
Project end user guest post by Bruno Barin, Software Developer, iFood
Introduction
iFood is a leading food delivery company in Latin America delivering more than 60 million orders each month. The growth iFood has experienced in the last few years forced us to break the existing monolith architecture into several micro-services bringing scalability but not without a penalty: complexity and additional points of failure.
This blog explores the iFood story on how we leveraged Chaos Engineering as a practice on our infrastructure using LitmusChaos.
Light up the darkness
Nothing is more fallacious than relying on infrastructure components taken for granted. Bear with me: Database servers go out of business, messaging brokers crash, the entire region of a cloud provider goes down due to a power outage, and network bandwidth drops sharply without notice.
We experienced this situation during the Brazilian Valentine’s day in 2020. Lockdown. The platform crumbled like a card castle. Needless to say, the impact on the business. Right after the outage, we decided to implement fallbacks and circuit breakers for all the services crucial to delivering an order to a customer. But the question was, how can we guarantee that the fallbacks and circuit breakers will work adequately during critical events? Wait and see what the future would bring us was not an option anymore.
All begins with the first step!
We started humbly: During the off-peak time, we gathered most of our engineering teams and started to break down the production environment: mainly services and databases. Of course, this approach was extremely helpful for us to understand how to adjust our fallbacks and understand which other side effects we might experience during outages of some components but involved a lot of people to perform those tests that was definitely error-prone. What was the number of pods of X service before the experiment? Did we reinstate the grants of the service’s user in the database after the tests? It’s just not scalable as we would wish. Manual tasks are tedious, and as nerds, we like to delegate boring and repeatable tasks to computers while we watch them, taking a sip of coffee. During this endeavor, we decided to implement chaos engineering as a practice at scale. The tools we used previously were very simple, but soon we confronted the need to expand the range of experiments. We wanted to see what would happen if the services had a CPU spike? How to drop a persistent connection to the database? How to simulate an AWS SNS outage? These were the questions that the other chaos engineering tools out there were not prepared to answer. Also, we were too lazy to develop experiments someone else might have already implemented. We were surprised when we came across the LitmusChaos tool that promised a broader range of experiments in a simple and controlled way. Exactly what we have been looking for! Immediately, we decided to implement LitmusChaos as our de facto tool for Chaos Engineering across all teams. One important aspect is to authenticate users to LitmusChaos and restrict the services in which developers can inject chaos.
The architecture can be seen below:
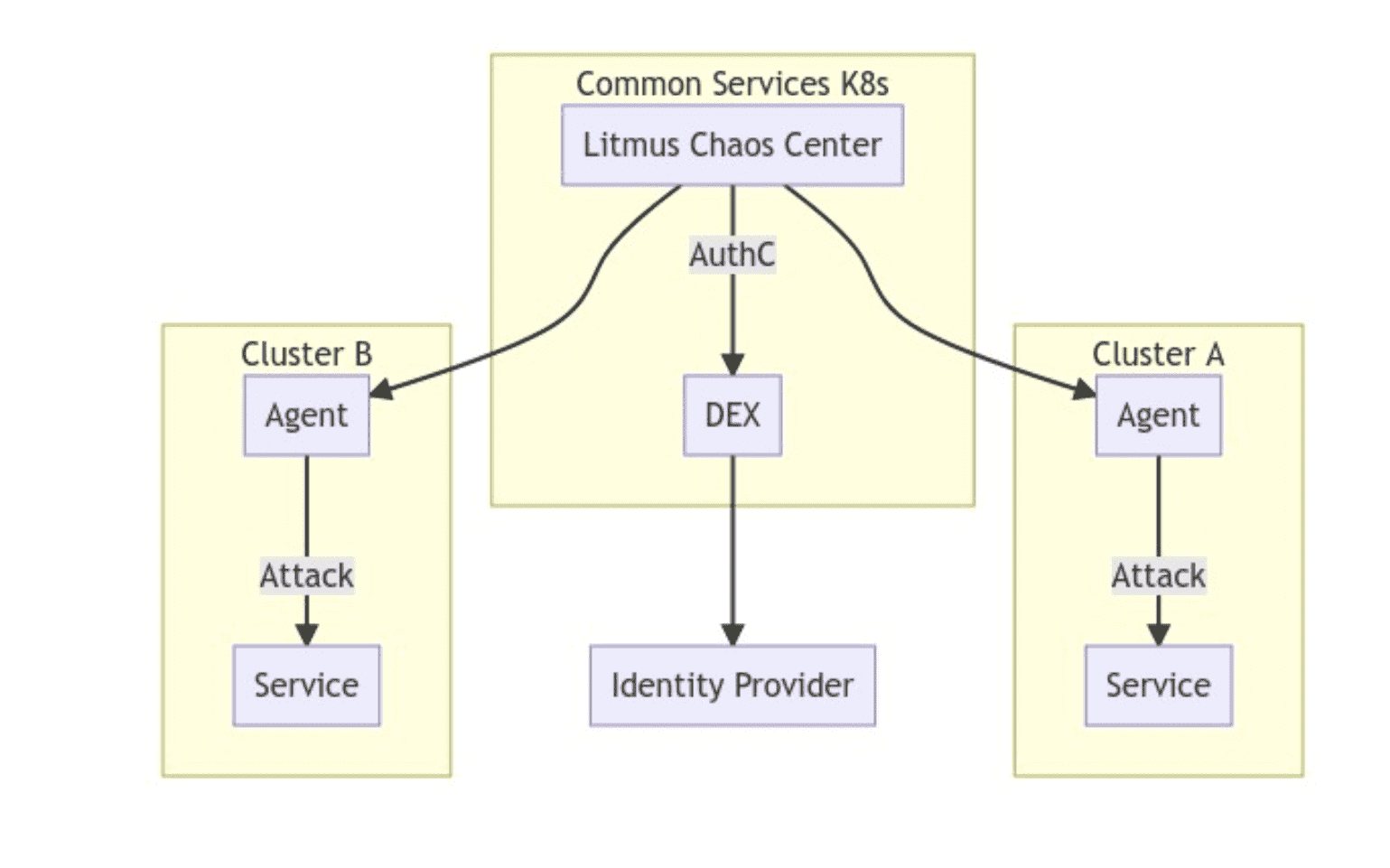
With this setup, we defined a 1:1 relationship between the LitmusChaos project and a K8s cluster, restricting the access developers might need to perform experiments on the clusters where their services are placed.
Next steps
We are pleased to be using LitmusChaos and are happy to be contributing back to the community like the audit details, which are very important to find out who performed the experiments. We look forward to having built-in LitmusChaos experiments with a broader range of user roles in order to grant permission only to a set of namespaces/deployments, and standardize the YAML of experiments – It wouldn’t be great if the description, blast radius, and other fields be part of the experiment itself instead of documenting them elsewhere?
We are excited to break things in production!!!