



Project guest post by KubeEdge Maintainers
Project Background
In 2018, the Ministry of Industry and Information Technology (MIIT) of China launched a national innovation and development project to build an industrial big data center. China Mobile undertook the R&D of features related to edge collaboration and data collection in this project.
Requirements and Challenges
Requirements
- Collecting production and running data from factories and sending the data to the cloud
- Unified control in the cloud: what data to collect and how to process the data
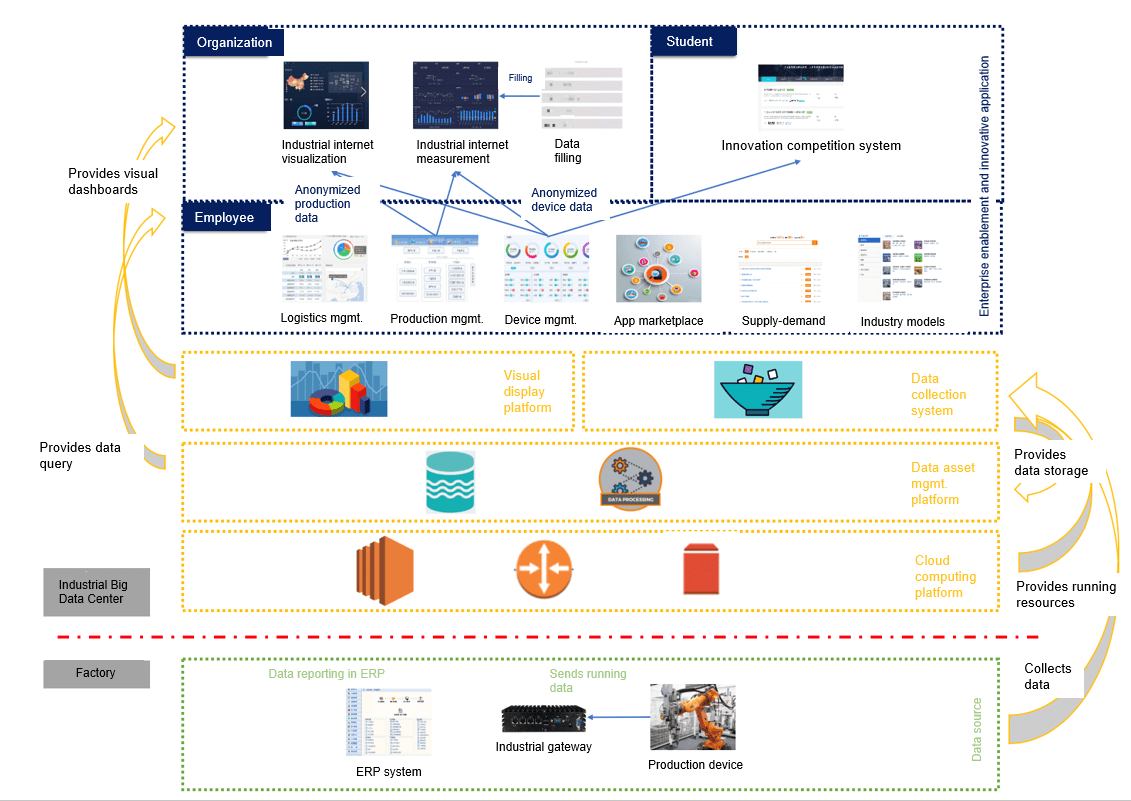
Challenges
- Only edges can proactively connect to the cloud. The other way round was impossible (the edge does not have a public IP address).
- Different types of industrial devices and protocols cannot be supported at the same time.
- When the network was unstable, edge nodes cannot run autonomously.
- Edge computing was not supported for running applications on edge nodes.
- A large number of resources were consumed.
Technology Selection
The first solution we considered was EdgeX. EdgeX is good for data collection and management, but still, it falls short in aspects such as edge-cloud collaboration. It is more an autonomous architecture for the edge and cannot connect to the cloud. We did have some remedies. For example, we can connect EdgeX nodes to the central cloud through a VPN, but the scalability of this remedy is poor.
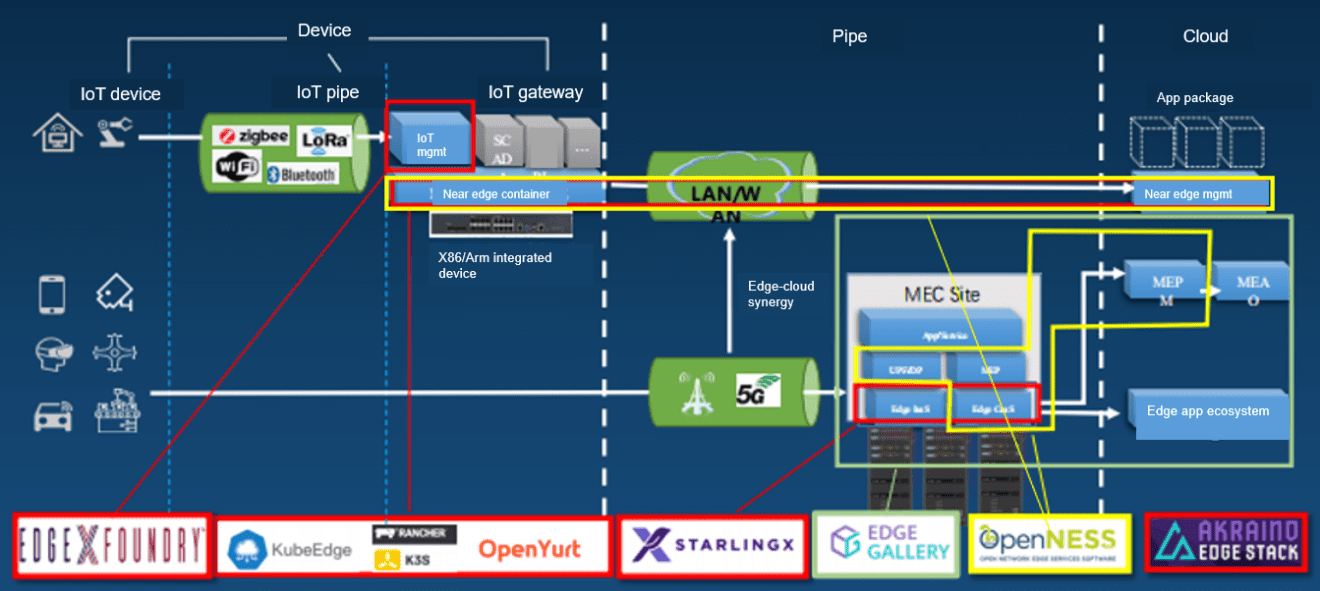
The second solution is K3s/K8s. Both K3s and K8s do not support edge-cloud collaboration, and K8s occupies too many resources. Although K3s can run with fewer resources, it does not support device management.
Then we tried OpenNESS, which is a universal framework. However, it was too universal for us. We needed to write adapters for almost every platform we needed, for example, Kubernetes at the bottom layer. The development workload was relatively heavy, and device management was not supported.
We once wanted to use OpenYurt, whose functions are similar to KubeEdge. However, at that time, our project had been halfway through, and we decided not to change. It seems to be a right decision, especially after we now find that OpenYurt is not as mature as KubeEdge.
Finally, we decided to use KubeEdge. It consumes less resources and provides both edge-cloud collaboration and device management.
Architecture Design
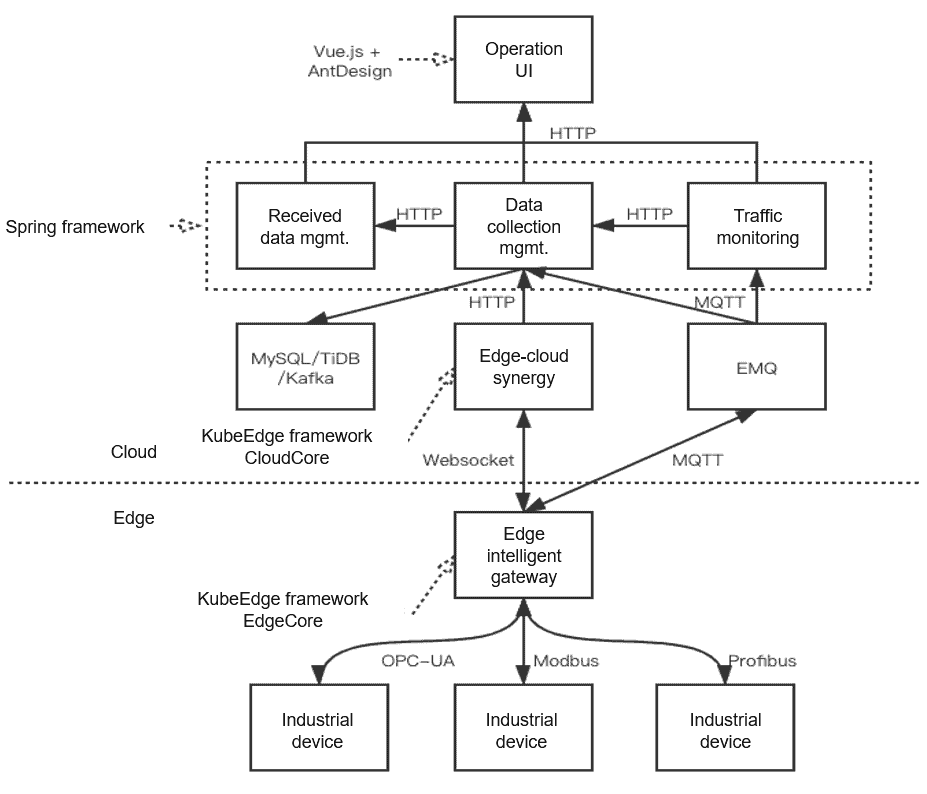
The preceding figure shows the architecture used in the National Industrial Internet Big Data Center. The core is KubeEdge, which manages devices and applications. We deploy the CloudCore of KubeEdge in Kubernetes clusters in the cloud. All data, including management data, is stored in these cloud clusters. The EdgeCore of KubeEdge is deployed on industrial computers or industrial gateways to run containerized applications at the edge, including applications for device management and data collection.
Deep down in EdgeCore, you can see Mapper, which is a standard for device management and data collection. Currently, the Mapper community provides Modbus and Bluetooth. For example, if you want to manage a camera of your own, you can code it using Mapper. A layer above, you can see the encapsulated management services through Java and Spring Cloud. If KubeEdge or Kubernetes APIs are exposed to users, users may use these open APIs to perform some operations that could be disastrous to data isolation and their Kubernetes clusters. That’s why encapsulation is needed.
We also developed an industrial app marketplace for individual developers or vendors to develop and release Mapper applications, free or paid, based on KubeEdge. We want to attract more KubeEdge users and at the same time, bring tangible benefits to Mapper developers.
Data Collection
We have made the following improvements to KubeEdge:
1) Support a wider range of industrial devices and protocols.
When we started, we found that KubeEdge only supported Bluetooth and Modbus. These protocols were fixed in the KubeEdge CRD and could not be modified. To support different industrial protocols (some of them are proprietary), we need to add some customized extensions. One is to extend existing protocols, for example, Modbus. Different devices may have some extra configurations. In this case, you can use the newly added CustomizedValue field to customize fields. Another option is to use CustomizedProtocol, instead of the community protocols, to customize your own protocol.
2) Simplify device data collection configuration.
Industrial practices are sometimes different from IT development. Normally, we define templates before defining instances. However, in industrial practices, it makes sense to define instances first and then copy and modify the content in the instances. For example, 10 temperature sensors of the same type are connected to the same industrial bus. They have the same attributes except their offsets on Modbus. In this case, you only need to change the offsets in the instances, and we made that possible by moving PropertyVisitor in the device model to DeviceInstance. We also made configurations more flexible. For example, you can set your devices to report temperature data once an hour and energy consumption data once a day. The configuration items involved, such as CollectCycle, are added to PropertyVisitor, and the serial port and TCP configurations are extracted to the public configurations.
3) Optimize the delivery of twin properties.
4) Support bypass data configuration.
Bypass data processing
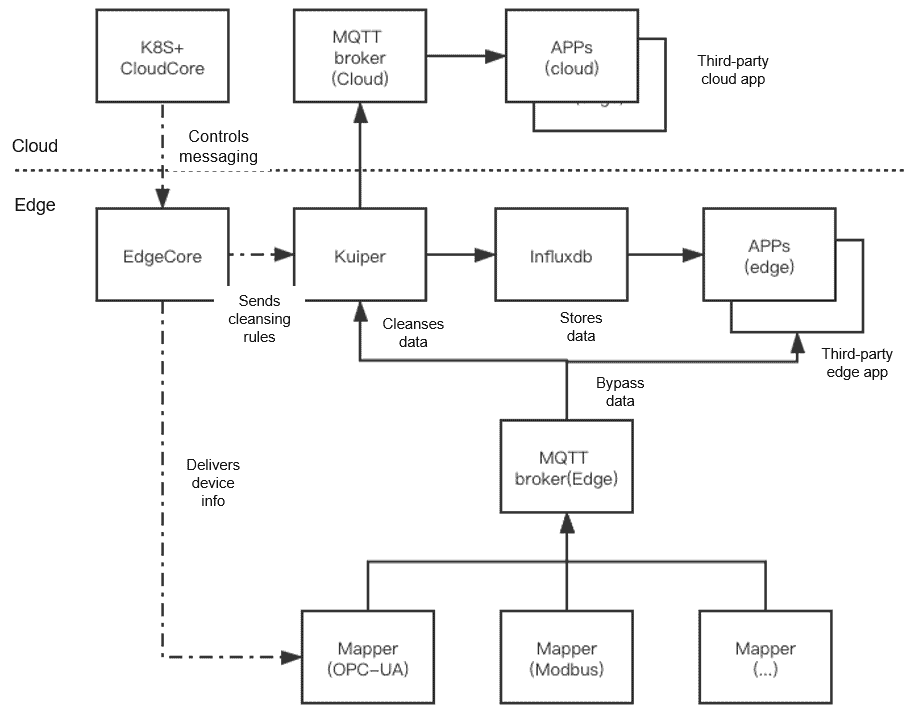
The integrated EMQX Kuiper can read metadata from the device profile.
KubeEdge delivers cleaning rules to Kuiper.
Third-party applications directly obtain data from edge MQTT devices.
Status Monitoring
Status monitoring is very important for commercially used products. KubeEdge provides a channel called Cloud Stream. This channel can work with MetricServer or Prometheus. However, you need to configure iptables to intercept the traffic, and if you do so, the entire traffic is intercepted.
Therefore, we developed another solution. We run a cron job container on the edge node, for example, to pull data from the NodeExporter on the edge node every 5 seconds and then push it to the PushGateway, an official Prometheus component. PushGateway is deployed in the cloud. In this way, we can use the cloud to monitor all edge nodes.
Other Problems Encountered
Multi-Tenant Sharing
Kubernetes allows multi-tenant sharing. However, in KubeEdge, different devices cannot be deployed under different namespaces. We need to tag devices and filter them based on the tags. An edge worker node cannot belong to a specific namespace, neither. It belongs to a tenant and is exclusively used by the tenant. In this case, the node can be encapsulated with the upper-layer services.
IP Address Limitation
Generally, tenants connect their edge nodes to a Kubernetes cluster in the cloud. A public IP address is therefore required for the cluster, but you may not have enough IP resources for your project. For example, you have 200 available public IP addresses, but you have 1,000 tenants. How will you allocate IP addresses to tenant clusters?
1) IPv6 is the best solution. KubeEdge supports IPv6, but we haven’t tried it yet.
2) Port multiplexing: KubeEdge uses only several ports, 4 to 5 at most. The default port is 10003. One public IP address can be reused by multiple KubeEdge instances.
HA solution
KubeEdge reuses Kubernetes Services, Deployments, and status check to ensure HA.
Use Cases
Case 1: OPC-UA Data Collection and Processing
After a user subscribes to the OPC-UA mapper, it will be delivered to the edge gateway and work with industrial devices at the edge after configuration. For example:
The OPC-UA mapper collects temperature data.
The edge node alarm application directly obtains data from the edge node.
An alarm is triggered when the threshold is exceeded, and the device is suspended.
KubeEdge adjusts the threshold.
Case 2: Industrial Video Surveillance
This application runs autonomously after being delivered to the edge. AI inference is performed at the edge. To combine the cloud with the edge, you can train the model in the cloud, and then push the model to the edge through KubeEdge.
KubeEdge manages video surveillance application configurations on edge nodes.
Video surveillance applications run autonomously on edge nodes.
Collect video streams from cameras for AI inference.
Detect safety helmets and workwear.
Detect unauthorized access.
Summary
- KubeEdge-based industrial data collection
- Different types of industrial protocols can be supported through CustomizedProtocol and CustomizedValue.
- Use ConfigMaps in the cloud to control edge data applications (Mapper).
- Bypass data (Spec/Data) streamlines the processing of time series data.
- Deploying KubeEdge in real products
- Multi-tenant solution
- Multiple monitoring solutions
- HA solution
- IP address multiplexing solution
For more details about KubeEdge, visit
Github: https://github.com/kubeedge/kubeedge
Website: https://kubeedge.io/en/