

Project post by Volcano project maintainers
CNCF Volcano 1.6.0 is now available with new features such as elastic job management, dynamic scheduling and rescheduling based on actual resource utilization, and MPI job plugin.

Volcano is the first cloud native batch computing project in CNCF. It was open sourced at Shanghai KubeCon in June 2019 and accepted as a CNCF project in April 2020. In April 2022, Volcano was promoted to a CNCF incubation project. By now, more than 400 global developers have committed code to the project. The community is growing popularity among developers, partners, and users.
Key Features
Scheduling for elastic job
This feature, working with Volcano Jobs or PyTorch Jobs, accelerates AI training and big data analytics and reduces costs by using spot instances on the cloud.
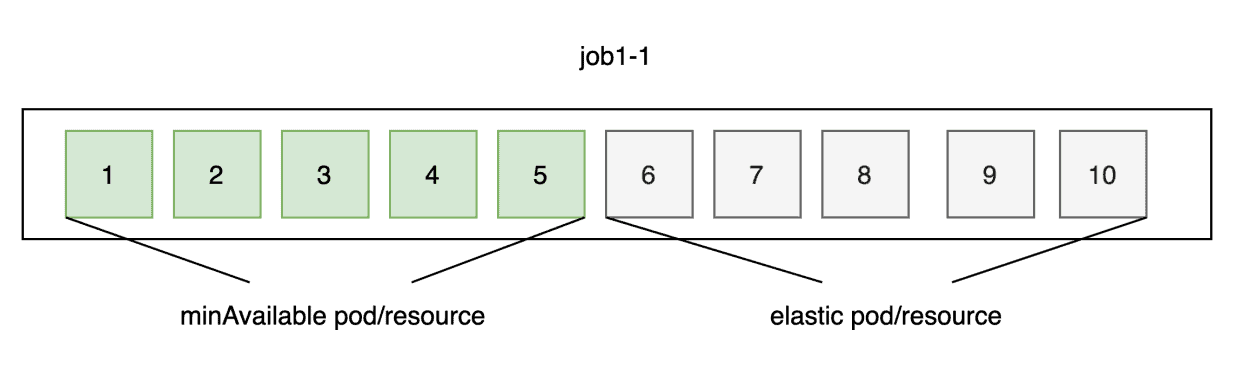
The number of replicas allowed for an elastic job falls within [min, max]. min corresponds to minAvailable of the job, and max indicates the number of replicas of the job. The elastic scheduling module preferentially allocates resources to the minAvailable pods to ensure that their minimum resource requests are met.
Resources, when idle, will be allocated by the scheduler to elastic pods to accelerate computing. However, when the cluster is resource-starved, the scheduler preferentially preempts the resources of elastic pods, which triggers scale-in. The scheduler also balances resource allocation based on priorities. For example, a high-priority job can preempt resources of an elastic pod of a low-priority job.
Documentation: https://github.com/volcano-sh/volcano/blob/master/docs/design/elastic-scheduler.md
Issue:
https://github.com/volcano-sh/volcano/issues/1876
Dynamic scheduling
The current scheduling mechanism, based on resource request and allocation, may cause unbalanced node resource utilization. For example, a pod may be scheduled to a node with a extremely high resource usage and cause a node exception, while there are some other nodes in the cluster that are not heavily used
In version 1.6.0, Volcano collaborates with Prometheus to make scheduling decisions. Prometheus collects data about cluster node resource use, and Volcano uses this data to balance node resource usage as much as possible. You can also configure the limits of CPUs and memory of each node. This prevents node exceptions caused by pods using too many resources.
Example scheduling policy:
actions: "enqueue, allocate, backfill"
tiers:
- plugins:
- name: priority
- name: gang
- name: conformance
- name: usage # usage based scheduling plugin
arguments:
thresholds:
CPUUsageAvg.5m: 90 # The node whose average usage in 5 minute is higher than 90% will be filtered in predicating stage
MEMUsageAvg.5m: 80 # The node whose average usage in 5 minute is higher than 80% will be filtered in predicating stage
- plugins:
- name: overcommit
- name: drf
- name: predicates
- name: proportion
- name: nodeorder
- name: binpack
metrics: # Metrics Server-related configuration
address: http://192.168.0.10:9090 # (mandatory) Prometheus server address
interval: 30s # (optional) The scheduler pulls metrics from Prometheus with this interval. 5s by default.Documentation: https://github.com/volcano-sh/volcano/blob/master/docs/design/usage-based-scheduling.md
Issue:
https://github.com/volcano-sh/volcano/issues/1777
Rescheduling
Improper scheduling policies and dynamic job lifecycles lead to unbalanced node resource utilization. In version 1.6.0, Volcano allows you to add rescheduling policies based on the actual resource utilization or custom metrics. Pods will be evicted from some high-load nodes to low-load nodes, and the resource utilization of all nodes will be periodically checked.
Rescheduling further balances the loads of each node and improves the cluster resource utilization.
## Configuration Option actions: “enqueue, allocate, backfill, shuffle” ## Add ‘shuffle’ at the end of the actions tiers:
- plugins:
- name: priority
- name: gang
- name: conformance
- name: rescheduling ## Rescheduling plugin
arguments:
interval: 5m ## (optional) The strategies will be called in this duration periodically. 5 minutes by default.
strategies: ## (mandatory) The strategies work in order.
- name: offlineOnly
- name: lowPriorityFirst
- name: lowNodeUtilization
params:
thresholds:
"cpu" : 20
"memory": 20
"pods": 20
targetThresholds:
"cpu" : 50
"memory": 50
"pods": 50
queueSelector: ## (optional) Select workloads in specified queues as potential evictees. All queues by default.
- default
- test-queue
labelSelector: ## (optional) Select workloads with specified labels as potential evictees. All labels by default.
business: offline
team: test
- plugins:
- name: overcommit
- name: drf
- name: predicates
- name: proportion
- name: nodeorder
- name: binpackDocumentation: https://github.com/volcano-sh/volcano/blob/master/docs/design/rescheduling.md
Issue:
https://github.com/volcano-sh/volcano/issues/1777
MPI plugin
You can use Volcano Jobs to run MPI jobs. Volcano Job build-in plugins such as svc, env, and ssh automatically configure password-free communications and environment variable injection for the masters and workers of MPI jobs.
The new version of Volcano further eases your running of MPI jobs by providing the MPI plugin. No more worries about the shell syntax, the communications between masters and workers, or manual SSH authentication. You can start an MPI job in a simple and graceful manner.
Example configuration:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: lm-mpi-job
spec:
minAvailable: 1
schedulerName: volcano
plugins:
mpi: ["--master=mpimaster","--worker=mpiworker","--port=22"] ## MPI plugin register
tasks:
- replicas: 1
name: mpimaster
policies:
- event: TaskCompleted
action: CompleteJob
template:
spec:
containers:
- command:
- /bin/sh
- -c
- |
mkdir -p /var/run/sshd; /usr/sbin/sshd;
mpiexec --allow-run-as-root --host ${MPI_HOST} -np 2 mpi_hello_world;
image: volcanosh/example-mpi:0.0.1
name: mpimaster
workingDir: /home
restartPolicy: OnFailure
- replicas: 2
name: mpiworker
template:
spec:
containers:
- command:
- /bin/sh
- -c
- |
mkdir -p /var/run/sshd; /usr/sbin/sshd -D;
image: volcanosh/example-mpi:0.0.1
name: mpiworker
workingDir: /home
restartPolicy: OnFailure
Documentation: https://github.com/volcano-sh/volcano/blob/master/docs/design/distributed-framework-plugins.md
Issue:
https://github.com/volcano-sh/volcano/pull/2194
Links:
Release note: https://github.com/volcano-sh/volcano/releases/tag/v1.6.0
Branch: https://github.com/volcano-sh/volcano/tree/release-1.6
About Volcano
Website: https://volcano.sh
Github: https://github.com/volcano-sh/volcano
Volcano is designed for high-performance batch computing such as AI, big data, gene sequencing, and rendering jobs. The project has got more than 2400 Stars and 550 Forks on GitHub. 26,000 developers around the world join the community. Contributing enterprises include Huawei, AWS, Baidu, Tencent, JD.com, and Xiaohongshu.
Volcano supports mainstream computing frameworks, including Spark, Flink, TensorFlow, PyTorch, Argo, MindSpore, PaddlePaddle, Kubeflow, MPI, Horovod, MXNet, and KubeGene. A comprehensive, robust ecosystem has been developed.