


Guest post originally published on InfraCloud’s blog by Yachika Ralhan
We’re thrilled to share our newest OSS project ‘Krius’ with the cloud native community! Krius is a CLI tool to manage Prometheus, Thanos & friends across multiple clusters easily for scale. Infranauts have been working on this idea for the last few months and today we’re releasing an alpha version for you to try it out, give feedback and contribute to keep building new exciting features.
Why we built Krius?
Monitoring Kubernetes clusters’ and applications’ state is one of the most effective ways to identify issues, anticipate problems, and discover bottlenecks in environments. Many monitoring solutions are available that help aggregate metrics from across the distributed environment and deal with the ephemeral nature of containerized resources. There are proprietary solutions that are easy to get started but can be inflexible and costly in the long run.
Then there are open source solutions that are complex to configure and get started with, but can be fully customized and cost-effective once implemented. Now talking about open source systems, with all that customizable and cost-efficient power come challenges, and one of the biggest challenges is to set up / manage the whole monitoring stack in your cluster.
We have been helping our customers build their observability stacks, and believe us, building it rightly is a time-consuming process and not as smooth as you’d expect. So we created an open source system, Krius, which can easily install/manage our whole monitoring stack with simple configuration and a single command.
Introducing Krius
Krius is a CLI tool designed to install all the observability stack components (namely Prometheus and Thanos so far) needed for monitoring deployed applications in your Kubernetes cluster(s).
How does Krius help?
Krius deploys the entire observability suite into your Kubernetes clusters, so you can start monitoring and analyzing your applications’ usage and proactively act on alerts. Krius automates/facilitates the process of wiring all components together in case of complex deployment topologies.
For example, observing multiple clusters using Prometheus and setting up long-term storage or remote write your metric data to Thanos for a single pane of glass view across multiple clusters.
While the set of components and their configuration is highly opinionated by default. Krius is also highly extensible and configurable. Krius makes it easy to get started and gives you the flexibility to make the suite your own.
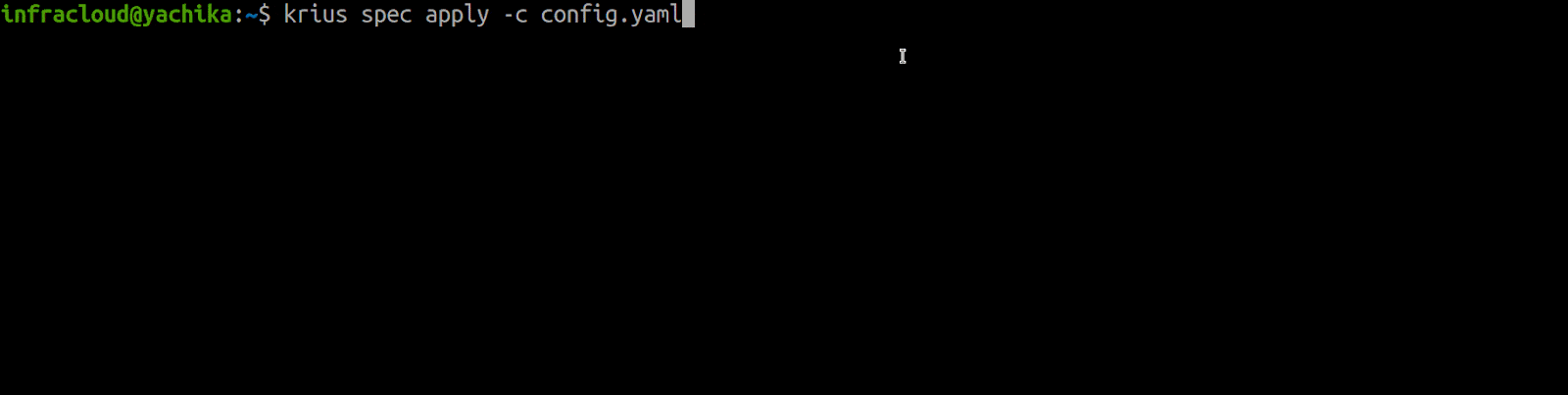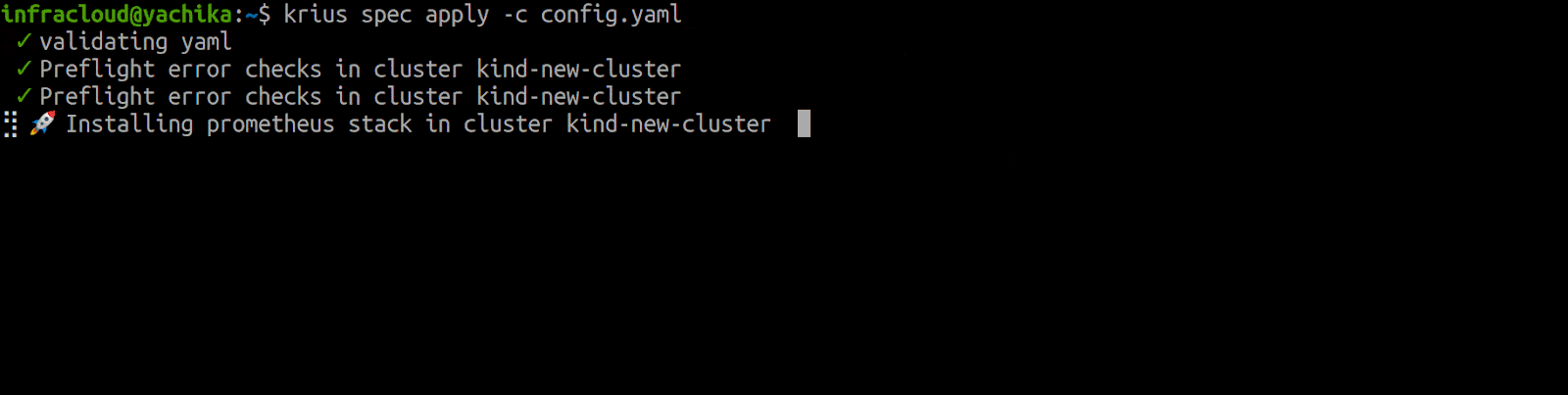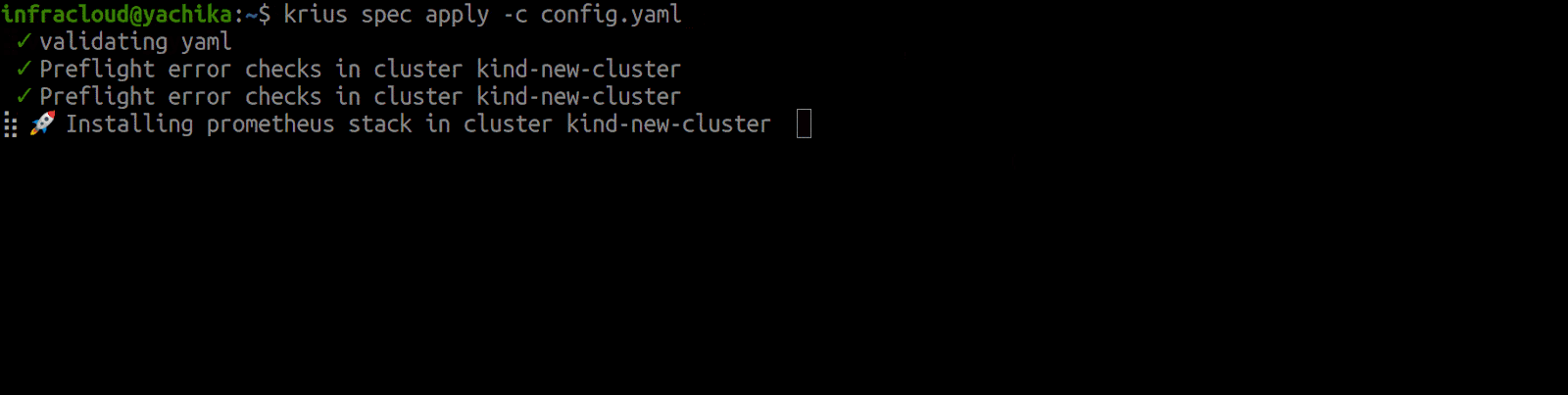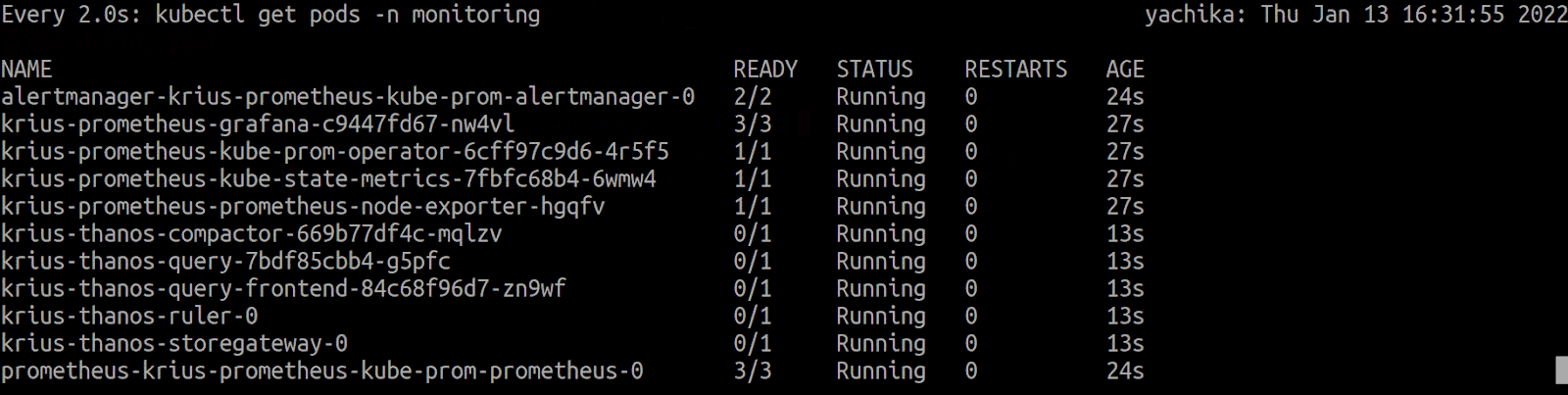
Currently, Krius can set up/manage the following components of the monitoring stack.
- Prometheus is an open source metrics-based monitoring and alerting toolkit. It has a multi-dimensional data model and has a strong query language to query that data model.
- Prometheus to collect metrics
- Node exporter to export metrics from the nodes
- kube-state-metrics to get metrics from Kubernetes api-server
- Alertmanager for alerting
- Grafana to visualize what’s going on
- Thanos is an open source system that helps enterprises achieve a HA Prometheus setup with long-term storage capabilities. Its components can be categorized as follows:
- Querier to gather the data needed to evaluate the query from underlying StoreAPIs
- Compactor to apply the compaction procedure of the Prometheus 2.0 storage engine to block data stored in object storage
- Sidecar / Receiver
- Ruler to evaluate Prometheus recording and alerting rules against chosen query API
- Querier Frontend implements a service that can be put in front of Thanos Queriers to improve the read path.
- Object Storage
- Prometheus, along with Thanos setup, supports any object store for long-term storage capabilities.
Features
- Install Prometheus and Thanos on a set of clusters without worrying about wiring to make them work together.
- Configure all Thanos components with ease.
- Easily modify the Thanos deployments to match your needs – whether it is more query load or more Prometheus instances to be configured etc.
- Simple config changes to swap the components of the observability stack; for example, if we want to replace the long-term object storage back-end from AWS S3 to GCP storage buckets, a minor config change will suffice.
Limitations
- Adding a Thanos sidecar to an existing non-Prometheus Operator (Helm) installation is not supported. Meaning if you have vanilla Prometheus configured without helm charts and now adding Thanos sidecar using Krius, that will not work.
- It does not create object storage; instead, it uses an already existing one.
Next Steps
- Support for multi-tenancy deployments in Thanos-Prometheus architecture
Take Krius for a spin
Krius works on a config file which is a single declarative state of the Monitoring Stack across multiple clusters. Apply the configuration spec using the krius apply command by putting the suitable configuration of your clusters, and then Krius does the rest.
A great way to get started with Krius is to try our GitHub repo’s installation and configuration instructions.
We’re excited to have you give Krius a try! Please feel free to let us know your feedback, thoughts, and use cases by creating issues on GitHub. Do start a conversation with us on Twitter on your first thoughts about Krius. Happy Coding!