

Guest post originally published on the Rookout Blog by Elad Uzan, Rookout
There’s no doubt about it: data is the new gold. The last decade has created a revolution in everything related to data, whether it’s the creation of huge amounts of data or anything related to consumption, collection, processing, analysis, and decision making.
In my previous experience as a data scientist, I can say that algorithms; whether a simple algorithm or an extremely complex neural networks model; as good as they may be, cannot beat bad data. You can spend hours working on tweaking your model’s hyperparameters, but once you get the right data and enough of it, everything suddenly just…makes sense. Quality data is a game changer, especially when the ability to produce it is simple and comes at a low cost.
When it comes to software development, data is a key part of your success. Visibility into any part of your product is crucial, and without it, you are walking blind. These days, the ability to get data isn’t enough. Speed and simplicity are also critical for operating in such a dynamic world. That’s why I’m going to explore some data basics and how data can be utilized to not only reduce debugging time and effort but also increase software development efficiency. So let’s get started!
Data != Information != Knowledge
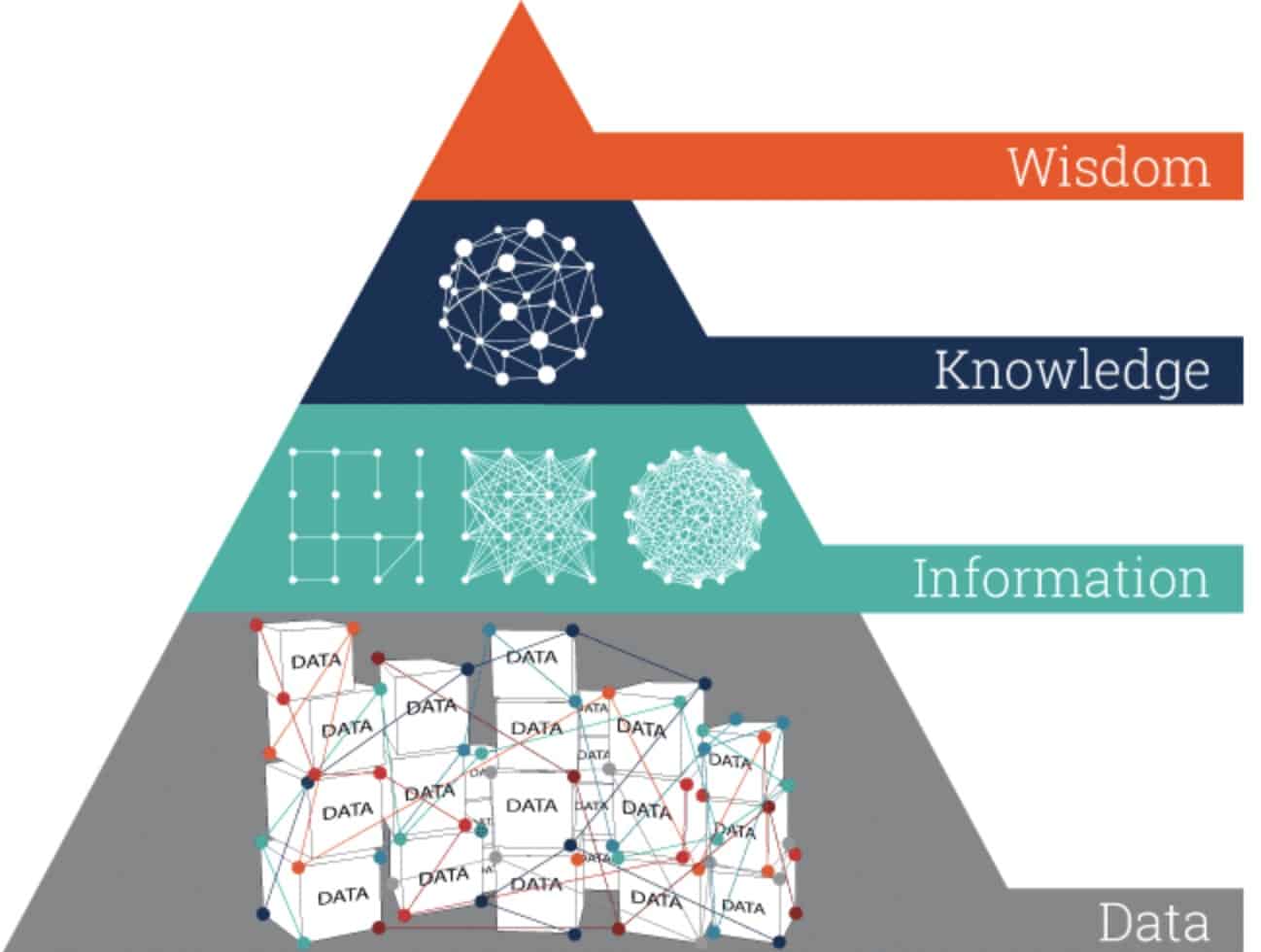
Many make the mistake of thinking that the existence of data makes it possible to draw direct conclusions. But that couldn’t be further from the truth. Look at the pyramid of DIKW (data, info, knowledge, wisdom), for instance. We immediately see that data is at the bottom of the pyramid. There are several steps and processes that have to occur until conclusions can be drawn and actions are taken.
To begin with, several pieces of data need to be collected together in order to generate information. Think about a log line. Each log line is constructed of several data pieces: the timestamp, file and line number, the developer’s log string, printed variables, and more. And each one of them is meaningless until combined together. Together this log line has a meaning – we’ll call it ‘information’ (event/insight) – and is more than just a couple of data pieces.
Yet, information isn’t enough. Let’s be honest with ourselves, simply sending logs somewhere doesn’t just solve the issue, right? When you have an issue that needs to be resolved or a decision to make, you’ll probably look for information in that specific context. For example, when driving, you won’t pay attention to every red light. You will however pay attention to the ones that specifically affect the lane you’re driving in. The same rule applies to debugging. Not all of the collected information interests you. Only the information that’s in the right context of what you are trying to resolve does.
When you combine context and information, you create knowledge. When you gain enough knowledge and understanding of your code patterns, you can decide what should be done. This is the last part of the pyramid (wisdom).
Data is the new gold, and gold is expensive
I previously stated that the more data you have, the more informed you’ll be, and thus the faster you’ll be able to make decisions or resolve issues. But I didn’t say it was free. It’s not just a matter of quantity, but a matter of quality.
You definitely can’t – and wouldn’t want to – store all the necessary data as it will cost you a fortune (in terms of financials and performance). There needs to be a balance between what must be maintained and stored on a regular basis and the ability to produce more data on demand, instantly, independently, and effortlessly, in the most comprehensive way, with minimal impact on the day-to-day work. No matter what you are trying to achieve, if you have the right tools to extract the data you need with no delay and with minimal effort, it will reduce the urge to constantly collect data.
Different layers of information
Information can be treated like insights. Several insights can be aggregated together and create another level of insights at a higher level. This means that data processing techniques can be used, such as aggregations, data visualization, statistics, or the like to create another representation that affects our understanding. Higher levels of insight can help to reach decisions easier and faster.
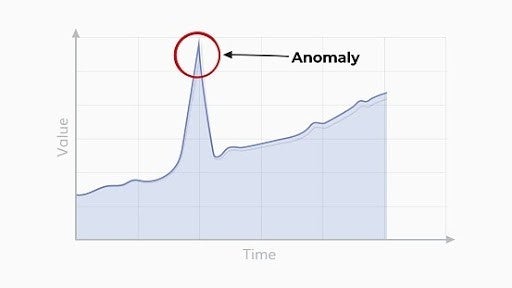
For example, see how easy it is to detect the anomaly point when you visualize the data points. Checking each data sample could take time, but looking at this graph, it took less than a second.
Debugging with a local debugger requires you to chase the issue by stepping in, stepping out, and stepping over code/a function. This pursuit is completely eliminated when you let the data flow and analyze it separately using the power of data processing.
Synthetic vs. Real World
One of the biggest challenges in the quest for the right data is that the world is ever-changing. That means that even if we take a snapshot of any piece of data today we will still see new use cases tomorrow.
If in comparison, we refer to software development, we are able to see that in many cases a bug that’s discovered in the production environment wasn’t caught by the tests, but instead went under the radar when tested with synthetic data in staging. Therefore, it might not be reproduced in an environment other than the real and live environment. For that reason, you always want to use up-to-date information and track what’s happening in real-world cases.

A single sample isn’t always enough for decision making
Try to imagine the last time you clicked many times on “Step Over” when you were trying to debug a for loop. Wasn’t it simply easier to collect all the iterations and analyze them afterward?
A single sample is useful where a problem is deterministic and always recurring, such as in a local environment, in production, or in any experience. But there are cases where certain issues are environment-dependent (because lower environments don’t always perfectly mimic prod), or depend on the state and collection of actions of a specific user. The other types of issues are harder to reproduce and one sample is not always enough to determine where the issue is.
You probably know which code is related to the issue, but you want to collect as many samples as you can so that you can analyze when it happens and why. Seeing many samples gives a broader context and can help to pinpoint a root cause that is not easy to detect.
The intersection between software development and debugging
If you have survived this far, congrats! You understand how much power data has and how it can transform your analysis capabilities. And that’s exactly why using a data-driven debugger is so essential.
The use of a data-driven debugger enables your developers to reduce the time needed for collecting debug data from remote environments. With it, they’ll be able to get the relevant data they need in seconds from any environment, at any point in time, from any part of their code, which will reduce the time needed to resolve customer issues. Additionally, from a performance perspective, a data-driven debugger is a data-centric tool and, as such, has a minimal footprint on your application, as it provides developers the flexibility to collect and analyze data on demand, and only when needed. And we know that you know how beneficial being able to do that is.
So what are you waiting for? Hit that data flow. We recommend doing it with Rookout (did anyone say minimal footprint, any environment, and faster MTTR?). But really, whichever tool you choose, just do it (not to steal Nike’s motto or anything). The bottom line? Data makes you smarter and the future of debugging is data-driven debuggers 