Guest post originally published on Softax’s blog by Piotr Martyniuk, solution architect at Softax
Microservices can be combined in various ways. What are the advantages and disadvantages of individual approaches and what techniques should be used to make the constructed solution work efficiently, be resistant to failures and not cause difficulties in development and maintenance?
The article consists of three parts:
- Part 1 Types of communication (present)
- Part 2 Patterns of problem handling (published soon)
- Part 3 Logical Architecture (published next)
The first part (this one) describes the technical methods of communication between individual modules in the solution, the second part presents various design patterns for handling connection problems, and the third part presents logical ways of connecting components within the system architecture.
Why separate components at all?
Collaboration within the solution of small, independent and isolated modules is the core of the microservice architecture. As the system grows, simple monolithic architectures, where the presentation is closely linked to the database are no longer sufficient. There is a need to divide the system into dedicated modules that can be developed separately, separately delivered, run, managed and scaled.
Microservices – strengths and weaknesses: Part 1 Small modules – more about microservices as a set of separate modules.
In any case, separate components, in practice separate processes, have to be connected somehow – i.e. allowed to communicate with each other and exchange data. The ways of such communication and the related techniques are described later in the article.

How can microservices communicate
Let us assume here that as modules we understand components working in separate processes and we do not consider the special case when they work on the same machine and inter-process communication provided by the operating system is possible.
The simplest and most historical ways of communication between the components were based on the exchange of files shared at a given disk location. This type of approach, although still present, has a number of disadvantages, first of all it introduces considerable delays related to data processing, and also raises maintenance problems.
In monolithic architecture, integration through a database is also often encountered – that is, various modules write and read internal data, “belonging to” different components. In the era of microservices, such an approach is considered a design error due to the too tight coupling of components and making the integration dependent on the method of storing the data in a particular module.
In this article, we’ll look at network communication related to message passing. The area of various communication protocols such as RPC (Remote Procedure Call), Corba, HTTP REST, SOAP, gRPC or GraphQL, or data representation within messages – XML, JSON, ProtoBuf is a topic that deserves a separate article and will not be elaborated here. Instead, we will look at the performance and reliability of various approaches, commonly used in connecting microservices:
- the most popular synchronous approach, where the caller forwards the request and actively waits for a response,
- a modified variant of the above, where waiting for a response is not blocking,
- forwarding messages to recipients via an asynchronous broker (message queues),
- publishing to the so-called of the event stream, even without knowing specific recipients; the recipients independently decide which events are of interest to them and at what time they will handle them.
Synchronous communication
In the case of this type of communication, the client (an initiating module), prepares the message and transmits it over the network to the server, i.e. the request processing module. The client waits for a response – at that time, it does not perform any other processing as part of its computing thread.
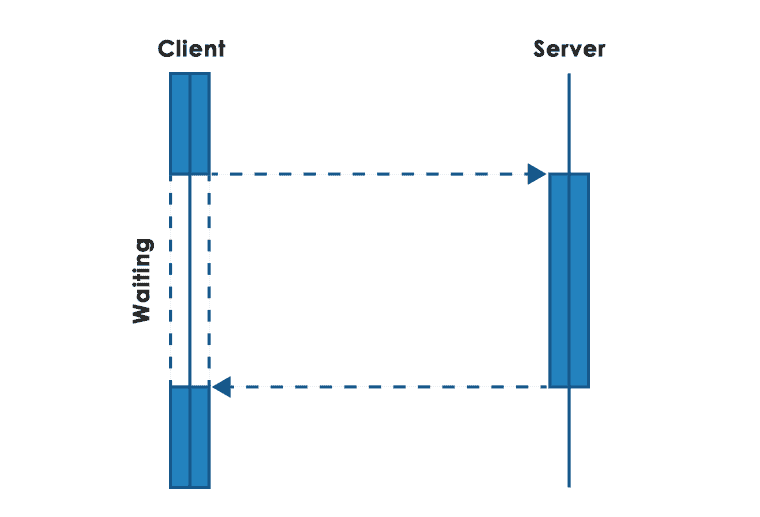
This type of approach is natural for a programmer, as it follows the standard procedural model of software development. The difference is that since the call is over the network, a timeout is usually used, which is the time limit for receiving a response. If there is no response within the given time, an error is generated and the result of remote processing remains unknown.
In the case of modules that play the role of various types of middlemen – i.e. their services are called by external clients, but they also call the services of a remote server – usually individual requests are handled in separate processes (historically) or threads. Until a response is received from the server, the given processing thread is suspended, holds the resources of the operating system (from the client and server side) and waits for the response. The server call is also usually covered by a timeout. The result of the server call after appropriate processing is forwarded to the client.
User perspective
For the user, synchronous communication seems to be the simplest model. For human-used interactive applications, using a given function means passing a message to the server and waiting for a response (usually accompanied by a waiting picture – the so-called loader). During this time, the application is inactive. After receiving the answer, the user is presented with an appropriate screen, in the event of an error, there is an message about the problem, but as we wrote earlier, there are situations (e.g. timeout) when the result of processing is not known.
What’s more, a man becomes impatient while waiting after a few seconds, and as a quick action he evaluates the response significantly below 1s. This imposes high performance requirements on the transmission and implementation of the actual remote processing.
Advantages
Despite the various problems that we will discuss in more detail in a moment, the synchronous approach is still the most widely used in computer systems. It has its advantages. In addition to being the simplest, it allows to use standard available protocols – for example HTTP. Usually, it generates low latency, because no middleware is needed, and all resources are ready for operation. In addition, many external systems exhibit their API in this form, this applies to services available on the Internet, but also many internal modules with which our solution must integrate.
Problems
Below we will address various problems, typical for the synchronous model.
C10K problem
The model with resources reserved for each processed request was one of the reasons for the so-called C10K problem, i.e. the difficulty of handling 10,000 parallel connections from clients on one machine. Fortunately, the topic is already somewhat historical, but allocating threads and other resources to each client connection is still very inefficient and can lead to resource saturation, especially if our server handles Internet traffic. It also makes scaling in the synchronous model difficult.
The delay problem
In a situation where individual subordinate services are called in turn, one has to wait for the end of one service to call the next. Delays in such a situation add up. The total processing time will be relatively long. The situation will worsen when the system as a whole is more stressed and the individual functions have longer execution times. Unfortunately, all delays in this case are cumulative.
The dependency problem
With a more complex architecture, often present in the world of microservices, a given functionality requires the cooperation of many components. In that situation, individual calls generate a tree. In the synchronous call model, where each service at a given level is called in turn, a failure on any branch makes the entire service unavailable. The problem gets worse when the failure is understood as not only a service error, but also failure to return a response within a given time. In addition, the services themselves are clearly dependent on each other, which is contrary to the microservices postulate to create only loose coupling between modules.
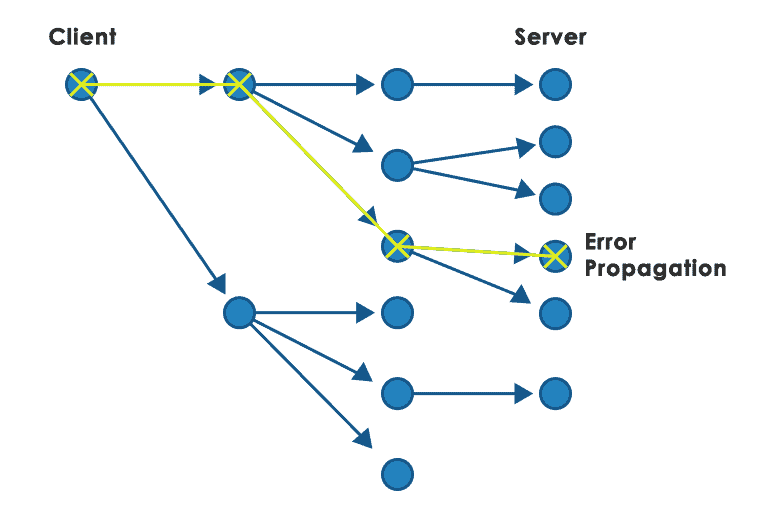
Cascade of timeouts
In the event of system overload, the response time of individual services increases. The original call (root of the call tree) was made with a timeout. All subordinates also, but in the case of a high load of the system, it may turn out that some subservices will be executed despite the fact that the time for the execution of the parent service has already run out.. This can put additional strain on an already overloaded system.
Cascade of resource consumption
As we wrote earlier, the synchronous approach assumes the reservation of resources for the purposes of communication with an external service – e.g. a dedicated thread of the operating system or a network connection. In a situation where the subservice responds with a delay (even within the timeout limits), resources in the parent service may be reserved for too long.
The above resources could be dedicated to supporting other downstream services running properly, however their use is blocked. The problem may also lead to overloading the entire system – in a situation where, for example, the thread pool can grow without limitation, and some submodules will block the resources of the parent service for a long enough. Therefore, it is extremely important to introduce a limit (e.g. the size of the thread pool that a given module can use) so as not to saturate the capabilities of the operating system of a given machine.
Non-blocking request-response communication
In order to reduce the problems encountered in synchronous communication, a specific, asynchronous from the calling perspective, online communication model is often used. The process or thread servicing a given function, when calling another service, does not wait idly for a response, but can handle other tasks during this time. When a response arrives, it will be able to deal with it, but it does not block resources (e.g. threads or database connections) until that response arrives.
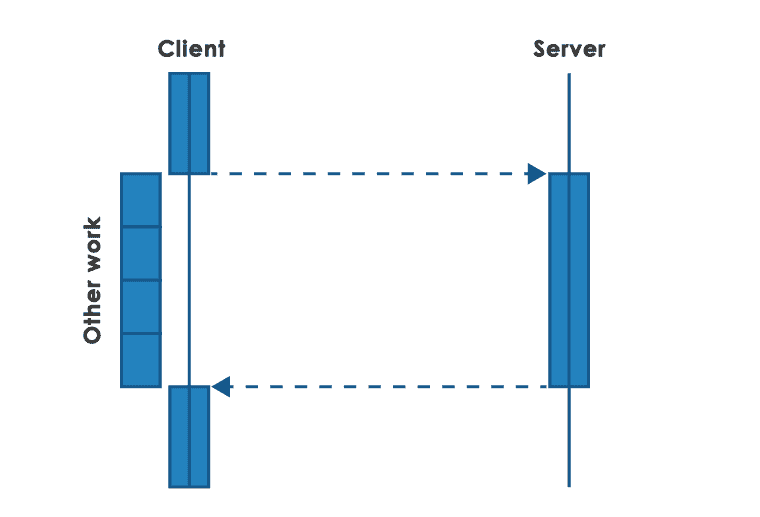
Handling of the response depends on the capabilities of the given communication transport. To receive an answer, it may be necessary to perform polling, i.e. periodically check if the answer is already available. A slightly better solution may be to register the so-called callback to handle the response, which will be invoked by the transport framework when a response arrives. A good basis for this type of model can be the use of the operating system’s asynchronous api – specifically the select / epoll function set.
Based on asynchronous capabilities in many programming languages (e.g. async / await in Python or JavaScript), it is possible to write complex solutions where the all IO operations, especially communication over the network, are handled asynchronously, without blocking resources in dedicated threads.
Advantages
The non-blocking approach allows a more efficient use of available resources, especially in the case of a large number of connections entering the system from the Internet. Thanks to this, we also circumvent the C10K problem.
Due to the fact that we do not wait for a blocking response, we can order processing in other microservices at the same time and not sequentially. This speeds up the execution of a given business function, thanks to parallelization of work.
In this model, it is also easier to avoid cascading resource consumption in the event of slowdowns or failure of certain downstream services in the case of complex processing.
The advantage is now also a good support from programming languages and popular communication frameworks such as Node.js.
Problems
One disadvantage of this model is a little more complex implementation than in the synchronous model. It is necessary to use additional programming techniques (functional, asynchronous) that require certain knowledge and experience.
It should also be remembered that most often this model assumes waiting for a response limited by timeout, so the unavailability of the target service will result in the unavailability of a higher level service.
The classic use of the above approach still assumes communication in the form of request-response. Support for one-way transmission – the event emission is limited in this case. And in some applications it is a very useful way of communication.
Overload propagation
In the non-blocking model, unfortunately, the overload of the target system with a large number of parallel requests is a greater risk than in the case of the synchronous model. This is due to the main advantage of the non-blocking model – no resources reserved for external module calls. This is especially true, when the target system is experiencing difficulties already and begins to respond slower. In this case, it is necessary to use additional communication patterns, such as backpressure or control of the number of parallel calls.
Concurrency limitation for CPU-intensive tasks
A certain problem in the asynchronous model is the processing that reserves the CPU for a long time within non-blocking software frameworks, where the so-called cooperative concurrency is used. That is, the the task must end itself or give back the processor to another job. Typically, IO calls automatically provide the ability to switch the context of processed tasks. However, the lack of such calls means that the CPU-intensive task does not allow for quick execution of many other pending small tasks. Some frameworks have mechanisms to prevent these types of problems, but it is worth remembering to periodically release the CPU as part of each longer executed task.
Communication through the asynchronous message broker
Another model used to connect microservices is the mechanism of communication through the transmission of messages using a broker. In this model, the individual modules are actually, from a communication perspective, independent of each other – they do not connect directly, but through an asynchronous module of the Message Broker (e.g. RabbitMQ or ActiveMQ). The consumer does not have to be available at the time of the message issuing by producer. What is necessary is the availability of the broker.
With the Message Broker different models of communication between the components are possible. Below we will look at the most popular ones.
Message queue
The message queue is the original and still the most popular asynchronous communication pattern. Producers generate messages that they put into a queue located within the broker. On the other side, the consumer or consumers (there may be many) receive the messages and process them according to their logic.
A given message goes from the queue to one consumer only, consumers compete with each other by taking messages from the queue. Each message should usually be processed exactly once, therefore consumers should mark the correct processing of the message with a special message (ACK). If they don’t, the broker should re-pass the message to the same or a different consumer. Therefore, it is important that in-consumer messaging is idempotent in order to detect and avoid processing of possible duplicates.
The queuing approach allows for easy scaling of consumers and distribution of the load over multiple machines, it isolates the load entering the system from the data processing itself – messages that we don’t have the resources to process at the moment can be safely temporarily stored in the queue.
It is also important that the broker usually allows you to control whether messages in a given queue are to be saved permanently (on disk), or under the faster, but less resistant to failures option of keeping data only in the computer’s operating memory.
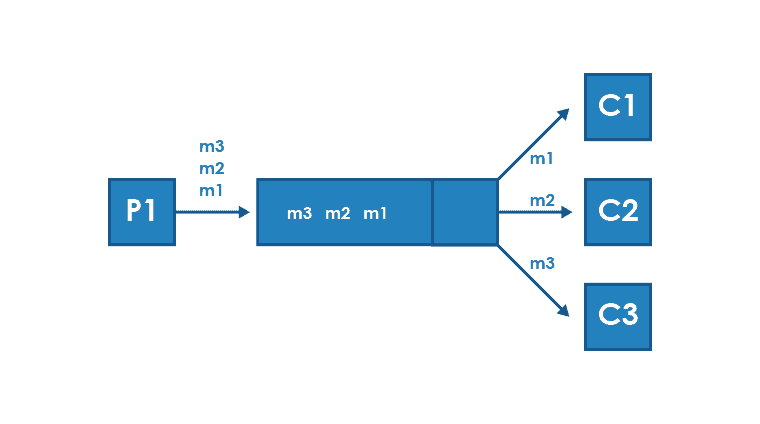
Request-response mode
The use of additional queues allows you to simulate request-response communication. In this model, the manufacturer initially generates a message and sends it to the broker queue. The consumer reads and processes the message. As a result of processing, the consumer (here acting as the producer) generates a message with the response and usually inserts it into a separate queue (or other asynchronous communication channel). The producer of the initial message reads the reply message and handles it according to its logic.
In such a model, we have possibilities and problems similar to those in synchronous communication (connecting with timeouts) with a slightly higher overhead resulting from the use of an intermediate layer. Similarly, if the producer of the message is waiting for a reply and the message consumer is unavailable, it will not generate a reply, i.e. the service will be out of order. The difference is that the broker has the function of isolating load spikes and is a platform for scaling the solution.
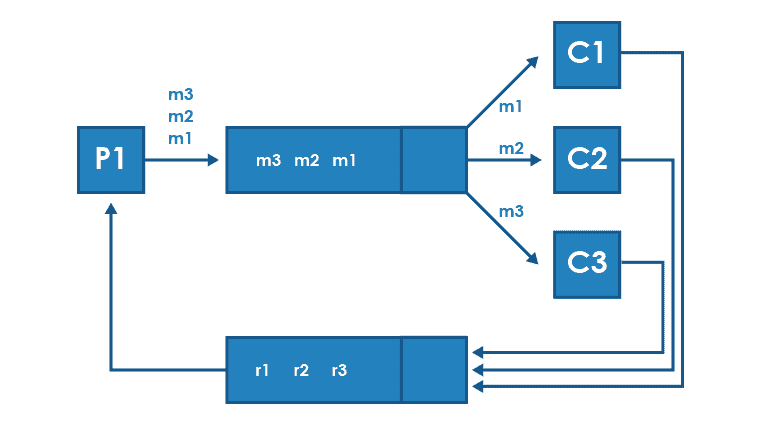
Broadcast mode
In addition to the usual one-to-one messaging, the message broker also offers other mechanisms, such as allowing messages to be forwarded to multiple recipients – i.e. broadcast. Such solutions are sometimes called one-to-many, fan-out or publish-subscribe.
In broadcast mode, the producer passes the message once, and its copy is sent to any number of recipients, each of whom should consume the message separately. Message recipients can be designated within the system logic, or they can dynamically subscribe to receive messages of a given type (in the publish-subscribe mode).
These types of solutions are used to transmit messages to several systems at once or to easily introduce changes in the operating system, extending the distribution of information to recipients.
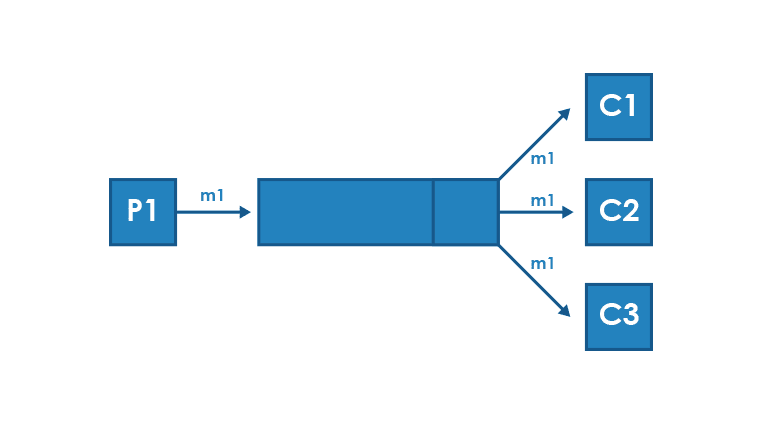
Message collection mode
On the other side of the broadcast mode, there is a model of collecting messages from multiple sources in one place. This approach is also known as fan-in or many-to-one mode.
This model can be useful in places where a central component is used. Such component controls the processing of a complex business process and manages the execution of each individual step. It can also be used to collect responses from multiple systems, allowing you to combine broadcast mode with the request-response mechanism. However, it should be remembered that the fan-in approach may make it difficult to scale solutions, by concentrating logic in one place.
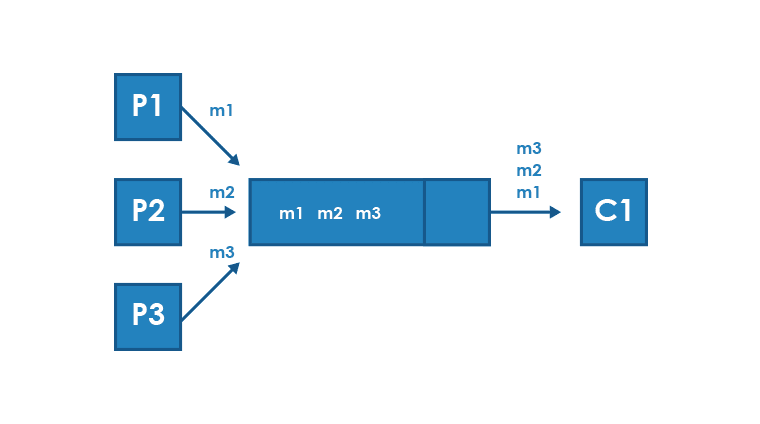
Advantages of communication through a broker
The broker communication approach is ideal for one-way calls. The producer sends the message and does not have to wait for a response. The broker accepts the message and is responsible for delivering to all intended consumers. From the producer’s perspective, this is a convenient approach. It allows to balance the load on individual layers of the system and thus support temporary peaks in inbound traffic.
In this model, there is also no risk of overloading the message consumers – they retrieve data from the queue and process it with their own performance. The entire system can be overloaded, but the respective layers behind the queue can work properly and efficiently.
The Message Broker also usually has a number of useful features – it allows you to permanently save messages for greater reliability, or only process them in memory for greater efficiency. It offers load-balancing and flow-control mechanisms, including backpressure sending, provides support in the event of queue overflow and other problems (e.g. DLQ mechanism – Dead Letter Queue and many others).
Problems
Required broker
The Broker module allows you to introduce isolation between the layers. However, as an additional object in the architecture, it becomes another potential failure point. Of course, individual broker instances can be replicated in a clustered configuration, but then there appear problems related to quorum behavior, at-most-once and at-least-once delivery guarantees, idempotency verification and other subjects that complicate the solution and increase the risk of errors.
Possibility of overloading the queues
In the queue model, there is no risk of overloading message consumers, but there is a risk of overloading the queues themselves or the message broker. Of course, the broker can scale horizontally, but if the message consumer is not available for a longer time, the constant flow of messages from producers may result in exhausting the resources dedicated to the queue.
Introduced delay
The broker usually runs in memory mode. Delays in such a situation are minimal – usually less than 1ms. Of course, in this model we lose some reliability. The sender has no guarantee that the message will reach the addressee. In the model with permanent writing to the disk, the delays can be significant, but in some solutions it is necessary. Of course, a solution without a broker will be faster in such a situation.
Communication through the event stream
A model similar to communication through publish-subscribe queues, but the message is not directed to a specific recipient (or recipients). Instead, the individual modules deal with the production and reaction to events. In principle, they don’t need to know anything about themselves, the event producers don’t even need to know when, or if at all, anyone will consume the events they generate.
The business process itself is also subject to a certain abstraction – it does not have to be controlled by any dedicated component, it can only indirectly result from the complex process of generating and receiving events by various microservices.
From the point of view of the independence of the work of individual components, the event model is the most loosely coupled approach. We do not have a problem here with the fact that the failure of one component affects the efficiency of other components. It is true that an event stream handler (eg Kafka) is necessary, but individual microservices themselves decide about the pace and logic of their work.
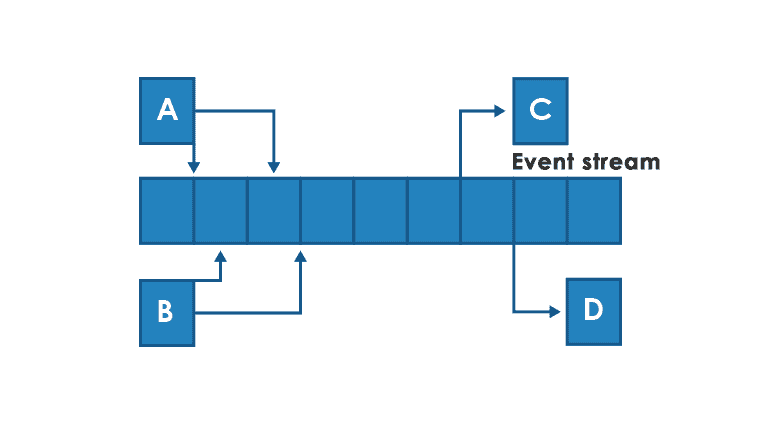
When using the Kafka system (currently the most popular framework for event stream), entries to the event stream simply go to a file. By default, with write caching enabled and only periodic synchronization to physical disk. This ensures very high efficiency. All data is kept in the file continuously for a configurable time – usually several days.
From a reliability perspective, Kafka provides at-least-once semantics. Any write to the broker, as long as the broker returns a confirmation (ACK), can be considered saved, and Kafka ensures that the every subscriber receives this message at least once.
Advantages
Event stream is a solution that is derived from message queuing. All the strengths of this approach also apply to the event stream.
The main advantage of the event stream approach is the very high independence of the components that communicate in this way. Both on the physical level – that is, the availability of consumers does not affect the producers in any way, and logical (which goes beyond the standard capabilities of the queue model), where processes should be built in such a way so that they do not depend on the consumption of events by specific modules.
A solution built on the basis of an event stream can also have very high, basically unlimited capacity. It is easy to scale the solution by adding new sharding modules. It’s also relatively easy to add replication.
Problems
Limited transparency of the business process
A modern approach for event stream, where the business process is a set of separate event processings in different modules, without central logic, gives flexibility, but at the cost of losing transparency of the business process. It is difficult to assess the correctness of the entire processing and in the event of a failure the exact place where the problem appeared.
Difficulty in ensuring data consistency
Unfortunately, using an event stream also means risks resulting from data duplication and its parallel handling – we do not have a good way to ensure continuous data consistency in such a model. Usually, the eventual consistency approach is used in this case, i.e. we allow a situation that data in different modules temporarily may not be consistent. To deal with complex business processes, where single events may generate errors during processing, compensating transactions and the SAGA model are used.
Specific use in the user interface
In the event model, it is possible to define the user interface in such a way that a positive message only means acceptance of the order for service, not its execution. The effect of this order does not have to be visible immediately. It may appear with some delay. However, this is usually not intuitive for the user.
Complicated integration with external systems
Event-based communication changes the way of interfacing with external systems, which mostly provide APIs in the request-response model. Special dedicated gates are needed to translate the event semantics into API required by the target system.
It should also be remembered that event stream brokers typically offer at-least-once data delivery semantics, which means that duplicates can occur and must be handled properly. Usually by using idempotent events and for example checking message identifiers. However, this complicates the solution.
Summary – what approach in a given situation
Each of the presented models has its application in modern solution architectures, in microservices in particular. Synchronous communication is difficult to avoid – it is the most popular connection model, commonly used in integration with external systems. If we have the possibility – it is worth to use non-blocking request-response communication. It is particularly important in handling traffic entering from the Internet (i.e. where a lot of parallel network connections can potentially occur).
The queuing model is worth using when we want to make different parts of the system independent in terms of the load generated by the traffic passing through them. Also, all situations where the message producer does not have to or does not want to wait for a response can be easily handled in this way.
The event stream can be an alternative to the queuing model. It also allows you to separate different modules and the load generated by them. However, its proper use is to work in the integration of systems operating in the choreographic model, where individual modules track events occurring in the system, react to them, carry out additional operations according to their logic and possibly generate further events, that someone in the system can react to. This approach is now particularly recommended in the integration of microservices.
End of part one.
Piotr Martyniuk: Softax solution architect with over twenty years of experience in IT projects for the banking industry.