Guest post by Anne Holler, Chi Su, Travis Addair, Henry Prêcheur, Paweł Bojanowski, Madhuri Yechuri, and Richard Liaw
INTRODUCTION
Deep Learning (DL) has been successfully applied to many fields, including computer vision, natural language, business, and science. The open-source platforms Ray and Ludwig make DL accessible to diverse users, by reducing the complexity barriers to training, scaling, deploying, and serving DL models.
However, DL’s cost and operational overhead present significant challenges. The DL model dev/test/tuning cycle requires intermittent use of substantial GPU resources, which cloud vendors are well-positioned to provide, though at non-trivial prices. Given the expense, managing GPU resources judiciously is critical to the practical use of DL.
Nodeless Kubernetes commoditizes compute for Kubernetes clusters. It provisions just-in-time right-sized cost-effective compute for a Kubernetes application when the application starts, and terminates the compute when the application terminates. There are no autoscaling knobs to configure/maintain and no compute shape decisions (e.g., on-demand/spot/CaaS) to be made.
This blog describes running Ray and Ludwig on cloud Kubernetes clusters, using Nodeless K8s as a smart cluster provisioner to add right-sized GPU resources to the K8s cluster when they are needed and to remove them when they are not. Experiments comparing the cost and operational overhead of using Nodeless K8s vs using fixed-size Ray clusters running directly on EC2 show sizable improvements in efficiency and usability, reducing elapsed time by 61%, computing cost by 54%, and idle Ray cluster cost by 66%, while retaining the performance quality of the AutoML results and reducing operational complexity.
CLOUD RESOURCE MANAGEMENT EXPERIMENTS
OVERVIEW
Ludwig v0.4.1 was recently released, introducing its AutoML capability [Ludwig AutoML blog]. The functionality was developed by meta-learning from the results of thousands of hours of model training across 12 datasets. We previously reported [Cloud Native Rejekts 2021] on an initial proof-of-concept applying Nodeless K8s resource management to this heuristic development workload.
In this blog, we describe applying Nodeless K8s resource management to the workload of validating Ludwig’s AutoML capability across an additional three datasets. Ludwig AutoML utilizes the Ray Tune distributed execution platform to perform data-informed hyperparameter search on GPU-enabled workers. The validation datasets were run using AutoML with 1 hour, 2 hour, and 4 hour Ray Tune time budgets, and the resulting model accuracy performance was compared to high-performing manually-tuned models.
CONFIGURATIONS AND RESULTS
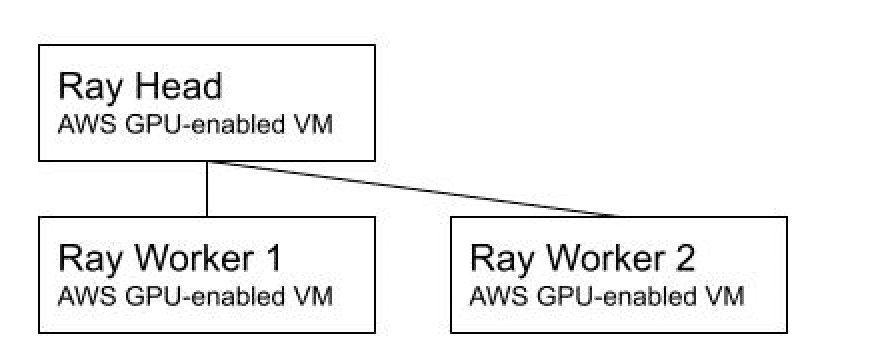
The baseline configuration we used for Ludwig v0.4.1 AutoML validation was a fixed-size Ray cluster deployed directly on AWS GPU-enabled virtual machines, as shown in Figure 1.
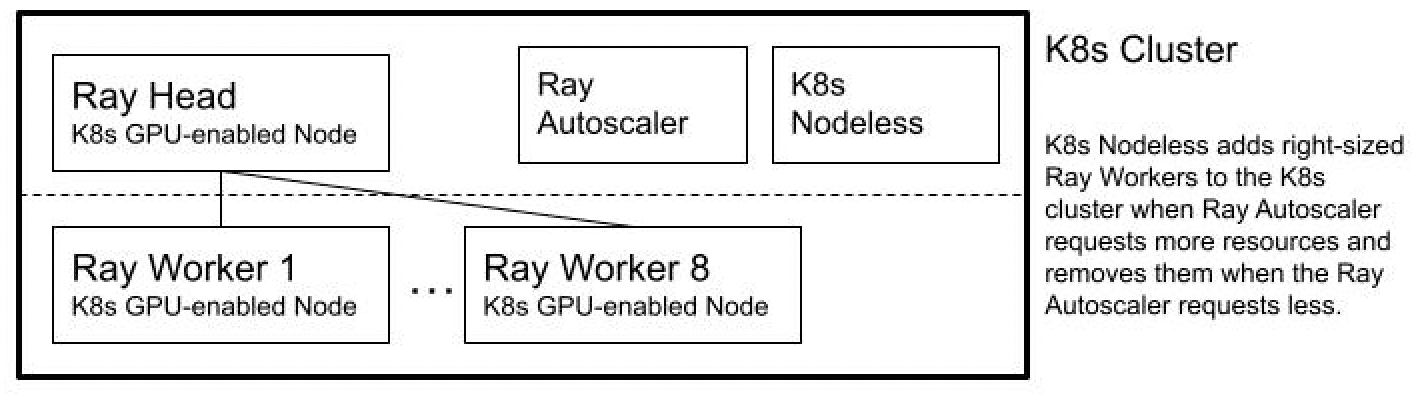
We compared the validation workload running on this configuration to running on two alternative configurations that use Nodeless K8s resource management on AWS EKS. The first was a Nodeless K8s cluster with a GPU-enabled Ray head and 0-8 GPU-enabled Ray workers, as shown in Figure 2.
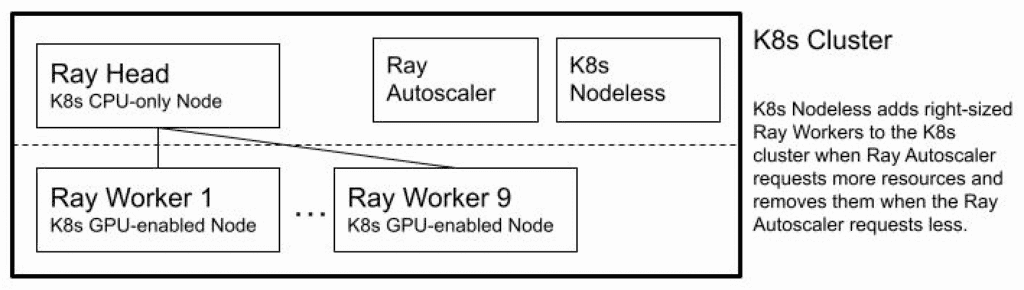
The second was a Nodeless K8s cluster, with a CPU-only Ray head and 0-9 GPU-enabled Ray workers, as shown in Figure 3.
We discuss the reasons for these configuration choices and we compare these configurations running the AutoML validation workload in terms of elapsed time, workload and idle computing cost, operational complexity, and AutoML results quality in the following three sections.
BASELINE
Configuration
Our baseline runs to evaluate AutoML effectiveness at specified time budgets were performed on a fixed-size three-node Ray cluster, with the head and two workers all on g4dn.4xlarge GPU instances. Our reasons for this configuration choice are as follows:
- We chose g4dn instances because Nvidia T4 GPUs provide a good cost/performance trade-off for our training workloads. We chose the 4xlarge variants because they had better availability than the less expensive variants at sample times we tried deploying.
- We chose three nodes, since we wanted to run each of our time-limited AutoML jobs on a standardized amount of computing resources, and we had experience with three g4dn instances working well at performing Ludwig AutoML’s default limit of 10 Ray Tune hyperparameter search trials. We note that the Ray head itself can run a Ray Tune trial.
- We chose non-spot instances, since we wanted to have a guaranteed amount of resources available during the time budgeted for the AutoML run.
- We chose a manually-launched fixed-size cluster, to avoid the risk that the instance types specified in the Ray cluster configuration file would not be available when the Ray Autoscaler requested them. Handling cases involving insufficient resources would incur operational overhead to detect the issue and retry with a different Ray configuration.
- We chose not to run multiple AutoML jobs at a time, i.e., not to deploy 6-node or 9-node Ray clusters, since we wanted to limit the GPU resource expense after the workload completed. Ray cluster shutdown is performed manually, often a day or more after the runs complete, to facilitate post-workload checks and follow-on runs using the same context, so the Ray cluster idle cost is an important consideration for us.
With this setup, we ran the three 1-hour runs serially (MushroomEdibility, ForestCover, Higgs), then the three 2-hour runs serially (same order), and then the three 4-hour runs serially (same).
AutoML Results
The AutoML model accuracy performance results run on the baseline configuration are shown in Table 1. The results are competitive with manually-tuned reference models.
| Dataset | Task | Rows | Cols | Reference Score | AutoML Score, 1hr, fixed-size | AutoML Score, 2hr, fixed-size | AutoML Score, 4hr, fixed-size |
| Higgs | bclass | 11,000,000 | 29 | 0.788 | 0.756 | 0.760 | 0.762 |
| ForestCover | mclass | 580,000 | 13 | 0.970 | 0.951 | 0.954 | 0.956 |
| MushroomEdibility | mclass | 8,124 | 23 | 1.000 | 1.000 | 1.000 | 1.000 |
Observations
The per-hour cost of g4dn.4xlarge instances is $1.204. Our serial baseline took 22.6 hours, which includes the 21 hours (3x1hr + 3x2hr + 3x4hr) budgeted for hyperparameter search, plus an additional 1.6 hours used for dataset load before each search starts and for evaluation of the best model produced per trial after each search ends. Hence, the overall cost for the baseline workload was $81.631. The idle cost for this Ray cluster is $3.612/hr.
We sought ways to reduce the workload elapsed time and cost, and also the cluster idle cost, while reducing operational cost as well.
With respect to reducing the workload elapsed time and the cluster idle cost, we wanted to apply auto-scaling with minimum workers set to 0 and maximum workers set to the value needed by simultaneous runs. However, to avoid introducing operational complexity, we wanted an auto-scaling solution flexible enough to find right-sized available workers automatically, which the combination of the Ray Autoscaler and Nodeless K8s provides. The Ray Autoscaler requests pod placement for scale-out when more workers are needed by the Ray cluster, and Nodeless adds appropriate nodes to the K8s cluster in response. And the Ray Autoscaler requests pod removal for scale-in when fewer workers are needed by the Ray cluster, and Nodeless then removes the associated nodes from the K8s cluster.
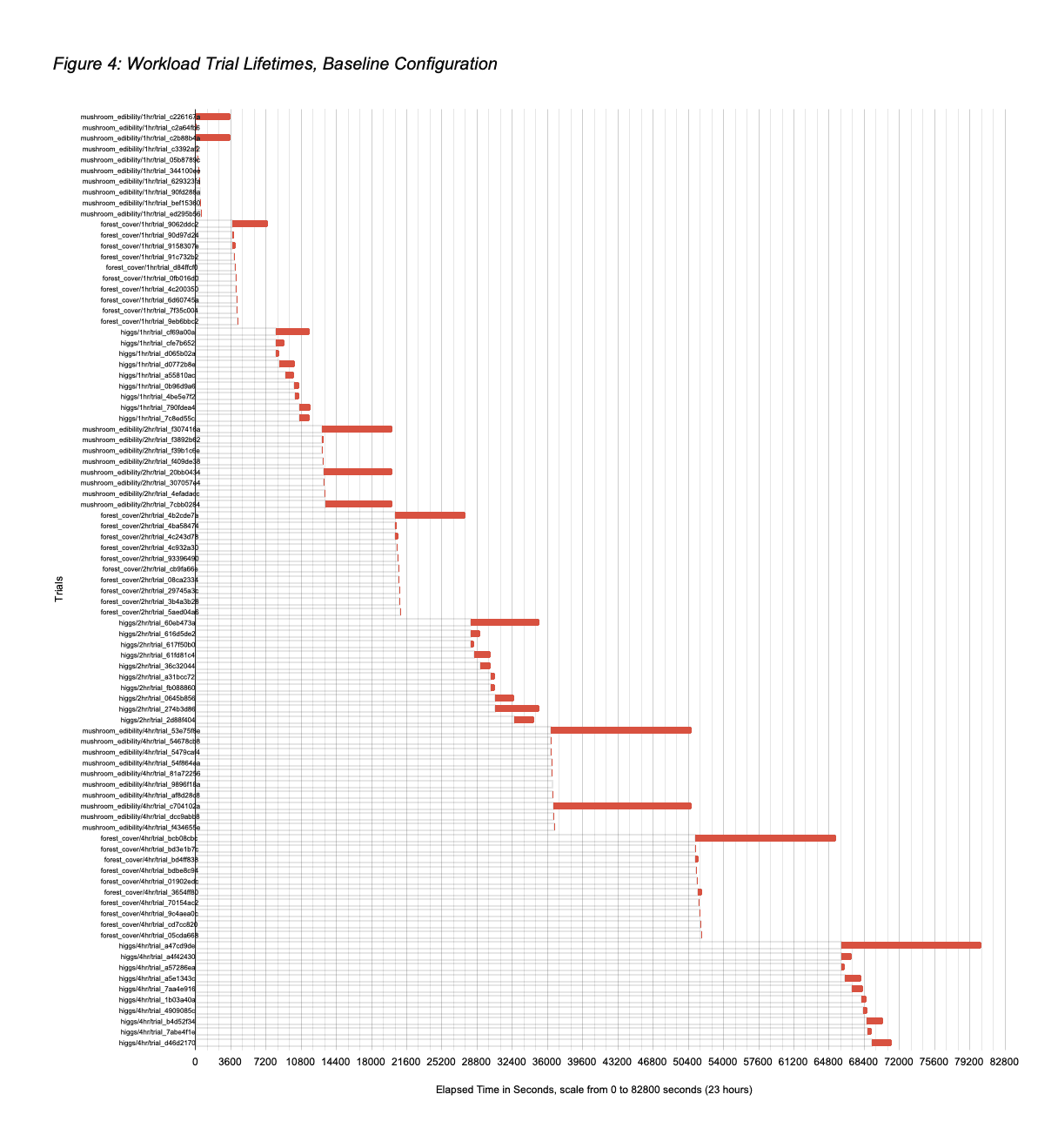
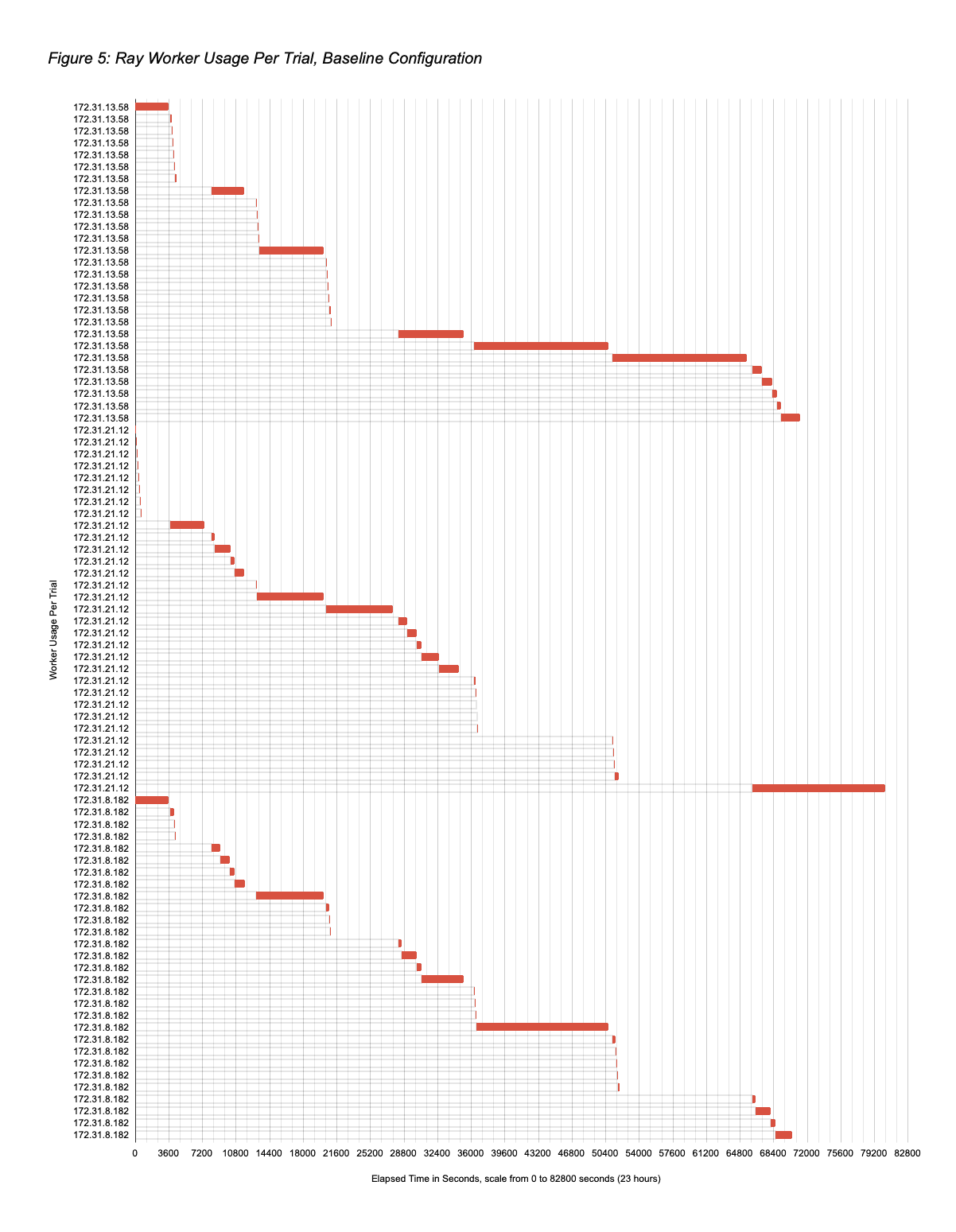
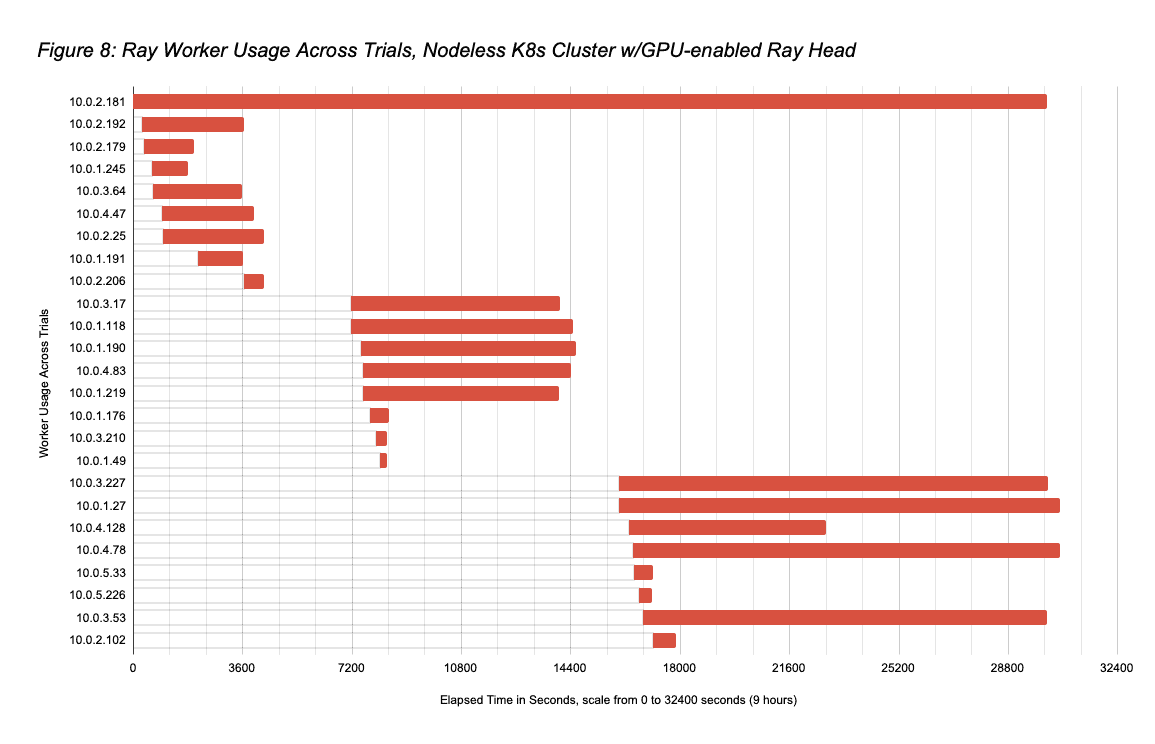
With respect to reducing the workload running cost, one obvious opportunity is that Ray workers are not needed during the 1.6 hours comprising pre-search dataset load and post-search per trial best model evaluation. A detailed analysis of resource use during the search itself exposed additional opportunities that the Ray Autoscaler plus Nodeless K8s combination can exploit. Figure 4 displays the lifetimes of the baseline workload trials, showing that there can be significant periods during the Ray Tune search in which all three workers are not needed. The reason is that Ludwig AutoML specifies that Ray Tune use the async hyperband scheduler, which terminates unpromising trials to avoid wasting resources on them. Depending on the dataset, many trials are short-lived, and once two or fewer of the maximum 10 trials remain to be explored, only a subset of the three workers is needed. Figure 5 displays how the three workers were used by the baseline trials over time, showing the idle periods.
In the next 2 sections, we present the results of applying the Ray Autoscaler with Nodeless K8s to this workload.
NODELESS K8s, GPU Ray Cluster
Configuration
With the goal of reducing the elapsed time and computing cost for the Ludwig AutoML validation workload, while also reducing operational complexity, we next ran the workload on a Nodeless K8s cluster with the Ray Autoscaler enabled.
- We set up an AWS EKS cluster with its resource limits set to the maximum of the organization’s GPU resources to be made available for this workload. We deployed Elotl’s Nodeless K8s in the EKS cluster to scale it up and down as needed.
- We deployed the Ray cluster on the EKS cluster, w/minWorkers=0 and maxWorkers=8, to allow the idle Ray cluster to run with no worker nodes. Recall that the Ray head itself can run a Ray Tune trial, so one worker is effectively available at all times. When the Ray Autoscaler requests additional worker pods, the Nodeless module automatically adds available right-sized resources to the K8s cluster without any manual operational overhead, and when the Ray Autoscaler removes worker pods, Nodeless removes the resources from the K8s cluster. We set the Ray Autoscaler idleTimeoutMinutes to 3, and ran with Ray version master@cc74037b2e7d6823c04df8f6989eede411725c07.
- In the Ray configuration, we specified that the resources for the head and workers be GPU-enabled. We included a Nodeless option to indicate that the g3 and g3s instance families be excluded from selection, because their older GPU processors do not perform well for our DL workloads.
- For each AutoML run, we set max_concurrent_trials to 3, to match the normalized AutoML job parallelism used in our baseline runs.
With this setup, we ran the three 1-hour runs in parallel, then the three 2-hour runs in parallel, and then the three 4-hour runs in parallel. Hence, in the fully-busy steady state, the Ray cluster was running with 9 nodes (the head and 8 workers).
AutoML Results
The model accuracy performance results, shown in Table 2, are comparable (within 2% noise) to the fixed-size cluster.
| Dataset | Task | AutoML Score, 1hr, fixed-size | AutoML Score, 2hr, fixed-size | AutoML Score, 4hr, fixed-size | AutoML Score, 1hr, nodeless | AutoML Score, 2hr, nodeless | AutoML Score, 4hr, nodeless |
| Higgs | bclass | 0.756 | 0.760 | 0.762 | 0.756 | 0.760 | 0.768 |
| ForestCover | mclass | 0.951 | 0.954 | 0.956 | 0.947 | 0.957 | 0.955 |
| MushroomEdibility | mclass | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
Observations
Comparing this run to the baseline, we observe the following:
- Our parallel run took 8.75 hours, reducing the elapsed time by 61% from the 22.6 hours in the serialized baseline run, without requiring operational complexity around handling instance acquisition.
- The idle GPU resources remaining after workload completion and before Ray cluster shutdown were reduced from three nodes to one (the Ray head), since after the Ray Autoscalar removed the worker pods from the Ray cluster, Nodeless removed the associated AWS instances from the K8s cluster, reducing the per-hour idle cost of the cluster by two-thirds, from $3.612 to $1.204.
- Unlike the baseline, where we specified the instance type for the Ray head and workers, in this case we specified the resources needed for each and the Nodeless module selected available AWS instances that satisfied those needs. We specified that the Ray head and each worker have 7 CPUs, an Nvidia GPU, and 64GiB ephemeral-storage, and that the head has 50GiB and the workers each have 28GiB memory. Nodeless allocated a g4dn.4xlarge instance for the head and the more affordable g4dn.2xlarge instances for each of the workers. Hence, were all workers powered on for the entire run, this configuration would cost $63.175 (1×8.75hrs of g4dn.4xlarge at $1.204/hr plus 8×8.75hrs of g4dn.2xlarge at $0.752/hr), 22.6% less than the baseline cost of $81.631.
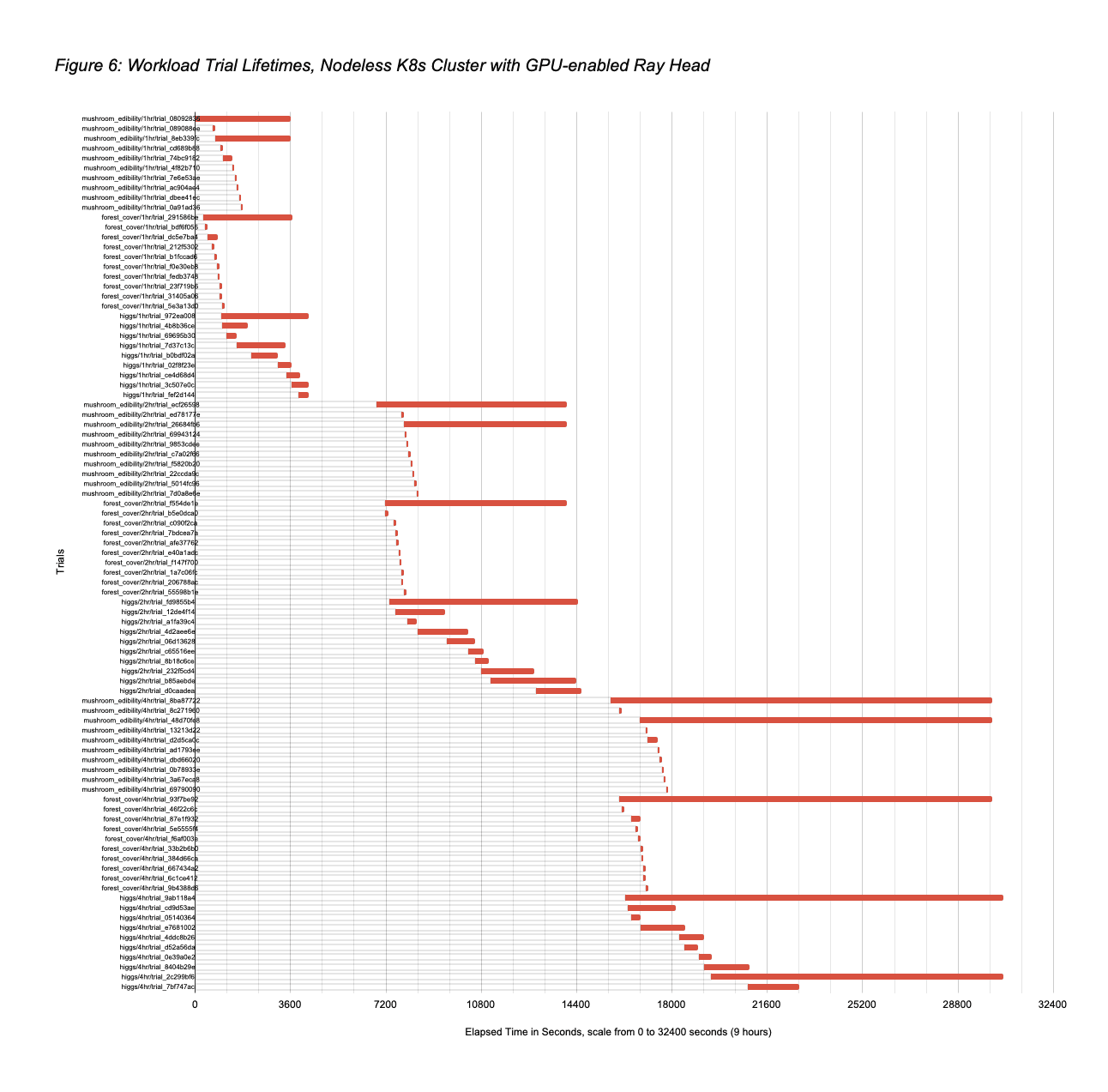
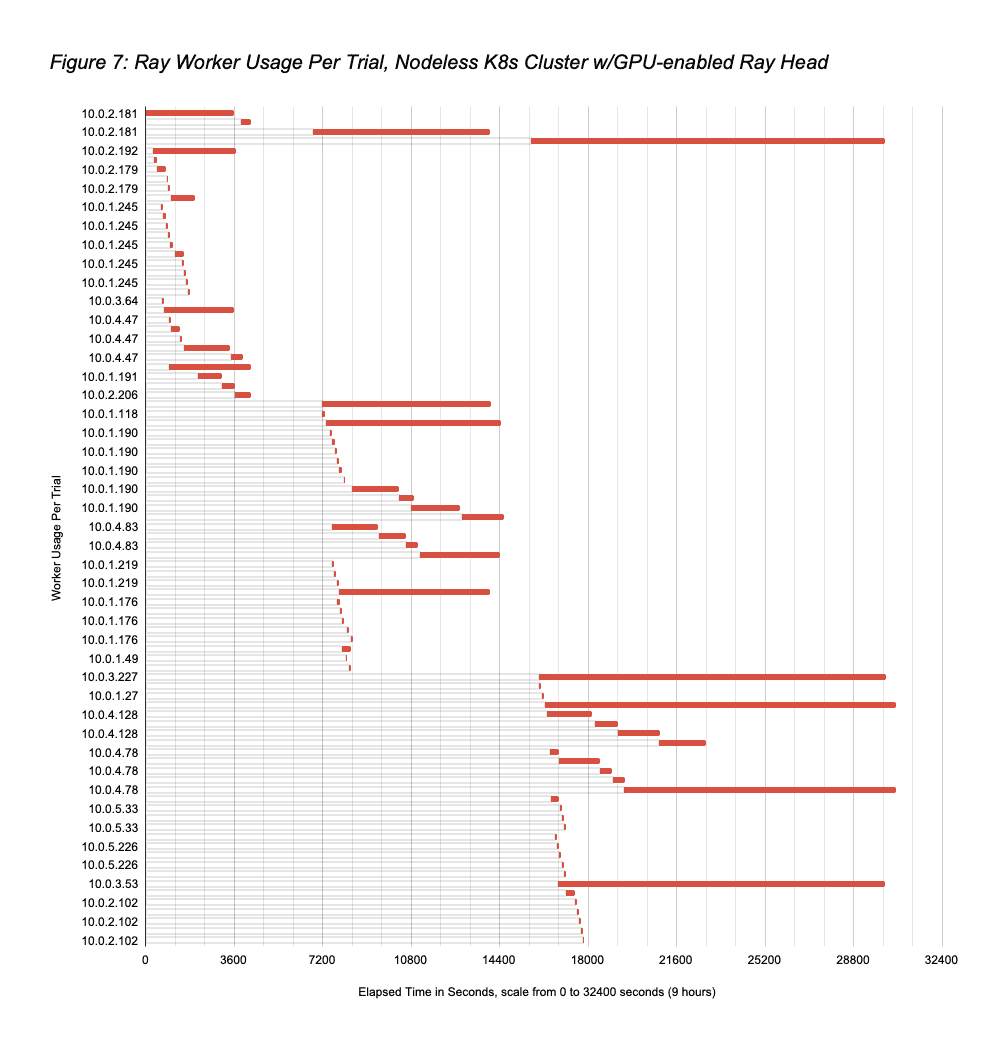
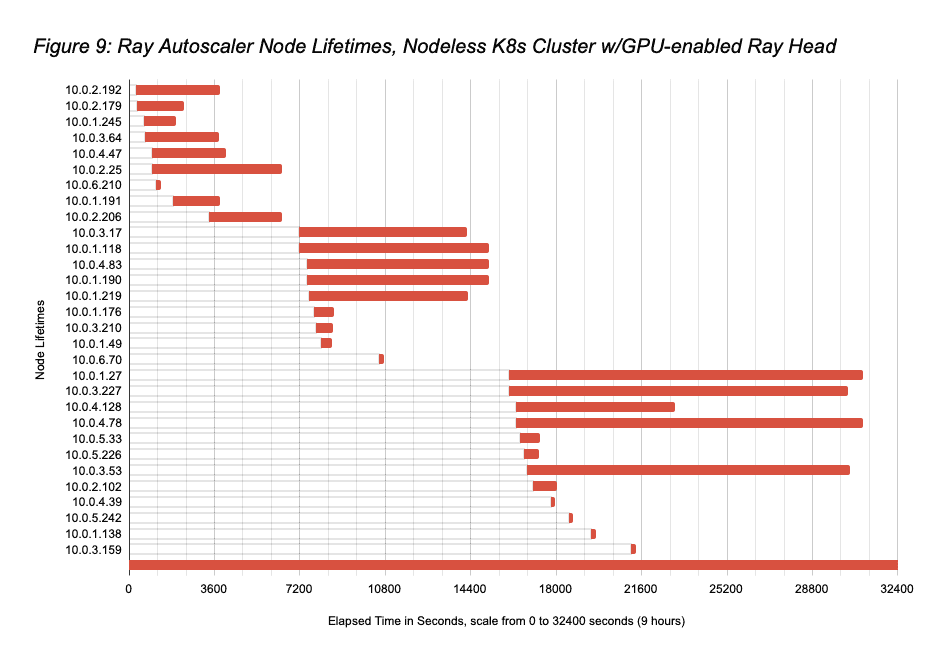
- However, this run was significantly less expensive than that since all workers were not kept powered-on for the entire run. Ray Autoscaler with Nodeless K8s exploited the opportunity previously discussed to spin down idle workers during the run. Figure 6 shows the workload trials lifetimes in this parallel run, which correspond to the baseline serial run lifetimes in Figure 4. Figure 7 shows how the workers were used by trials over time, with Figure 8 summarizing node usage across trials. Figure 9 shows the Ray Autoscaler operations to add and remove pods from the Ray cluster, in response to cluster load, with Nodeless performing associated allocation and deallocation of right-sized resources from the K8s cluster. The node running times sum from Figure 9 is 36.3 hours (substantially lower than the 70hrs if all 8 workers had been kept on for the full 8.75hrs), meaning that the total Nodeless run cost was $37.833 (1×8.75hrs of g4dn.4xlarge at $1.204/hr plus 36.3hrs of g4dn.2xlarge at $0.752/hr), 54% less than the baseline cost of $81.631.
- We note that node 10.0.2.181 is the Ray head node, which is why it is included in Figures 7 and 8 but not in Figure 9. We also note there were some instances where Ray Autoscaler requested workers (10.0.6.210, 10.0.6.70, 10.0.4.39, 10.0.5.242, 10.0.1.138, 10.0.3.159) that ended up not getting used by Ray Tune; these were quickly removed.
NODELESS K8s, GPU Ray Cluster w/CPU head
Configuration
While the Nodeless run described above reduced the computing costs and operational overhead of obtaining and freeing right-sized GPU nodes, the cost for the idle Ray head GPU resources remained after the workload ended. And the operational overhead of manually spinning down the Ray cluster to remove that GPU cost and redeploying the cluster when needed again remained; it would be simpler operationally if the Ray cluster head were left up.
To remove this remaining idle GPU cost and the operational overhead to avoid it, we reran the previous workload on a configuration in which the Ray head was deployed on a CPU-only node, with 0-9 workers being deployed on GPU-enabled nodes. We note that in this deployment, the AutoML jobs must explicitly request GPU resources, because by default, Ludwig AutoML only requests GPU resources if it observes them on the Ray head; this involves a minor change in the AutoML job parameters to explicitly request GPU resources. We also note that maxWorkers needed to be set to 9 (not 8), since in this case, the Ray head could not run any of the trials.
AutoML Results
The model accuracy performance results, shown in Table 3, were again comparable within noise to those of the fixed-size baseline.
| Dataset | Task | AutoML Score, 1hr, fixed-size | AutoML Score, 2hr, fixed-size | AutoML Score, 4hr, fixed-size | AutoML Score, 1hr, nodeless, CPU head | AutoML Score, 2hr, nodeless, CPU head | AutoML Score, 4hr, nodeless, CPU head |
| Higgs | bclass | 0.756 | 0.760 | 0.762 | 0.756 | 0.760 | 0.766 |
| ForestCover | mclass | 0.951 | 0.954 | 0.956 | 0.950 | 0.956 | 0.954 |
| MushroomEdibility | mclass | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
Observations
Observations for this run include:
- This run took 9.0 hours, which is 0.25 hours longer than the previous case, attributed to requiring more time to run the trials’ model evaluations on the CPU-only head vs the GPU-enabled head. That said, both cases significantly reduce elapsed time from the baseline 22.6 hours, without any operational complexity around instance acquisition.
- As in the previous case, Nodeless obtained g4dn.2xlarge nodes for the workers. Hence, were all workers powered on for this entire run, this configuration would cost $64.98 (1×9.0hrs of r5a.2xlarge @ $0.452/hr + 9×9.0hrs of g4dn.2xlarge at $0.752/hr) which is ~3% higher than the $63.175 cost for the previous case, but still substantially lower by 20.4% than the baseline cost of $81.631.
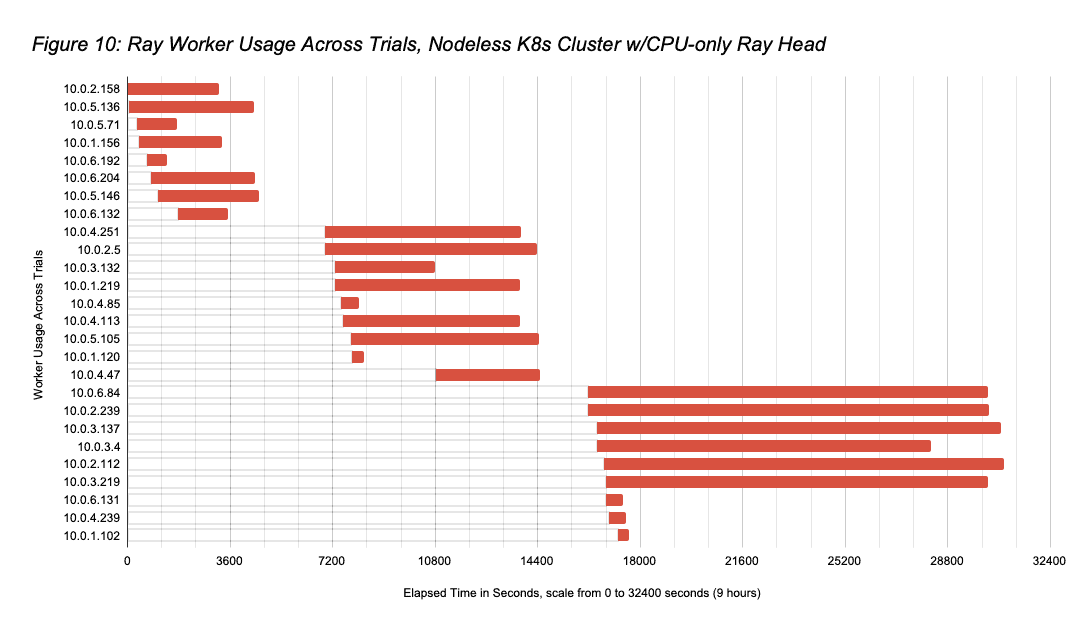
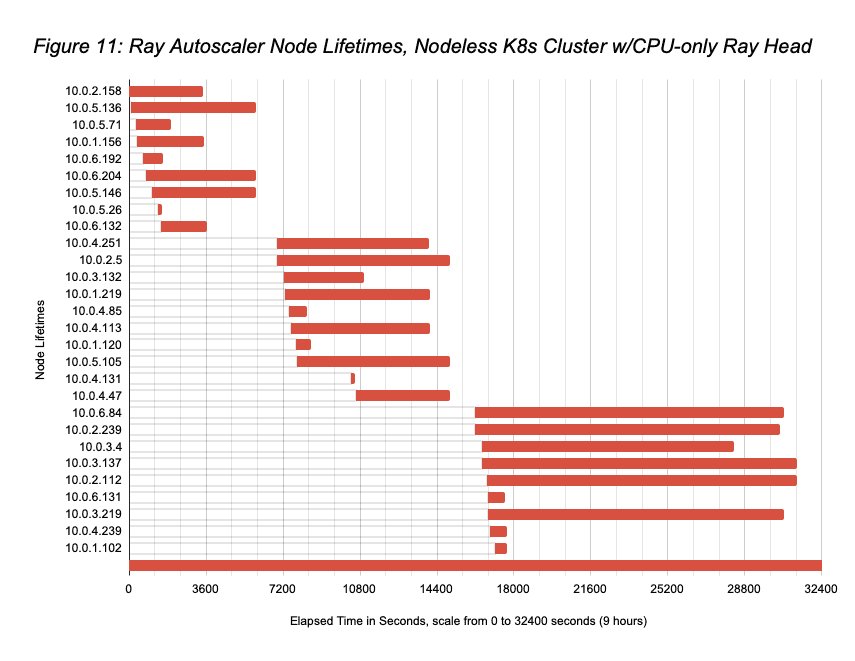
- But all workers were not kept powered-on for the entire run; Ray Autoscaler w/Nodeless K8s spun down idle workers dynamically. Figure 10 shows the node usage across trials, with Figure 11 showing the Ray Autoscaler / Nodeless scaling operations during the run (again, the Ray Autoscaler brought up a few workers [10.0.5.26, 10.0.4.131] that were not used and quickly removed). The sum of the running times of the nodes in Figure 11 is 44.1 hours (substantially lower than the 81hrs if all 9 workers had been kept on for the full 9.0hrs), meaning that the total Nodeless run cost was $37.840 (1×9.0hrs of r5a.2xlarge @ $0.452/hr + 44.1hrs of g4dn.2xlarge at $0.752/hr). This cost essentially matches that for the GPU-head Nodeless run, but with a substantially lower idle cost.
- The per-hour idle cost for CPU-only head configuration is $0.452, which is 62% less than the configuration with the GPU-enabled head, and 87% less than the baseline idle cost. This reduced cost was low enough to enable the simplicity of leaving the Ray cluster up.
LESSONS LEARNED
The Ray/Ludwig AutoML DL training experiments showed the value of using the Ray Autoscaler with Nodeless K8s. Table 4 lists key metrics from our experiments.
| Configuration | Workload Elapsed Hours | Workload Total Cost | Idle Ray Cluster Cost per Hr |
| Baseline Fixed-size GPU Ray Cluster | 22.60 | $81.631 | $3.612 |
| Nodeless K8s GPU Ray Cluster w/GPU-enabled Ray Head | 8.75 | $37.833 | $1.204 |
| Nodeless K8s GPU Ray Cluster w/CPU-only Ray Head | 9.00 | $37.840 | $0.452 |
Use of Nodeless K8s on a GPU Ray cluster with a GPU-enabled Ray Head reduced elapsed time by 61%, computing cost by 54%, and idle Ray cluster cost by 66%, while retaining the performance quality of the AutoML results. And operational complexity was reduced by replacing manual worker choice and static deployment with automated choice of less expensive available workers and dynamic scaling coordinated with Ray Autoscaler.
Further reductions in idle cost with respect to the baseline, with a minor configuration update, were obtained using a Ray cluster with a CPU-only head and GPU-enabled workers, with the idle cluster cost reduced by 87% vs the baseline. This idle cost reduction enabled lower operational complexity by replacing manual undeploy/redeploy of the Ray cluster, done to avoid GPU expense, with the convenience of keeping the Ray cluster always on.
These substantial savings in workload elapsed time, execution costs, idle costs, and operational complexity are expected to apply to a variety of DL training use cases.
SUMMARY AND FUTURE WORK
In this blog, we’ve shown how Nodeless K8s resource management can significantly reduce the elapsed time, computing costs, and operational complexity of Deep Learning training using Ludwig and Ray in the Public Cloud relative to manually-deployed fixed-size clusters. In future work, we plan to focus on demonstrating how Nodeless K8s can also improve these attributes for DL serving, which can have stricter latency requirements and shorter burst periods.
As future work, we plan to share a general comparison of Nodeless K8s resource management with other Kubernetes cluster Autoscalers.
If you would like to learn more about Nodeless Kubernetes and how it could help reduce operational complexity and wasted spend of your Kubernetes clusters along with improving multi-tenant security, please contact Madhuri at madhuri@elotl.co for a free trial.
If you would like to learn more about Ludwig and how to bring the benefits of low-code, declarative machine learning to your organization, please contact Travis at travis@predibase.com.
If you would like to learn more about Ray, please check out https://www.ray.io/.