloud-native AI platform used to develop, orchestrate, deploy, and run scalable, portable machine learning workloads. Kubeflow supports two TensorFlow frameworks for distributed training, namely the parameter server mode and AllReduce mode.
- Alluxio is an open-source data orchestration system for hybrid cloud environments. By adding a layer of data abstraction between the storage system and the compute framework, it provides a unified mounting namespace, hierarchical cache, and multiple data access interfaces. It is able to support efficient data access for large-scale data in various complex environments, including private, public, and hybrid cloud clusters.
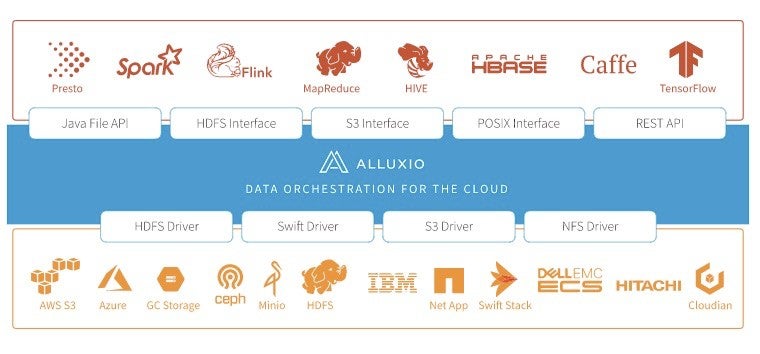
Recently introduced features in Alluxio have further cemented its utility for machine learning frameworks. A POSIX filesystem interface based on FUSE provides an efficient data access method for existing AI training models. Helm charts, jointly developed by the Alluxio and Alibaba Cloud Container Service teams, greatly simplify the deployment of Alluxio in the Kubernetes ecosystem.
3. Training in the Cloud
Initial Performance
In the performance evaluation using the ResNet-50 model, we found that upgrading from Nvidia P100 to Nvidia V100 resulted in a 3x improvement in the training speed of a single card. This computing performance improvement puts additional pressure on data storage access, which also poses new performance challenges for Alluxio’s I/O.
This bottleneck can be quantified by comparing the performance of Alluxio with a synthetic data run of the same training computation. The synthetic run represents the theoretical upper limit of the training performance with no I/O overhead since the data utilized by the training program is self-generated. The following figure measures the image processing rate of the two systems against the number of GPUs utilized.
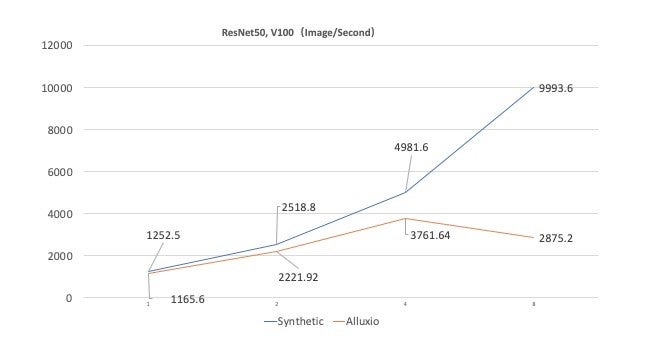
Initially, both systems perform similarly but as the number of GPUs increases, Alluxio noticeably lags behind. At 8 GPUs, Alluxio is processing at 30% of the synthetic data rate.
Analysis and Performance Optimization
To investigate what factors are affecting performance, we analyzed Alluxio’s technology stack as shown below, and identified several major areas of performance issues. For a complete list of optimizations we applied, please refer to the full-length whitepaper.
Filesystem RPC overhead
Alluxio file operations require multiple RPC interactions to fetch the requested data. As a virtual filesystem, its master processes manage filesystem metadata, keeps track of where data blocks are located, and fetch data from underlying filesystems.
Solution:
We reduced this overhead by caching metadata and not allowing the cache to expire throughout the duration of the workload by setting alluxio.user.metadata.cache.enabled to true. The cache size and expiration time, determined by alluxio.user.metadata.cache.max.size and alluxio.user.metadata.cache.expiration.timerespectively should be set to keep the cached information relevant throughout the entire workload. In addition we extend the heartbeat interval to reduce the frequency of worker updates by setting the property alluxio.user.worker.list.refresh.interval to be 2 minutes or longer.
Data caching and eviction strategies
As Alluxio reads data from the underlying storage system, the worker will cache data in memory. As the allocated memory fills up, it will choose to evict the least recently accessed data. Both of these operations are asynchronous and can cause a noticeable overhead in data access speeds, especially as the amount of data cached on a node nears saturation.
We configured Alluxio to avoid evicting data and disabled features that would cache duplicate copies of the same data. By default, Alluxio caches data read from the underlying storage system, which is beneficial for access patterns where the same data is requested repeatedly. However, DL training typically reads the entire dataset, which can easily exceed Alluxio’s cache capacity as datasets are generally on the order of terabytes. We can tune how Alluxio caches data by setting alluxio.user.ufs.block.read.location.policy to alluxio.client.block.policy.LocalFirstAvoidEvictionPolicy, which will avoid evicting data to reduce the load on each individual worker, and setting alluxio.user.file.passive.cache.enabled to false to avoid caching additional copies.
Alluxio and FUSE configuration for handling numerous concurrent read requests
Reading files through the FUSE interface is fairly inefficient using its default configuration. FUSE reads are handled by the libfuse non-blocking thread pool that does not necessarily recycle its threads. The thread pool is configured with max_idle_threads hardcoded to a value of 10. When this value is exceeded, threads will be deleted instead of recycled.
Solution:
Because libfuse2 does not expose the value of max_idle_threads as a configuration value, we patched its code to be able to configure a much larger value to better support more concurrent requests.
Impact of running Alluxio in containers on its thread pool
Running Java 8 in a containerized environment may not fully utilize a machine’s CPU resources due to how the size of thread pools is calculated.
Solution:
Before patch 191 for Java 8, thread pools would be initialized with a size of 1, which severely restricts concurrent operations. We can set the number of processors directly by setting the Java flag -XX:ActiveProcessorCount.
Results
After optimizing Alluxio, the single-machine eight-card training performance of ResNet50 is improved by 236.1%. The performance gains are reflected in the four-machine eight-card scenario with a performance loss of 3.29% when compared against the synthetic data measurement. Compared to saving data to an SSD cloud disk in a four-machine eight-card scenario, Alluxio’s performance is better by 70.1%.
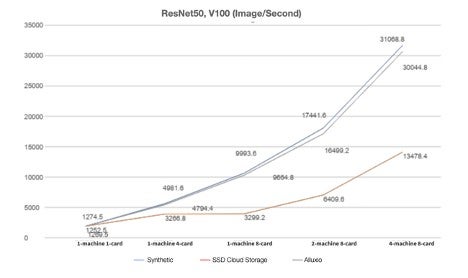
The total training time of the workload takes 65 minutes when using Alluxio on four machines with eight cards each, which is very close to the synthetic data scenario that takes 63 minutes.
Compared with training via SSD on the cloud, Alluxio saves 45 minutes in time and 40.9% in costs.
4. Summary and future work
In this article, we present the challenges of using Alluxio in a high-performance distributed deep learning model training and dive into our work in optimizing Alluxio. Various optimizations were made to improve the experience of AlluxioFUSE performance in high concurrency reading workload. These improvements enabled us to achieve a near-optimal performance when executing a distributed model training scheme in a four-machine eight-card scenario with ResNet50.
For future work, Alluxio is working on enabling page cache support and FUSE layer stability. Alibaba Cloud Container Service team is collaborating with both the Alluxio Open Source Community and Nanjing University through Dr. Haipeng Dai and Dr. Rong Gu. We believe that through the joint effort of both academia and the open-source community, we can gradually reduce the cost and complexity of data access for Deep Learning training when compute and storage are separated to further help advance AI model training on the cloud.
5. Special Thanks
Special thanks to Dr. Bin Fan, Lu Qiu, Calvin Jia, and Cheng Chang from the Alluxio team for their substantial contribution to the design and optimization of the entire system. Their work significantly improved the metadata cache system and advanced Alluxio’s potential in AI and Deep Learning.
Authors:
Yang Che, Sr. Technical Expert at Alibaba Cloud. Yang is heavily involved in the development of Kubernetes and container related products, specifically in building machine learning platforms with cloud-native technology. He is the main author and core maintainer of GPU shared scheduling.
Rong Gu, Associate Researcher at Nanjing University and core maintainer of the Alluxio Open Source project. Rong received a Ph.D. degree from Nanjing University in 2016 with a focus on big data processing. Prior to that, Rong worked on R&D of big data systems at Microsoft Asia Research Institute, Intel, and Baidu.