Guest post by Fred Chien (錢逢祥)from BroBridge
Express train for digital transformation of the financial industry: Building a data middle platform
Not just the financial industry, almost all companies have their digital core systems in different types. These long-existing systems are not only the lifeblood of the company but also a significant burden under the digital transformation. When facing the rapidly changing of external demands, business transformation, and even many digital needs, the applicability of existing core systems is gradually being challenged, causing all companies to seek ways to transform.
It is not easy to transform the core system, which is more realistic to start from the perspective of “strengthening.” How to use microservice technology to transform the middle platform system and achieve the purpose of strengthening the core is our concern.
Of course, we are more concerned about how to quickly and painlessly introduce microservice technology to achieve this goal.
The ordeal with a digital system for open banking
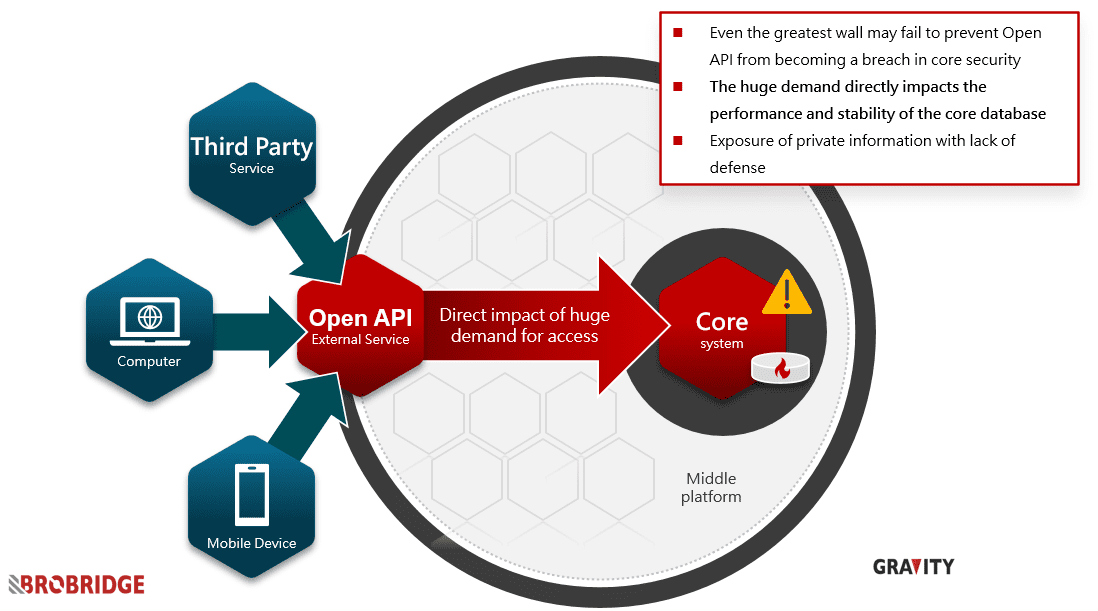
When the entire society and business environment are undergoing a digital transformation, open banking development is bound to advance vigorously—accompanied by rising business volume, a sharp increase in external digital connection demand, and massive data exchange. Regardless of the challenges that other systems will face, the core database will be the first to bear the brunt and face huge access pressure under the traditional architecture, leading to the priority collapse of data-related services.
Due to the physical limitations of the hardware and software architecture, a single database’s performance has its limits. In addition to time-consuming and labor-intensive, it also costs a lot of money to get a slight performance improvement. That is an ultimate issue for all enterprises.
Besides, the original data and status of the core system are particularly important. If any external connection can affect the core operation, except for performance and stability issues, data security is a big problem.
Build-up the line of defense for secured data: Metadata design
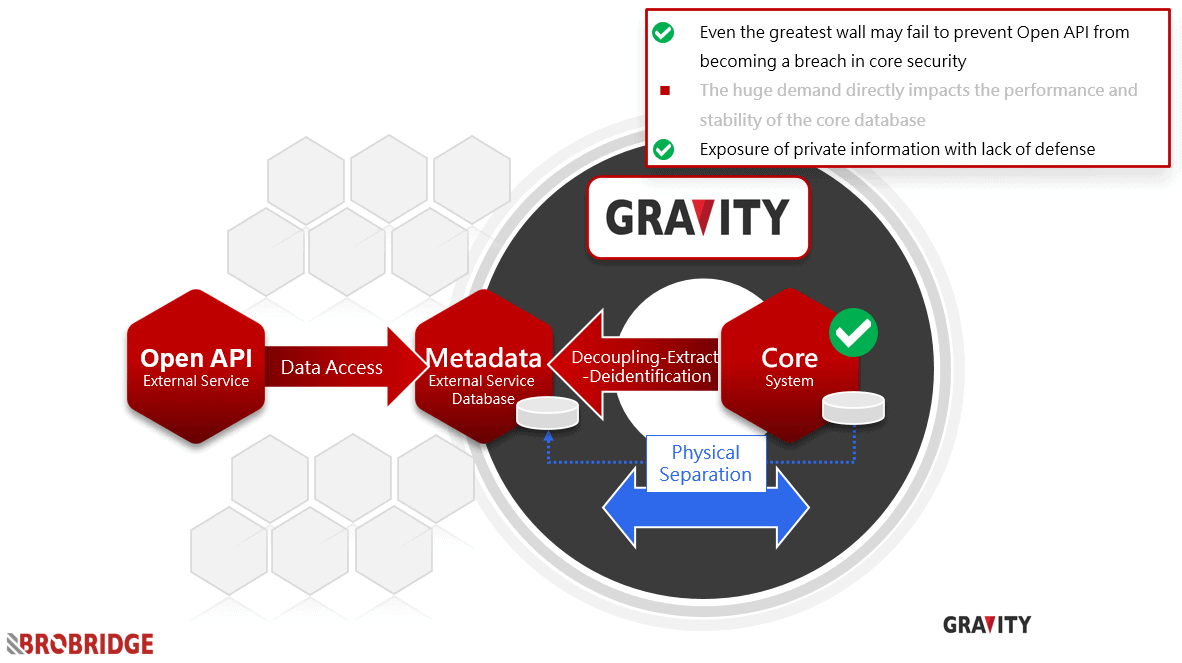
If we want to avoid all data requirements from directly penetrating the core database system, the best way is: Not touching the core system directly. Thus, it is an excellent solution to establish a security line of defense for data using CQRS technology, which is often mentioned in the microservice architecture.
You need to implement several things to build-up a data security line of defense:
- Data extraction (select only necessary data)
- Filtering and aggregation (filter sensitive information, reduce data dimensions, reduce query complexity)
- Create a metadata database (create a cache dynamically)
As long as the conventional CQRS design and tools are introduced, data extraction’s granularity can reach the “column” level. Only extract the required fields without copying the entire database or table, which dramatically reduces the data size and achieves better data cache efficiency.
Once implemented the metadata database design, all external query requirements will no longer link to the core database directly. Because the metadata database’s multiple views design is established, the data dimensions have been optimized for specific needs. Disassociation reduces the complexity of the query and provides the most efficient query.
In terms of security, because only necessary data has been de-identified and deleted for sensitive information during filtering and aggregation, the importance of the data stored in the metadata database has been minimized. Even if it is invaded or destroyed, it can ensure the loss control at a minimum range.
Regarding the increase in data throughput, although database query performance receives the best improvement by data aggregation, the database still may not withstand the pressure when faced with huge demands. In this case, we can implement a copying mechanism for the metadata database to create multiple copies: “traditional read-write separation” such as Replication or CDC.
Improve performance with scalable data middle platform
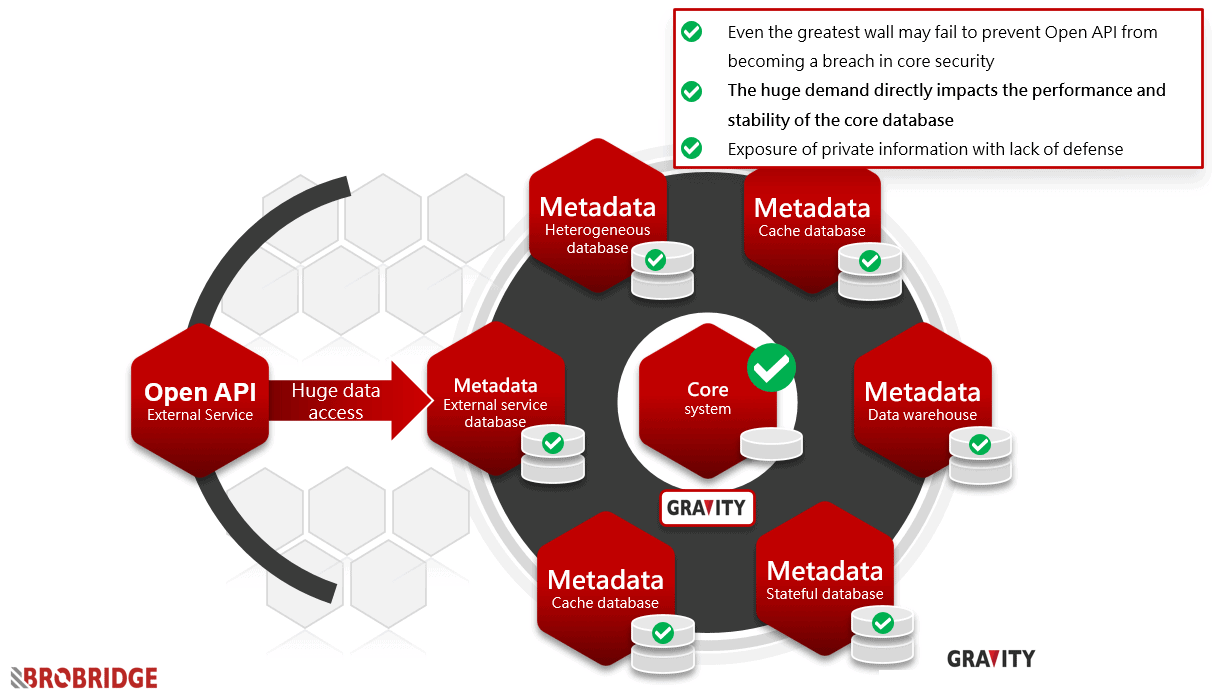
When stored each application requirement out to a different corresponding metadata database, the so-called database per service design in the microservice architecture can be indirectly realized, and these metadata databases form a large-scale data middle platform.
Through the microservice technology introduction mode, every external demand process has already fulfilled the service splitting and design method unknowingly and realizing horizontal expansion or agile development requirements.
Besides, after realizing the data middle platform and getting used to this form, the core requirements will gradually withdraw from the first-line application scenarios except for key transactions. The agility and new business requirements required for digital transformation will no longer treat the core system and its original database as a bottleneck or burden.
Note: At the next step, we can start with metadata’s design to discuss the data ownership, carry out the microservice aggregation design. Then achieve the decentralized data management goal, and implement the microservice architecture truly.
Further CQRS application scenarios
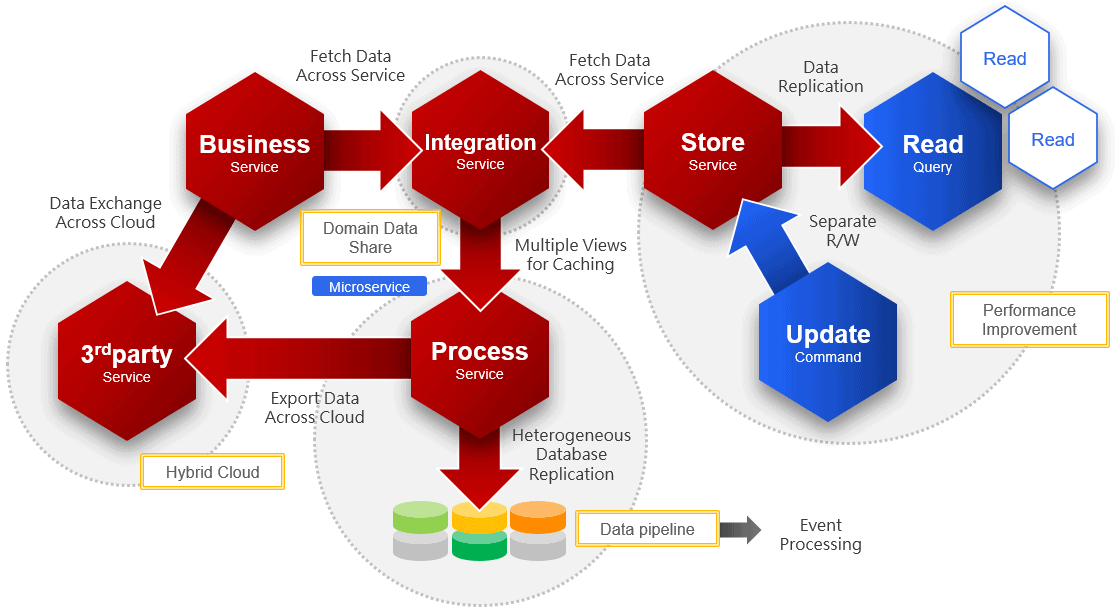
The introduction of CQRS can achieve many things. Not only the performance optimization to be completed by “traditional read-write separation,” if the granularity is achieved in the column and event-level, and then the application-level design is integrated, the needs of heterogeneous databases can also be achieved. In particular, due to data extraction, filtering, and aggregation, data sets’ size and sensitivity are significantly reduced, making them suitable to be transferred to third-party and different cloud systems to increase the possibility of hybrid cloud integration.
Note: If you want to fully implement these application scenarios or even use CQRS to implement the microservice architecture, the support and customizability of the application layer’s CQRS mechanism are important. It is no longer just a traditional simple Replication or CDC that can meet the needs. Please keep this in mind.
The realization of CQRS needs to be faster and faster!
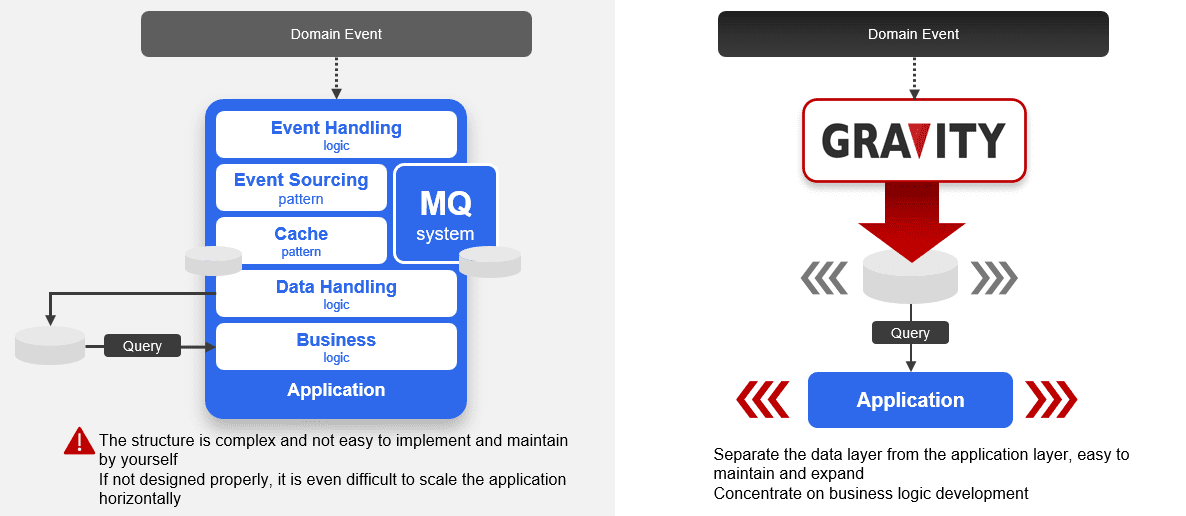
Based on experience, the introduction of CQRS from the perspective of caching is the most painless and rapid method, and it also opens a gap for the challenging microservice architecture. From the data sorting and planning, future microservice architecture is formed gradually. However, to achieve these goals successfully and face a large number of application requirements, the deployment of the CQRS mechanism must be “fast, ruthless and accurate,” and even fully automated.
Fortunately, in the era of Cloud Native, deploying CQRS can be a speedy task. As long as the solution introduced is correct and the planning direction is right, implementing a CQRS mechanism and creating new metadata can usually be done within a few minutes. The application does not even need to be rebuilt on a large scale. Even in the face of hundreds of new application requirements, it may only be a matter of workdays.
Note: Without large-scale transformation, rapid decoupling of data, meeting performance requirements, and agile response to business model changes, under these premises, is the correct posture to introduce microservice architecture and strengthen core systems.
—
The source of information in this article is based on the practical experience of Brobridge, as well as the microservice architecture design training course and Gravity solution description. If you want to know more about the microservice architecture design and CQRS issues, you can contact us. If you want to import the “Data Cache Platform” to lay a solid foundation for your microservice introduction road and also prepare for the future “Data Center” and “Data Relay Platform,” you are welcomed to contact us.