
Guest post originally published on Humanitec’s blog by Aeris Stewart, Community Manager at Humanitec
Here are 5 things you need to know about implementing Kubernetes, based on Humanitec’s 2022 Kubernetes Benchmarking Study.
Knowing your way around a tool is key to putting it to good use. This applies to both your weekend hobbies and DevOps mainstays like Kubernetes. Just as you should not use a hand-wielded power drill to fix a motorcycle battery (example based on a true story, but I digress), you also should avoid using Kubernetes to do or fix just anything. Cultivating a thorough understanding of Kubernetes, and its limitations, is essential for successful implementation and usage.
That’s why we released the 2022 Kubernetes Benchmarking Study. With the adoption of Kubernetes continuing to pick up pace, more teams are integrating Kubernetes into their environments… and finding themselves disappointed with the results. We worked with more than 1,000 developer teams across the industry spectrum to assess their Kubernetes setup, focusing on three key aspects: the state of Kubernetes, technical approaches, and team setup and culture. From this, we developed a Kubernetes Performance Score (KPS) for each organization that allowed us to differentiate high, mid, and low performers.
5 main takeaways from our 2022 Kubernetes Benchmarking Study:
🥡 #1 : Get the technical implementation details right the first time
The road to Kubernetes hell is paved with uninformed expectations. A successful Kubernetes implementation requires a thorough understanding of the technology and its limitations.

Teams often implement Kubernetes with lofty expectations: that it is easy to use and maintain, that it will save the organization money, and that it is cloud agnostic… just to name a few. What most people fail to realize is that, in order to realize these potential benefits, you need the prerequisite functional systems and security expertise that previously was often trusted to multiple people with multiple career paths. Without a mature integration with CI/CD systems, appropriate documentation, or strong configuration management, Kubernetes implementation (like any technical implementation, really) can quickly become difficult. You have to get the technical implementation details right the first time.
🥡 #2 : Correct containerization is key

One stark difference between low- and high-performers was the degree of containerization of services and applications. More than 66 percent of high-performers had containerized all of their services whereas only 22 percent of low performers followed suit.
Of course, containerization is a massive topic, and it is a very easy thing to do wrong. As a mentor of mine noted, you can stick a database in the same container image as middleware and a front end and tell your boss, “It’s containerized, close that ticket”. It happens all of the time, and organizations gain nothing from Kubernetes in the process. These caveats aside, it’s clear that getting comfortable with containerization (and doing it correctly) is key to making the most of a container orchestration solution like Kubernetes.

🥡 #3 : Enable developer self-service
Enabling developer self-service for your Kubernetes setup is key to boosting developer productivity. Developer self-service, along with logical cloud-native architecture, means that engineers can self-provision and consume the tech they need to, test, secure, and deploy their apps and services, without having to wait on ops to provision resources or spinning environments for them. It does not necessarily mean developers need to be experts in everything and master their entire toolchain. It does not mean just anyone should be able to influence production infrastructure, either.
But when it comes to repetitive tasks, like spinning up new features or preview environments, for example, enabling developer self-service can save teams a huge amount of time and resources. Without developer self-service, you risk slowing down your whole development lifecycle, and increasing change failure rate, bottlenecks, and key person dependencies.
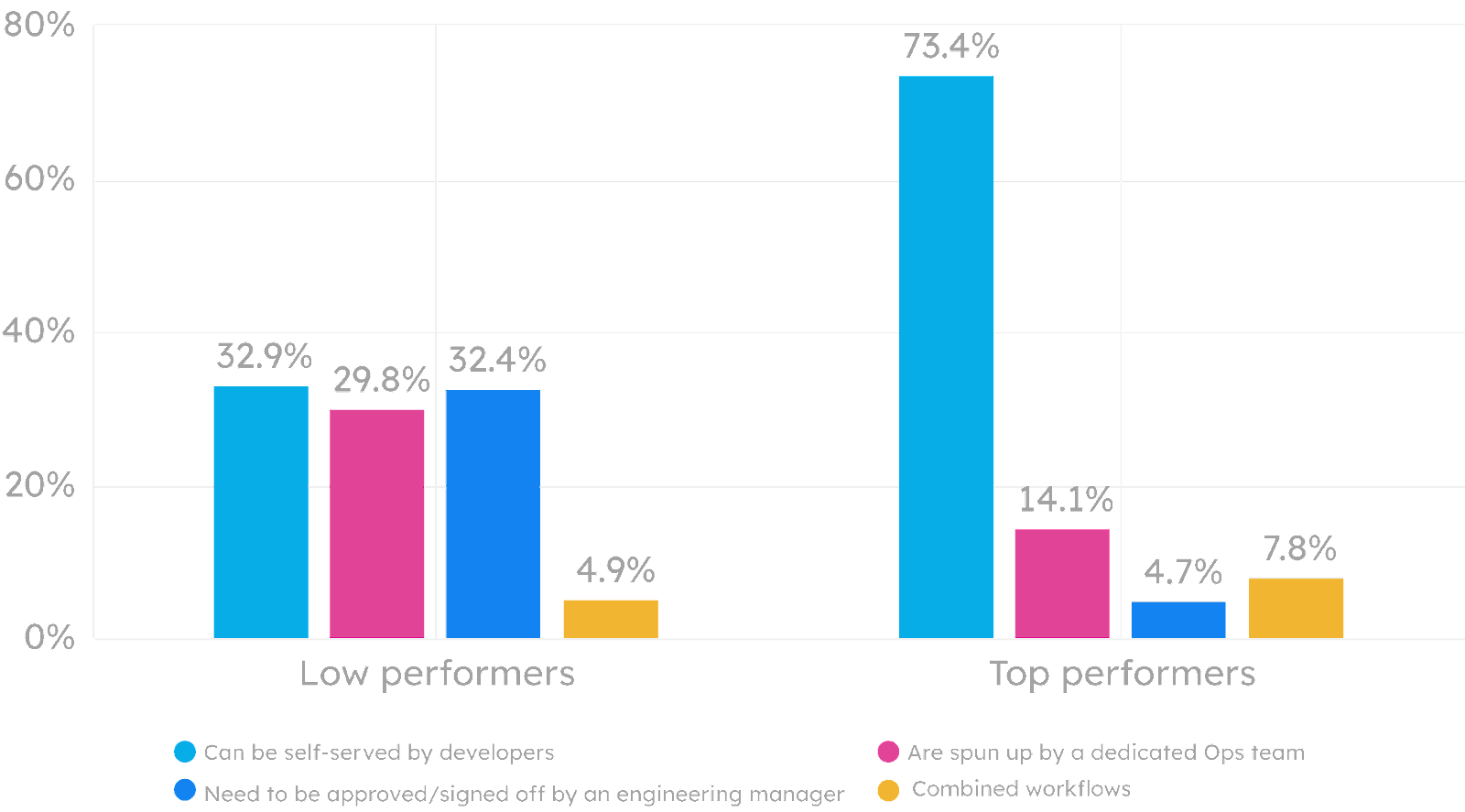
High performers provide a high degree of self-service. In these teams, developers can self-serve Kubernetes namespaces for feature and preview environments in 73.4 percent of cases. However, the same is true for only 33.3 percent of low performers.
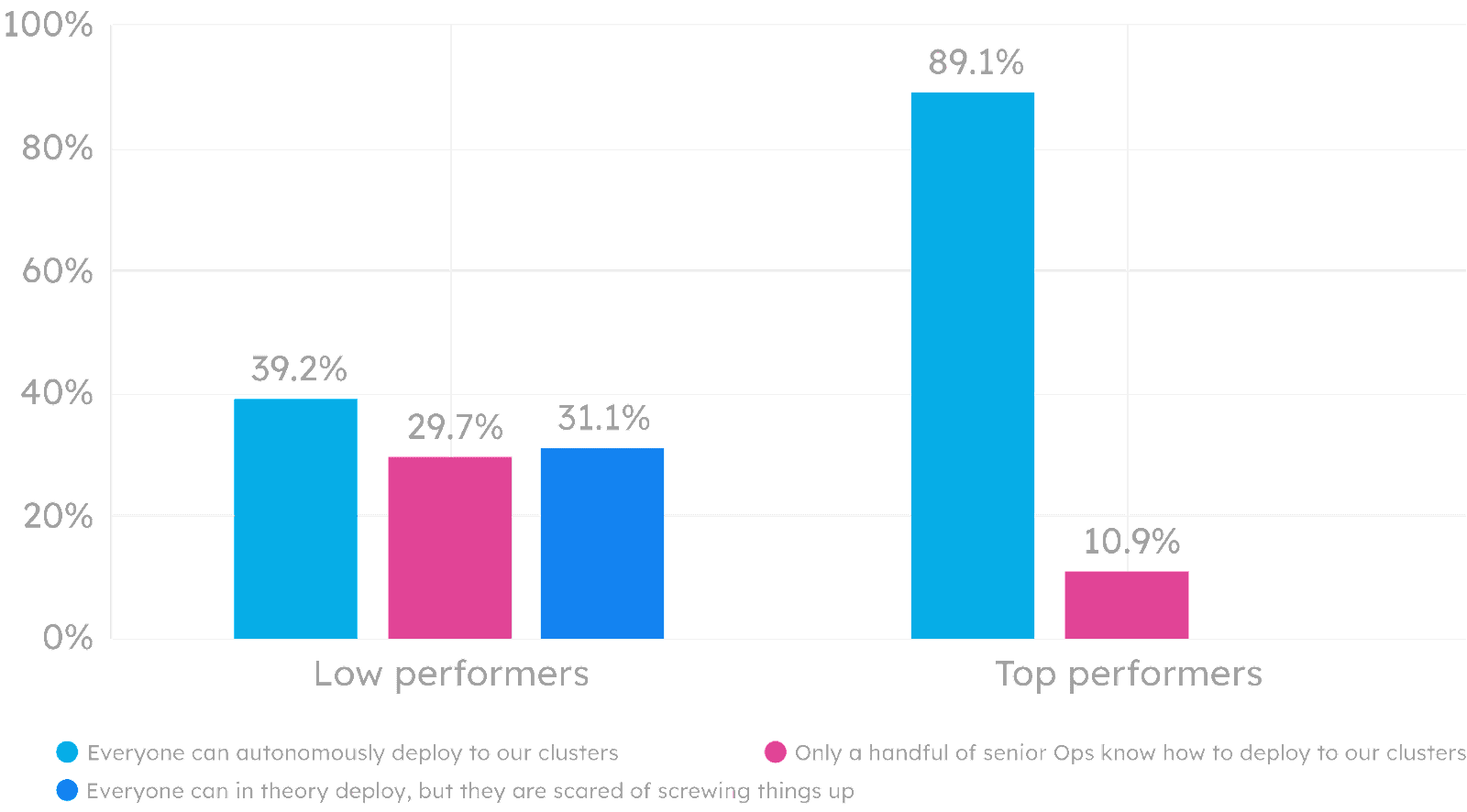
89.1 percent of high performers are able to deploy to dev or staging on their own and on demand. In contrast, only 39.2 percent of low performers reported that everyone can autonomously deploy to their clusters. 31.1 percent of low performers said that everyone can deploy to their Kubernetes clusters in theory, but in practice they don’t out of fear of screwing things up. In setups like these, lead time increases and deployment frequency decreases, all because the team is not able to deploy with confidence.
Let’s be clear: automated self-service deployments don’t necessarily fix underlying problems, and you should fix those problems before you try to adopt Kubernetes. You should be as comfortable with the idea of engineering developer self-service without Kubernetes as you are with it.
🥡 #4 : Leverage an Internal Developer Platform (IDP) to enforce Kubernetes best practices
There is a common misconception that adopting Kubernetes is equivalent to building your internal platform. While Kubernetes provides most of the building blocks you need for your setup, you can add more to solve your specific problems.
As Manuel Pais, co-author of Team Topologies explains in a recent blog post:
“Kubernetes is not your platform, it is just the foundation.”
Through our research, we found that high performing engineering organizations built Internal Developer Platforms (IDPs) to enable developer self-service. These IDPs allowed developers to interact independently with the underlying infrastructure and Kubernetes setup and, at the same time, abstracted complexity away from developers’ daily workflows.
This finding is in line with the results of other studies. Puppet’s 2020 State of DevOps Report showed a high correlation between an advanced DevOps evolution (characterized by low lead time, high deployment frequency, low change failure rate, quick MTTR) and the usage of an internal platform and self-service capabilities.
High performing teams enforce a strict separation between environment specific and environment agnostic configurations. Designed correctly, IDPs allow for these policies and best practices by default. They also provide additional layers that separate configs that are owned by the platform team from those developers are responsible for.
Well-designed IDPs not only help developers navigate Kubernetes itself, they also orchestrate dependent resources and manage their relationships to workloads running inside Kubernetes. Such standardization leaves less for developers to think about, eliminating unnecessary key person dependencies and waiting times and reducing developer’s cognitive load. With the right instructure around it, IDPs ensure flawless deployments, platform stability, increased developer confidence, and increased developer efficiency.
🥡 # 5: Keep learning, and don’t stop

Kubernetes is a powerful tool with a near-unlimited potential to improve your setup. The question is whether your team has the knowledge and skills required to implement and master it.
There are tons of free (and paid) tutorials and resources from Kubernetes experts that you can use to help your journey. I’ll link some of my favorites below:
- Humanitec’s 2022 Kubernetes Benchmarking Study
- LearnK8s
- Anais Ulrich’s 100 Days of Kubernetes
- Nigel Poulton’s Quick Start Kubernetes
- CNCF Training (Free)
- The Linux Foundation
- A Cloud Guru – Kubernetes Fundamentals