

Guest post by KubeEdge Maintainers
Introduction: KubeEdge is an open-source edge computing platform. Based on the native container orchestration and scheduling capabilities of Kubernetes, KubeEdge achieves functionalities such as cloud-edge synergy, edge computing, edge device management, and edge autonomy. KubeEdge is also widely implemented in scenarios such as 5G MEC and AI cloud-edge synergy by using plug-ins.
This article mainly shares practices of edge stream data processing based on KubeEdge and Kuiper.
Kuiper – A stream processing product at the edge
Initiated in early 2019 and released in October 2019, Kuiper has been iteratively developed to be a classic stream processing architecture.
This product is designed to enable the stream processing that runs in the cloud, such as Spark or Flink jobs, to run at the edge.
Architecture Diagram of Kuiper
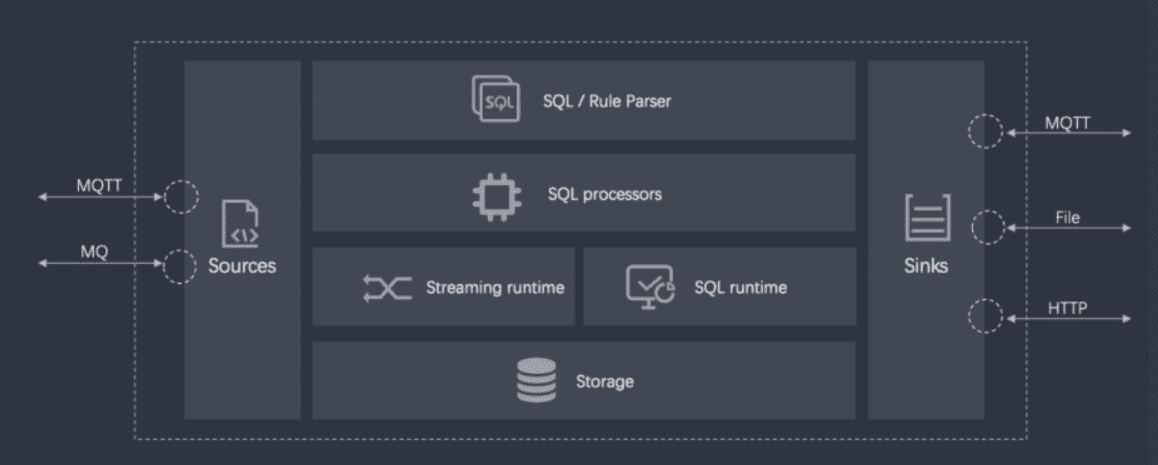
The overall architecture diagram consists of three parts. Sources on the left indicate the data sources, which can be the MQTT macOS broker at a certain edge of KubeEdge, or files, windows, or databases.
Sinks on the right indicate the storage locations after data processing. The target locations can be MQTT, files, databases, or HTTP services.
The middle part is divided into several layers. The top layer is the data service logic processing layer, which provides SQL statements and rule parser. SQL processors process and convert them into SQL plans. The middle layer contains the streaming runtime and SQL runtime, which are used to run the final plan. The bottom is the storage layer, which is used to store outgoing messages.
Application Scenarios of Kuiper
Real-time stream processing at the edge
Rule engine to customize rules for alarm and message forwarding
Data format and protocol conversion for edge and cloud data to integrate IT and OT
KubeEdge and Kuiper Integration
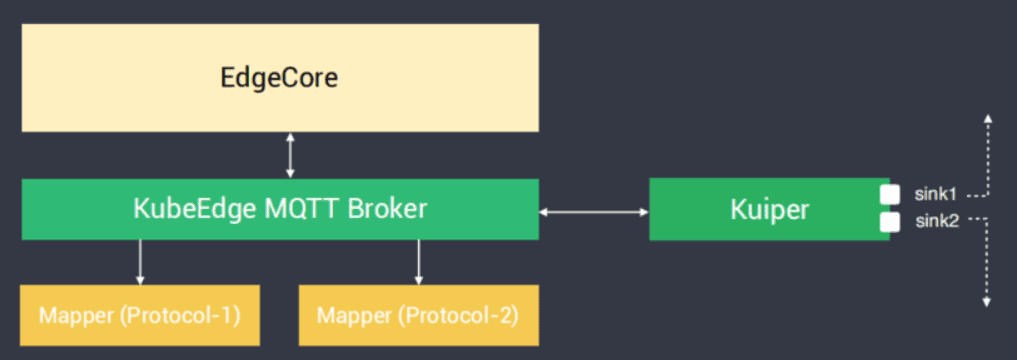
Parts of the architecture
Kuiper is installed at the downstream of the KubeEdge MQTT broker. Both of them run at the edge. There are different underlying mappers, that is, different types of protocols. The edge MQTT broker is used to exchange messages.
Data Processing Types:
- Obtaining the type definition from the device model file
- Converting data to the types supported by Kuiper
- Using the schema-less flow definition for creating a stream
The supported data types are int, string, bool, and float.
KubeEdge Model File and Configuration
The following figure shows parts of the configuration file, including the device name, property, name, data type, and description.

Parts of the configuration file
- Save the device model file.
- Configure the model file information in ect/mqtt_source.yaml.
- KubeEdgeVersion: not used yet, reserved for future model files of different versions
- KubeEdgeModelFile: path of the model file
- Deliver the configurations as a ConfigMap and save them to the related directory.
Using Kuiper
- Define the stream, which is similar to defining a table in a database.
DATASOURCE=”$hw/events/device/+/twin/update” is a topic already defined in KubeEdge.
- Define and submit the rule.
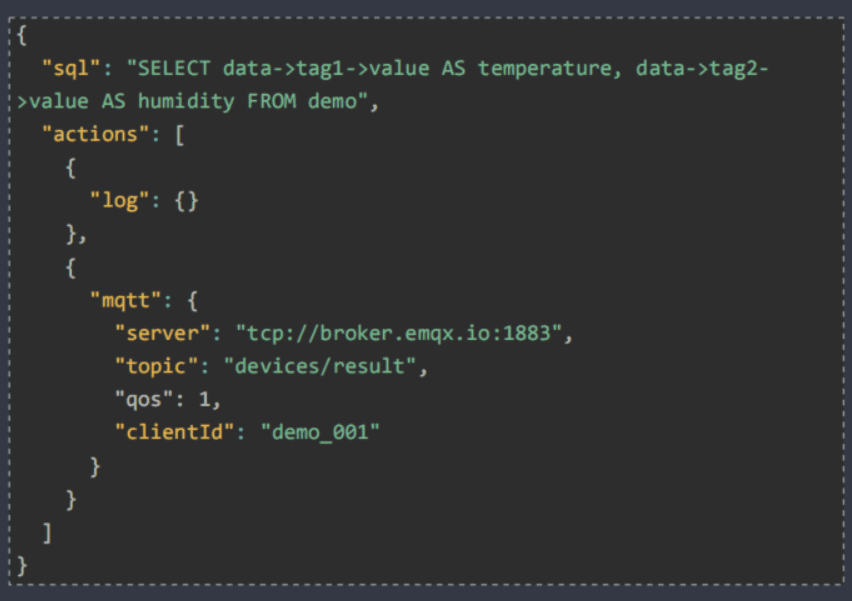
- Implement the service logic with SQL and send the results to the specified target.
- The following SQL operations are supported:
SELECT/FROM/WHERE/ORDER
JOIN/GROUP/HAVING
4 types of time windows + 1 count window
More than 60 SQL functions
- Run Kuiper.
Deploying Kuiper in KubeEdge
Method 1: Using Kuiper-Kubernetes-tool
This tool independently runs in containers to execute the command configuration file delivered as a ConfigMap.
- For specifying IP address and port number of Kuiper in the configuration file
- The directory where the command file is located
Run the file. The tool periodically scans the file and executes the command.
Method 2: Using Kuiper-manager and Cloud-Edge Synergy Management Console
You can also use the management console to manage nodes on which Kuiper runs.
For example, when Kuiper is running in the IoV box that connects many vehicles, you can use Kuiper-manager to connect all instances and update rules in a unified manner.
First, install plug-ins. For example, if you want to connect to an unsupported source, you can write a plug-in with our guides and install it. After that, you can use it on an Android plug-in interface.
Next, create a stream definition.
Specify a location or path for saving data to the file system.
Finally, compile the rule on a visualized editing page.
Use Case: Industrial Internet Big Data Center
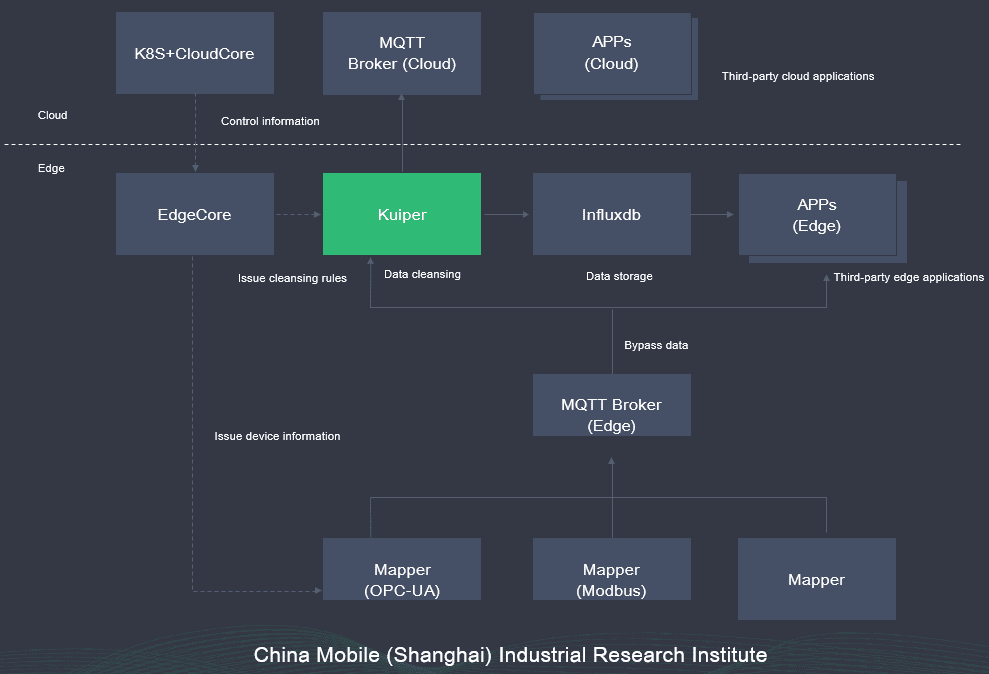
This is a typical application scenario. Kubernetes and CloudCore are deployed in the cloud to deliver rules to Kuiper through a management channel. Kuiper is deployed on the MQTT broker to define and clean data. Currently, there are two channels. The first channel is used to send processed messages to the cloud MQTT broker. The second channel is used to store data to the Influxdb database for local data persistence. Some third-party applications at the edge can directly invoke data from Influxdb for visualization. At the bottom layer, mappers are used to connect different data.
Application Scenarios of the Rule Engine in Kuiper
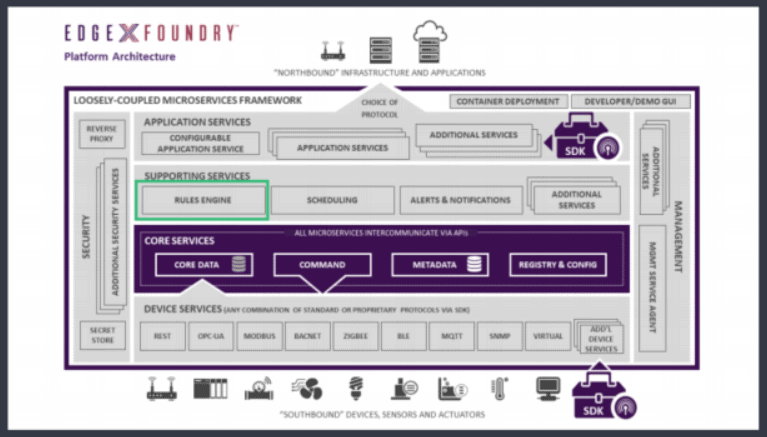
The built-in rule engine LF EdgeX Foundry was officially released in the Geneva version in April 2020.
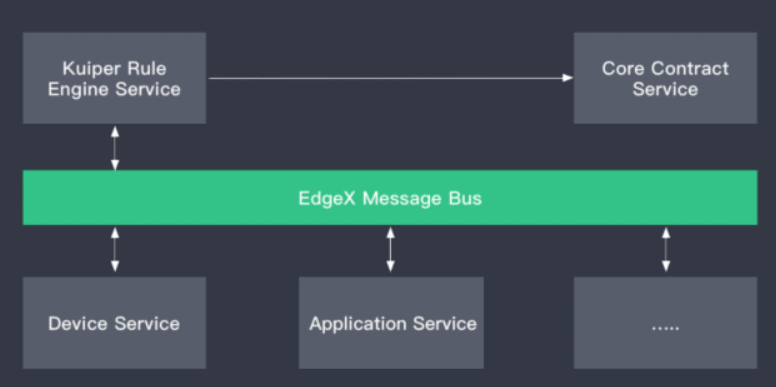
Use Case: Data Format Conversion for Interconnection between Heterogeneous Systems
To realize data exchange with IT systems such as ERP and MES, flexible extensions are provided to easily collect and process data, even the heterogeneous data, using SQL built-in functions or extended functions. After the data is processed, the analysis result can be converted using the data template of the sink to flexibly adapt to various target systems that require different data formats and protocols. For example, for sending an instruction to control the device when the temperature is higher than 30°C to both the device and your WeChat, though different APIs and data are required, the rules are the same. Therefore, you can specify different topics in the same rule in data to send data without complex programming. SAP NetWeaver RFC SDK is used to read data from SAP, process and convert the data, and send the data to other heterogeneous systems.
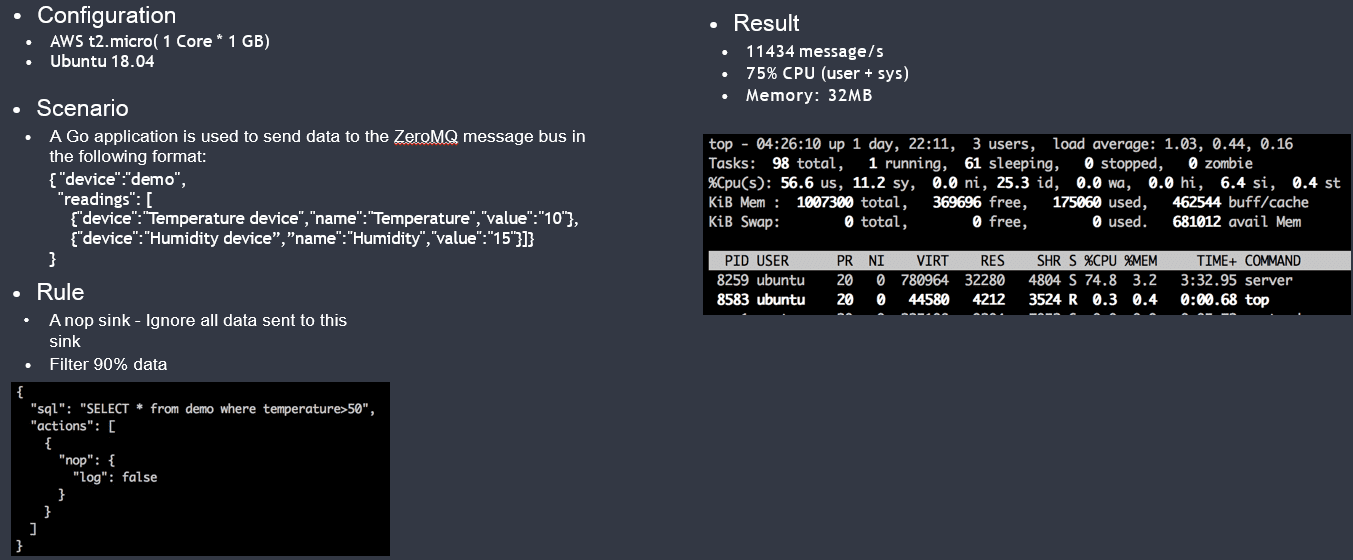
Performance Data
- Kuiper supports concurrent running of thousands of rules.
- 8,000 rules x 0.1 messages/second/rule, with the total TPS of 800 messages/second
- Rule definition
Source: MQTT
SQL: select temperature from source where temperature>20 (90% data is filtered)
Target: logs
- Configuration
AWS: 2 cores x 4 GB
Ubuntu
- Resource usage
Memory: 89% ~ 72%; 0.4 MB/rule
GPU: 25%
- AWS t2.micro has 10k+/s message throughput.
For more details about KubeEdge, visit
Github: https://github.com/kubeedge/kubeedge
Website: https://kubeedge.io/en/