

Guest post originally published on Humanitec’s blog by Kaspar von Grünberg, CEO at Humanitec
We spoke to over 1850 engineering organizations last year. Most are planning to or already building an Internal Developer Platform. Here are the hardest lessons and fallacies we have seen these teams fall into.
Platform Engineering, Internal Developer Platforms and developer self-service in general are a rapidly growing trend.
According to Puppet’s State of DevOps Reports from 2020 and 2021 and our own DevOps Benchmarking Study, adopting these trends is what sets top performing engineering organizations apart from low performing teams. Internal Developer Platforms and developer self-service are generally seen as the best way to cross the chasm in an organization’s DevOps transformation.
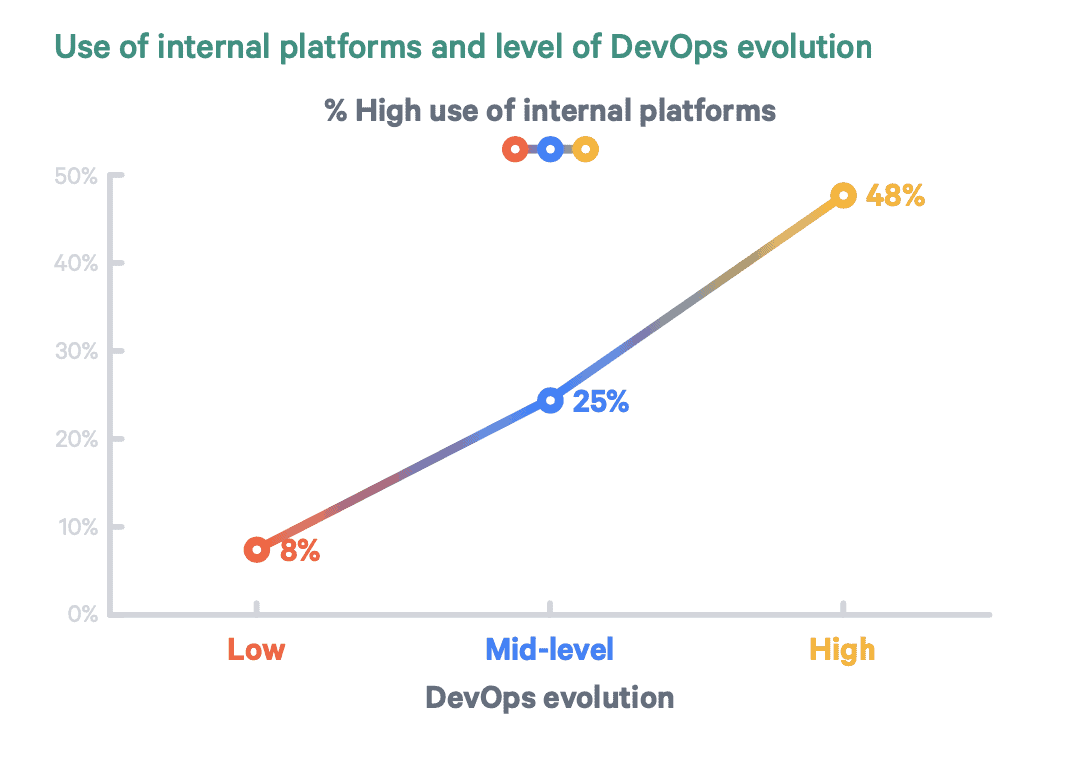
If you are new to this field, check out these two fundamental articles on platform engineering and the concept of Internal Developer Platforms.
I have personally seen 249 platforms in the making in 2021, giving me a unique perspective on how teams prioritize such endeavors, the common pitfalls and key mistakes. In this piece I am formulating my main observations, which I am planning to eventually roll up into a larger guide (or even a book) around platforming the enterprise.
A primer on platform engineering
Luca Galante defines platform engineering as
“the discipline of designing and building toolchains and workflows that enable self-service capabilities for software engineering organizations in the cloud native era. Platform engineers provide an integrated product most often referred to as an ‘Internal Developer Platform’ covering the operational necessities of the entire lifecycle of an application.”
So we’re ultimately working on gluing stuff together into an easy to digest Internal Developer Platform to balance cognitive load for software engineers so they can better handle the complexity of their setup. Developer self-service shouldn’t mean that you need 1,000 Kubernetes experts to run 1,000 different services around Kubernetes.
But where do you start? By reducing the number of CI tools from ten to three? By optimizing the onboarding process for developers? By abstracting people away from stuff? I’ve gathered the 10 most common mistakes teams make when starting with platform engineering.
#1 The prioritization fallacy
Unless you happen to work for Google, you probably have a limited budget and there is nothing you can do about it. It is insanely important you think long and hard about prioritization. 8/10 teams I speak to get this wrong and these mistakes are very costly. The most common example is teams that take the first thing that comes to mind in an application and development lifecycle and make this their highest priority, rather than looking at the entire lifecycle holistically. The majority of platform teams start by optimizing the onboarding experience and how to create a new application or service. But how often does that happen? If you take a step back and analyze the net gain of starting an app or service in relation to the total app lifecycle, this is simply neglectable. Of the time your team will invest in an application, the creation process is below 1%. Meaning the actual ROI on this part of the chain is too small to justify investments. The usual answer when I point this out is “yes, but we want templating”. And that’s fine. But do you really need a developer portal for that or might the templating functionality of Github just do fine?
Same applies for onboarding developers. Might it not be sufficient to simply run a script?
Mitigating this fallacy
So how do you think about prioritization the right way? I have a pretty easy rule of thumb. Take 100 deployments. Now ask your infrastructure, operations and application development teams:
- How often deployments are just a simple update of an image?
- How often do they spin up a new environment?
- How often do they onboard a new colleague?
- How often do they add a new microservice?
- How often do they change or add resources (databases, file storage, DNS)?
- How often do they add or change environment variables?
Once all that is noted down, ask them how much time they each spend whenever any of these activities have to be performed. For example “how long does operations need to provision a new database”? And what is the impact on dev teams because they have to wait? Build a table from all this information and multiply. You’ll get a great list of priorities to work against. It might look something like this:
| Procedure | Frequency (%of deployments) | Dev Time in hours (including waiting and errors) | Ops Time in hours (including waiting and errors) |
|---|---|---|---|
| Add/update app configurations (e.g. env variables) | 5%* | 1h* | 1h* |
| Add services and dependencies | 1%* | 16h* | 8h* |
| Add/update resources | 0.38%* | 8h* | 24h* |
| Refactor & document architecture | 0.28%* | 40h* | 8h* |
| Waiting due to blocked environment | 0,5%* | 15h* | 0h* |
| Spinning up environment | 0,33%* | 24h* | 24h* |
| Onboarding devs, retrain & swap teams | 1%* | 80h* | 16h* |
| Roll back failed deployment | 1,75% | 10* | 20* |
| Debugging, error tracing | 4.40% | 10* | 10* |
| Waiting for other teams | 6.30% | 16* | 16* |
*per 100 deployments
As a hint: we’ve analyzed more than 1850 setups across the world and it’s much more likely your team deals with configuration changes than it is to add a new service. That’s your answer right there.
#2 The visualization fallacy
Lee Ditiangkin just wrote the amazing article Put a pane of glass on a pile of sh*t and all your developers can see is a pile of sh*t. I just couldn’t agree more. Visualizing something that has flaws on the inside doesn’t take you anywhere. My favorite example is from one of the world largest online retailers. They invested a stunning 104 FTEs to build their platform. There, developers can start their morning browsing through open PRs and their apps. Every service is displayed in the catalog. Executives love such a dashboard experience. It also gives them the feeling to have transparency on who is the owner of which service. But it still doesn’t solve any problem.
In case a disaster strikes, executives say “I have no one to call, because we have full transparency now”. Sounds nice, but devs can just look into Github and other tools in their daily workflow. When disaster strikes they usually know exactly whom to call.
Such a solution doesn’t tell you what exactly went wrong and for which reason. The question should rather be how to reach a lower change failure rate.
So if you look at the actual usage data of their developer portal, you can see that people only log in to search other services as they start new ones. Which is, if you think of the first fallacy, rarely.
Mitigating this fallacy
Look into the mirror once a week and repeat after me: “I cannot run away from the nasty problems by just visualizing things in beautiful UIs”. Go back to the prioritization schema above and understand what actually moves the needle. In almost all cases you will see what really needs to be done: cleaning up your mess in app configurations and unstructured scripts that eat up time through maintenance and errors. A second thing is infrastructure orchestration and provisioning, as this often involves several different teams and thus creates waiting times.
#3 The “wars you cannot win” fallacy
You’re tasked with cleaning up the mess because your teams are using “too many tools”. The #1 victim are usually CI-tools. One team uses Jenkins, one Gitlab, one Azure DevOps. You construct that in the perfect world your team would only use one CI system. That might be true but the world is far from perfect. And teams hate the bare idea of this. Why? Because a.) they are used to this tool and it just works and b.) because porting tangled scripts from one platform to another is a huge distraction. There’s also not that much value to be found here. Building images is a plain commodity and testing and configuring these pipelines should be part of the team’s workflow anyway. The benefits from centralizing this is likely low in relation to the cost.
Mitigating this fallacy
Simple, restrict CI tools to building images, wire them up to a Platform API and centralize this piece and with it the connection to infrastructure and clusters. This has a sanitizing effect on the CI setup, you get the things you actually care about centralized and streamlined. And the developer experience is almost the exact same no matter what team you work in.
#4 The “everything and everybody at once” fallacy
The early 2010s were full of platform endeavors gone wrong. You don’t even need to look that far.
Transformations are almost never failing because of the wrong technology and almost always because of culture. As Courtney Kissler recently pointed out in one of our webinars, it’s a big myth that you just place a platform on top of your setup and devs will come by themselves and use it. But making it mandatory for everyone does not lead you to the goal either.
Cultural transformation is hard if you want to do this top-down, all at once and with a high degree of standardization. Hire armies of consultants to train developers in cloud-native and nothing happens. What you are doing is you are pushing people. People hate to be pushed. You throw some stuff together and then tell people to use it. We’ve been there and it just doesn’t work.
Mitigating this fallacy
Find a lighthouse team, spend a ton of time with them to get it right. Build ambassadors and evangelists from within, give them the time and freedom to influence the rest of the team. Start step by step, put as much time into prioritization and planning as in execution. Make it clear to your management that they need to lower roadmap expectations. SPEAK to your developers. Disney does a great job here. They regularly do toolchain hackathons during which teams optimize their setups and have an impact on the platform roadmap. Identify the future technologies you bet on and get this right. Is Kubernetes the future? That’s where you invest, while keeping the mainframe above the water.
#5 The “the new setup isn’t better” fallacy
This one is closely intertwined with the previous “all at once” fallacy. Teams tend to do too much at once (or are pushed to deliver faster than they can) and build a platform that is mediocre at best. New platforms have the problem that they are new (haha). Meaning people have to get used to them and they are by definition rough on the edges.
What is also difficult in terms of platforms: how do you find the MVP? As Alan Barr, Platform Product Owner at Veterans United, mentioned in a previous meetup:
“Platforms tend to be thick, they have to do a lot of stuff, you’re looking to replicate what you already have that works.”
In daily usage the little things just count and they take time. Many transformations fail because the new platform is new but it isn’t better than the previous solution. In such cases, there is no new functionality that really makes devs lifes easier. But nobody can really articulate why the sacrifice of an individual benefits the sanity of the wider organization. Your new platform has to be multiple times better than the previous setup or it will fail.
Mitigating this fallacy
Start small and with a real product mindset, I cannot emphasize this enough. Take a lighthouse application that is ahead of the pack anyways, is fully containerized, running on your optimal infrastructure stack. Now overinvest into this one setup like there is no tomorrow. Build something that is so much better that users become evangelists and other teams just want to have this badly. Do not try to build a platform that rules them all (see last fallacy). There is no nice experience across mainframes and Kubernetes. It’s a dream worth stopping dreaming about.
#6 The abstraction fallacy
Engineers hate to lose access to underlying technologies for the sake of abstraction. Many of us have seen days where ill-understood standardization attempts kept us from doing stuff and slowed us down. Ever worked with a super strict OpenShift instance where you are constantly waiting for central ops teams to figure out whether the option you requested should be standard? Do not fall into this trap. Abstraction shouldn’t mean restriction. Your colleagues will immediately hate you, not a great place to be in.
Mitigating this fallacy
Build golden paths not cages. What I mean by that is not that abstractions are wrong per se, but you have to want to use them. If they don’t work, a team should be able to circumvent them at any point in time. Let me give you a specific example: your infrastructure orchestration approach is firing off a default Terraform module if a developer requests a database. This has been vetted by security and works for most cases. Your developer has an eligible edge-case. Instead of shutting down the option to circumvent the default let them extend the model on their own. Nudge them to stay on the path by giving certain guarantees around not having to be responsible or on-call for pre-vetted setups.
#7 The “loudest voice” fallacy
That one’s juicy. Almost all teams I’ve ever met fell for this one. Take a random engineering team of 7 and you have this one character in there I call the Kernel Hacker. For this person something doesn’t exist if it’s not in a repository. She is reprogramming her toaster with an Aduino daily and asks her partner to marry her through bash scripts.
This person is very articulate around how the whole operations and delivery program is structured. Which poses a high risk of you optimizing the platform and the entire setup on the specification of this single person. Just because the self-confidence of this person shuts down everybody else. The problem is that everybody else has to operate the setup or else you fall into the below freedom fallacy.
Mitigating this fallacy
Good setups are designed for the weakest link in the chain and not the strongest. While you draft your strategy, while you prioritize your work, while you design your platform as a product, make sure you ask developers for input. Do not ask them in large conventions with high diversity. Rather ask a diverse group of people individually. If you place the hardcore SRE next to the JS developer you’ll get the wrong input. Beware of the abstraction fallacy. The Kernel Hacker shouldn’t be restricted. Make them part of extending the platform, bring them into working groups and make it crystal clear why certain things are done this way to serve the wider community rather than a few.
#8 The freedom fallacy
In a hysterical attempt to win the hearts of their engineering teams, Engineering Managers strip the last bit of standards and hand out AWS access to everyone. Central operations teams are a thing of the past and the power is shifted to the individual contributors.Yay, all of the downsides of working at scale with none of the benefits. I have not once seen this being successful, yet it’s being tried over and over again. You can literally observe how things go side-ways. First everybody is distracted, as they are now familiarizing themselves with the beauty of Helm, Terraform and ArgoCD. This also means they don’t get their job done. The majority of developers realize this eventually, shifting their focus back to the task at hand (writing a NodeJS application, which is hard enough). Not because they are incapable but because it doesn’t pay off to have 7/7 team members reach the expert level necessary. But somebody has to do the job so there is usually the one senior colleague taking care of everything. I call these people shadow operations. Long story short: you mark my words, your total productivity will drop at 15-25% during the next 12 months. Enjoy!
Mitigating this fallacy
Eliminating key person dependencies by enabling developer self-service shouldn’t have anything to do with throwing additional cognitive load on developers they are not able to handle. As Aaron Erickson, who built the Internal Developer Platform at Salesforce, says: “To run 1,000 different services on Kubernetes, you shouldn’t need 1,000 Kubernetes experts to do that.” Always optimize for the degree of cognitive load the team is able to handle.
#9 The “Google/Facebook/Netflix” fallacy
Provocative thought, but you are not Google, Facebook, Netflix, nor are you Spotify. That holds true on so many levels: you don’t have the funds, you don’t have the reach, you don’t have the scale. Also means you cannot and you should not copy what they do. Can they inspire you? Maybe.
But to be honest, you most likely don’t know their internal use case in detail. When people talk about Netflix, for example, few are aware that they mainly built just one big major service, as Nigel Kersten (Puppet) recently mentioned. Also, if your business operates in a highly regulated industry or critical infrastructure, “move fast, break things” is no good advice. The more talks we hear at fancy conferences, the more we risk comparing ourselves to setups we shouldn’t compare ourselves to. Let me give you another example. Lately everybody builds developer portals, optimizing for the case that you need a new microservice. There is a prominent product by one of these brands that makes this super convenient and easy – built for their own demand, not necessarily your’s. But wait, how often do you actually create a new microservice? Very, very often, if you are the global leader in streaming. Not very often if you are “Deutsche Bank”. These products also propose large scale models with even larger platform and central cloud ops teams. They work in very specific contexts but are unlikely to work in yours.
Mitigating this fallacy
Be super critical if anybody in your group or any consultant drives comparisons to any of these brands. The chances of this making sense are low. Join communities and talk to peers, make sure the setups are actually comparable.
#10 The “compete with AWS” fallacy
Your setup and your team, a very special snowflake, right? Why would you think that? Likely because you have no idea how snowflakes look on average. The brutal truth is that you aren’t. Let me give you an example: everytime I meet a team they say their Helm Charts are “super specific”. They end up being and doing the same thing in 99% of cases with a breathtakingly low deviation. Nothing about your setup is special. Thousands of companies have old data centers and some mainframes left. Everybody is struggling with Kubernetes. Do not worry. And, now I’m coming to the point, don’t take this as an excuse to build your own stuff. Everything you can let AWS do, let them do it. Do not reinvent the wheel. You will never beat their teams. They have the best engineers in the world on the topic and probably 1000 times the resources you will ever have.
Mitigating this fallacy
When building platforms focus on the stuff that is unique to your setup but use specialist tools wherever you can. If you want to build specialist tooling you should apply at Terraform, AWS or Humanitec, in any other case you should focus on the stuff that moves the needle. Sorry to be so frank but everything else is plain nonsense.
Where to start
It’s a lengthy piece but if you read it all the way through here, hopefully it provided you with some valuable insights. These are hard lessons I have collected throughout the past 2 years building Internal Developer Platforms with engineering teams of all sizes.
So where do you start now? First, remember to always take more time than you originally planned for to think really hard about the right things you want to prioritize when building your IDP, before you get going. You can’t spend too much time on this. Next, please don’t fall for the trivial visualization trap, you can use Lee’s piece title as a reminder: “If you put a pane of glass on a pile of sh*t, all you see is sh*t”. Finally, be prepared to sell your platform internally, sometimes the nice way, sometimes the hard way. Humans naturally resist change and you need to anticipate all the cultural questions that will come up as you will push to roll out your IDP.
Closing with a little disclaimer. This list is a first try, it will grow and I am planning to keep adding to it, as well as writing articles on the individual topics. I love to speak about this stuff, so please reach out if you have ideas, questions, arguments against what I said. The more we speak about this, the better off we all are.