
Guest post originally published on Bitnami by Juanjo Ciarlante
Introduction
Kubernetes, like any other secure system, supports the following concepts:
- Authentication: Verifying and proving identities for users and groups, and service accounts
- Authorization: Allowing users to perform specific actions with Kubernetes resources
- Accounting: Storing subjects actions, typically for auditing purposes
Authorization – the process of handling users’ access to resources – is always a challenge, especially when access is to be controlled by either team membership or project membership. Two key challenges are:
As Kubernetes group membership is handled externally to the API itself by an Identity Provider (IdP), the cluster administrator needs to interact with the Identity Provider administrator to setup those group memberships, making the workflow potentially cumbersome.Identity Providers may not provide group membership at all, forcing the cluster administrator to handle access on a per-user basis, i.e. Kubernetes RoleBindings containing the “full” list of allowed end-users.
In this tutorial, we propose a way to “mimic” group memberships – which can be either by team, project or any other aggregation you may need – using stock Kubernetes authorization features.
Assumptions and prerequisites
This article assumes that you:
- Have some knowledge about general end-user security concepts
- Have some knowledge and experience with RBAC roles and bindings
- Understand the difference between authentication and authorization
- Configure your clusters with Kubernetes RBAC enabled, default since 1.6 release
Overview of Kubernetes authentication
Authentication is a key piece of the strategy that any cluster administrator should follow to secure the Kubernetes cluster infrastructure and make sure that only allowed users can access it.
Here is a quick recap on how Kubernetes approaches authentication. There are two main categories of users:
- ServiceAccounts (SAs):
- The ID is managed in-cluster by Kubernetes itself.
- Every ServiceAccount has an authentication token (JWT) which serves as its credential
- Users (external Personas or Bot users).
- The ID is externally provided, usually by the IdP. There are many mechanisms to provide this ID, such as:
- x509 certs
- Static token or user/password files
- OpenID Connect Tokens (OIDC) via an external Identity Provider (IdP)
- Webhook tokens
- Managed Kubernetes providers (e.g. GKE, AKS, EKS) integrated with their own Cloud authentication mechanisms
- The ID is externally provided, usually by the IdP. There are many mechanisms to provide this ID, such as:
The user ID is included in every call to the Kubernetes API, which in turn is authorized by access control mechanisms.
It’s common to adopt OIDC for authentication as it provides a Single-Sign-On (SSO) experience, although some organizations may still use end-users x509 certs as these can be issued without any external IdP intervention. However, these common approaches present the following challenges:
- x509 certs: Although they may be easy to setup, users end up owning an x509 bundle (key and certificate) that cannot be revoked. This forces the cluster owner to specify low expiration times, obviously depending on staff mobility. Additionally, the user’s Group is written into the x509 certificate itself. This forces the cluster administrator to re-issue the certificate every time the user changes membership, while being unable to revoke the previous certificate (i.e. the user will continue to remain a member of older groups until the previous certificate expires).
- OIDC authentication: This method is convenient to provide SSO using the IdP in use by the organization. The challenge here arises when the provided identity lacks group membership, or group membership (as setup by the organization) doesn’t directly map to users’ team or project memberships regarding their Kubernetes workloads needs.
With the user now authenticated, we need to take a look at how we authorize them to use the Kubernetes Cluster.
Overview of Kubernetes Authorization and RBAC
There are many resources on the web regarding Kubernetes RBAC. If you are not fully familiar with these concepts, I recommend this great tutorial on demystifying RBAC in Kubernetes. To learn more about how to configure RBAC in your cluster, check out this tutorial. Kubernetes RBAC enables specifying:
A) SUBJECTS who are allowed to B) do VERBS on RESOURCE KINDS (optionally narrowed to specific RESOURCE NAMES)
In the above model, B) is implemented as a Kubernetes Role (or ClusterRole), while A) -> B) binding is modeled as a Kubernetes RoleBinding (or ClusterRoleBinding), as per below example diagram:
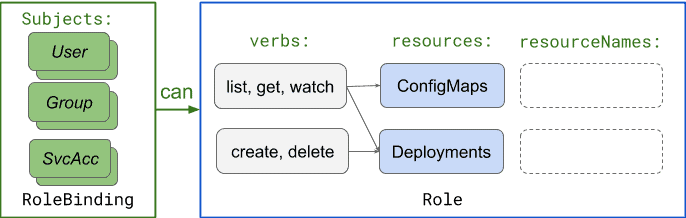
Using impersonated “virtual-users” to control access
Kubernetes RBAC includes a special impersonate verb, that can be used to allow Subjects (i.e. Users, Groups, ServiceAccounts) to acquire other Kubernetes User or Group identity.
As these acquired identities do not necessarily need to exist – recall that the Kubernetes control plane itself doesn’t have a Users or Groups store – we will call them “virtual-users” in this article. This feature enables setting up “virtual-users” as “role accounts” security Principals. For example:
- alice@example.com, as member of the Application Frontend (app-fe) team can impersonate app-fe-user virtual-user
- bob@example.com, as member of the Application Backend (app-be) team can impersonate app-be-user virtual-user
RBAC rules can be created to allow such “virtual-users” to access the Kubernetes resources they need, as per below diagram:
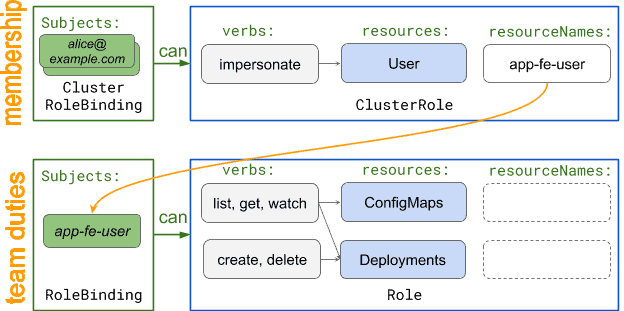
As shown above, using stock Kubernetes RBAC features, authorization handling is divided into:
- team membership: RBAC ClusterRoles and ClusterroleBindings that state Users who are allowed to impersonate their team’s virtual-user.
- team duties: RBAC Roles and RoleBindings that state which actual Kubernetes resources the team’s virtual-user can access.
The actual impersonate action is specified via headers in the Kubernetes API call, which is conveniently implemented by kubectl via:
kubectl --as <user-to-impersonate> ...
kubectl --as <user-to-impersonate> --as-group <group-to-impersonate> ...
Tip: kubectl –as-group … without the –as parameter is not valid. To simplify the CLI usage, this article proposes using the first form above, by modeling the user-to-impersonate as a “virtual-user” representing the user group or team memberships.
Following the example shown in the previous diagram, the User “alice@example.com” can easily impersonate virtual team-user “app-fe-user” by overloading kubectl CLI using the command below:
kubectl --as app-fe-user ...
A working example with RBAC rules
Now that virtual users have been “created”, let’s see a working example of the RBAC rules in practice. For this use case, assume the following scenario:
- Users alice@example.com and alanis@example.com have been authenticated by some form of SSO (e.g. OIDC connector to Google IdP).
- They are members of the app-fe (i.e. Application Frontend) team.
- The Kubernetes cluster has three namespaces (NS) relevant to app-fe workloads: development, staging, and production.
- A virtual-user named app-fe-user will be created, allowing Alice and Alanis to impersonate it.
- The app-fe-user will be granted the following access:
- dev-app-fe NS: full admin
- staging-app-fe NS: edit access
- prod-app-fe NS: only view access
Tip: For the sake of simplicity, we will use stock Kubernetes ClusterRoles (usable for namespace scoped RoleBindings) to implement the above access rules.
Step 1: Prepare the RBAC manifests
The example below implements the idea, using k14s/ytt as the templating language (you can find below the ytt source code and resulting manifested YAML here):
#@ load("impersonate.lib.yml",
#@ "ImpersonateCRBinding", "ImpersonateCRole", "RoleBinding"
#@ )
https://github.com/k14s/ytt
#@ members = ["alice@example.com", "alanis@example.com"]
#@ prod_namespace = "prod-app-fe"
#@ stag_namespace = "staging-app-fe"
#@ dev_namespace = "dev-app-fe"
#@ team_user = "app-fe-user"
#! Add impersonation bindings <members> -> team_user
--- #@ ImpersonateCRBinding(team_user, members)
--- #@ ImpersonateCRole(team_user)
#! Allow *team_user* virtual-user respective access to below namespaces
--- #@ RoleBinding(team_user, prod_namespace, "view")
--- #@ RoleBinding(team_user, stag_namespace, "edit")
--- #@ RoleBinding(team_user, dev_namespace, "admin")
The resulting YAML output can be pushed via kubectl as usual executing the following command:
$ ytt -f . | kubectl apply -f- [ --dry-run=client ]
Warning
User Identity (“alice@example.com” in this example) may be provided by any authentication mechanism discussed at the beginning of this article.
Step 2: Test the setup
After pushing above RBAC resources to the cluster, alice@example can use the kubectl auth can-i … command to verify the setup. For example:
$ kubectl auth can-i delete pod -n dev-app-fe
no
$ kubectl --as app-fe-user auth can-i delete pod -n dev-app-fe
yes
$ kubectl --as foo-user auth can-i get pod
Error from server (Forbidden): users "foo-user" is forbidden: User "alice@example.com" cannot impersonate resource "users" in API group "" at the cluster scope
This totally feels like sudo for Kubernetes, doesn’t it?
Step 3: Save the impersonation setup to your Kubernetes config file
To have the configuration pre-set for impersonation, there are some not-so extensively documented fields that can be added to the “user:” entry in the user’s KUBECONFIG file:
- name: alice@example.com@CLUSTER
user:
as: app-fe-user
auth-provider:
config:
client-id: <...>.apps.googleusercontent.com
client-secret: <...>
id-token: <... JWT ...>
idp-issuer-url: https://accounts.google.com
refresh-token: 1//<...>
name: oidc
This persistent setup is useful as it avoids the need to:
- provide –as … argument to kubectl on each invocation
- require other Kubernetes tools to support impersonation, e.g. helm is a notable example lacking this feature
Audit trails
Kubernetes impersonation is well designed regarding audit trails, as API calls get logged with full original identity (user) and impersonated user (impersonatedUser). The following snippet shows a kube-audit log trace entry, as triggered from kubectl –as app-fe-user get pod -n dev-app-fe:
{
"kind": "Event",
"apiVersion": "audit.k8s.io/v1",
"level": "Request",
"auditID": "032beea1-8a58-434e-acc0-1d3a0a98b108",
"stage": "ResponseComplete",
"requestURI": "/api/v1/namespaces/dev-app-fe/pods?limit=500",
"verb": "list",
"user": {
"username": "alice@example.com",
"groups": ["system:authenticated"]
},
"impersonatedUser": {
"username": "app-fe-user",
"groups": ["system:authenticated"]
},
"sourceIPs": ["10.x.x.x"],
"userAgent": "kubectl/v1.18.6 (linux/amd64) kubernetes/dff82dc",
"objectRef": {
"resource": "pods",
"namespace": "dev-app-fe",
"apiVersion": "v1"
},
"responseStatus": {
"metadata": {},
"code": 200
},
"requestReceivedTimestamp": "2020-07-24T21:25:50.156032Z",
"stageTimestamp": "2020-07-24T21:25:50.161565Z",
"annotations": {
"authorization.k8s.io/decision": "allow",
"authorization.k8s.io/reason": "RBAC: allowed by RoleBinding \"rb-app-fe-user-admin\" of ClusterRole \"admin\" to User \"app-fe-user\""
}
}
Picky readers will also note that the “user” field above has only “username” relevant to the User identity, as “system:authenticated” is obviously a generic group value.
Conclusion
By using stock Kubernetes RBAC features, a cluster administrator can create virtual user security Principals which are impersonated by Persona Users, to model “role-account” authorization schemes. This approach provides numerous benefits related to the Kubernetes security configuration, as follows:
- It requires the authentication mechanism to only provide User identity data (i.e. no Group needed).
- It allows the Kubernetes cluster administrator to build team membership schemes using the stock Kubernetes RBAC impersonate feature.
- It allows the Kubernetes cluster administrator to create RBAC rules to access Kubernetes Resources against these impersonated “virtual-users” (Kubernetes Rolebinding “subjects”, usually just a single entry).
- It decouples membership from actual resource access rules which allows creating cleaner RBAC entries. Such entries are easier to maintain and audit, reducing complexity and workload for cluster administrators.
- It benefits the Organization as the cluster administrator can more precisely implement team and project controls, easing staff on/off boarding and related security aspects.