


KubeCon + CloudNativeCon NA Virtual sponsor guest post from Josh Berkus, Red Hat
Does Cloud Native technology replace older DevOps tools, like Kubernetes replacing configuration management? Or does it supplement it instead? Replacement is a popular narrative, but it’s much more effective to use the new technologies to enhance and rebuild the older ones. In our case, we’re going to explain how we use Kubernetes, CloudEvents, and Knative to make Ansible more scalable, distributed, and effective.
In order to understand this approach, though, you’re going to have to first move away from popular ideas about what Serverless is.
Serverless: More than FaaS
For the most part, Serverless is seen as Function as a Service (FaaS). While it is definitely true that most Serverless code being implemented today is FaaS, that’s not the destination, but the pitstop. The Serverless space is still evolving. Let’s take a journey and explore how far Serverless has come, and where it is going.
Our industry started with what I call “Phase 1.0”, when we just started talking or hearing about Serverless, and for the most part just thought about it as Functions – small snippets of code running on demand and for a short period of time. AWS Lambda made this paradigm very popular, but it had its own limitations around execution time, protocols, and poor local development experience.
Since then, more people have realized that the same serverless traits and benefits could be applied to microservices and Linux containers. This leads us into what I’m calling the “Phase 1.5”. Some solutions here completely abstract Kubernetes, delivering the serverless experience through an abstraction layer that sits on top of it, like Knative. By opening up Serverless to containers, users are not limited to function runtimes and can now use any programming language they want. They can also leverage the portability of containers and move workloads around, breaking the lock-in of the cloud providers.
But the destination of our journey is when we evolve Serverless implementation to handle more complex orchestration and integration patterns, combined with some level of state management. For the most part, Serverless means stateless applications, but many solutions are now being created to help with orchestration to re-create well-known integration patterns, but serverlessly. Also, when we achieve this “phase 2.0”, Serverless becomes essentially another feature of your platform as a service, since in practice most enterprises will be running a combination of serverless and non serverless workloads. Microservices, monoliths or functions, all running as containers, giving our customers the ability to choose the best tool for the job, when needed.
What’s the core of this Phase 2.0 Serverless? Events and Eventing. At its most simple form, a task needs to be performed when a request comes in. Thinking in terms of events and actions reveals a much broader opportunity to use Serverless approaches to evolve your infrastructure and applications. This is the drive for moving to Event-Driven Automation (EDA), which handles the elasticity, scale, and responsiveness of clouds much better than prior models. EDA is at the heart of Serverless, request-driven scaling of applications/functions with the robust infrastructure to produce and consume events.
DevOps: More than Configuration
Just as Serverless is often misleadingly portrayed as just FaaS, DevOps automation platforms like Ansible are often mistakenly defined as being completely about configuration management. People forget that a core goal of DevOps is automating tasks formerly done by humans to make them repeatable and scalable, and that automation is much bigger than configuration management. So while you certainly can use tools like Ansible to manage configurations, they are capable of doing a much broader universe of automatable tasks. “Automate everything” is the project mantra.
Once you start thinking of DevOps platforms as automation tools, their continued applicability in the era of Cloud Native becomes much more obvious. While we may have changed completely how we handle configurations, we have not lost the need to manage and interact with hardware, networks, external systems, third-party APIs, and security policies. And traditional DevOps tools already have modules to handle all of those things, while new Cloud Native tools often don’t.
Event-Driven Automation
This shows us some clear integration points between the old automation and the new serverless. Serverless platforms listen for, and route, events; automation platforms take commands or state declarations, and perform work. At its most simple form, a task needs to be performed when a request comes in. This is the drive towards moving to Event Driven Architecture and it turns out that many unprecedented challenges can be solved by EDA. It makes the elasticity and scale of distributed applications possible to manage.
As an example of this, we can set up a queue to process CloudWatch events from our AWS account. Events generated by SQS data feed for CloudWatch gets translated into CloudEvents by the Knative event source and these CloudEvents in turn can be pulled in via a queue to Knative on Kubernetes.
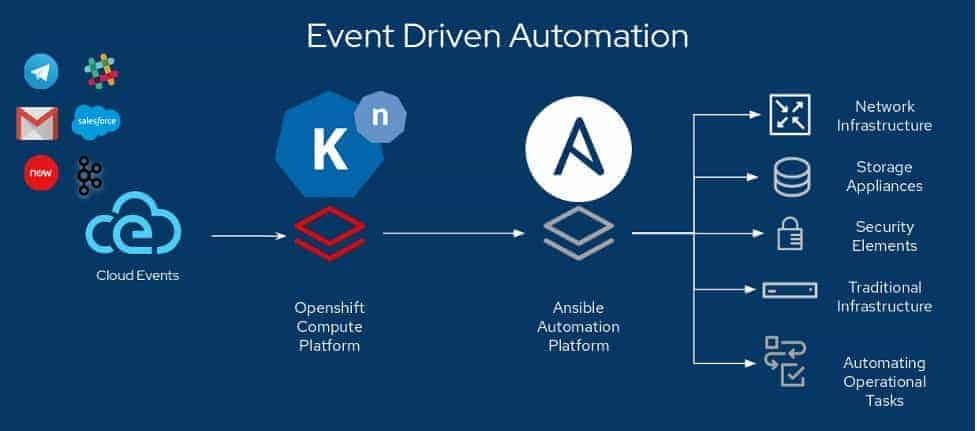
This pipeline allows the workflow to get automatically triggered based on events in the platform, such as having certain network events, or autoscaling to more than a certain number of nodes, kick-off automated reconfiguration of the load balancer. You could also apply team policies to creating new VPCs or VMs, and alert someone or automatically delete them if they are created with an inadequate configuration.
Using the technologies and standards demonstrated here, workflow automation can be achieved from multiple clouds or on-premises platforms, and you get to pick where you want to process those events. For example, you could use it to spin up resources on one public cloud or data center if you have the capacity or access problems on another. Developers could even use it to implement ChatOps.
There are some simple examples of setting up and using Serverless with Knative, and Ansible in this repository and this one.
Imagine:
- support cases already having all the required information for engineers to begin troubleshooting immediately
- dynamic documentation, where the information you have is accurate exactly when you need it
- seamless integration with all your infrastructure, combine the best of your container and traditional environments
- self healing infrastructure, where events kick of troubleshooting Ansible Playbooks that rectify issues without human intervention
Hopefully, we’ve helped you understand what’s possible if you fuse new cloud-native tech and older DevOps tech into a single Event-Driven Architecture. It’s possible to take advantage of new capabilities without discarding your investments in existing automation. Just expand your thinking beyond functions and configurations, and start scaling your automation now.
Links:
Knative-Ansible Github Projects: https://github.com/IPvSean/ansible_aws_report and https://github.com/markito/knative-ansible
Getting Started guide: https://developers.redhat.com/products/ansible/getting-started
Serverless : https://developers.redhat.com/topics/serverless-architecture
Cloud Events Project: https://cloudevents.io/