

Guest post originally published on the InfluxData blog by Charles Mahler
Developers are always trying to improve the reliability and performance of their software, while at the same time reducing their own costs when possible. One way to accomplish this is edge computing and it’s gaining rapid adoption across industries.
According to Gartner, only 10% of data today is being created and processed outside of traditional data centers. By 2025, that number will increase to 75% due to the rapid expansion of the Internet of Things (IoT) and more processing power being available on embedded devices. McKinsey has identified over 100 different use cases and potentially $200 billion in hardware value being created over the next 5-7 years for edge computing.
In this article, you will learn how Kubernetes is becoming one of the leading tools companies are using to implement edge computing in their tech stack. You will learn about the general benefits of edge computing, the benefits Kubernetes specifically provides to help with edge computing, and how KubeEdge can be used to optimize Kubernetes for edge computing.
Benefits of edge computing
The only reason to consider new technologies for your business should be that it actually drives value. Edge computing has a lot of hype and has become a buzzword to some degree, but what does it really mean for a business if properly utilized? Let’s take a look at some of the major benefits of edge computing.
Cost savings
For certain workloads with large amounts of data, it can be more efficient to process data at the edge rather than paying for the bandwidth required to process that data in the cloud. In some cases, computation can also be done on client devices like the user’s computer or smartphone to reduce load on your own servers.
You can also reduce the amount of data that you are paying to store long-term by doing real-time processing at the edge and then only sending lower granularity to the cloud for long-term historical analysis.
Improved performance
By moving computing resources closer to users latency can be reduced and users get a better experience as a result. This reduced latency and reduced bandwidth cost as a result of fewer round trips to data centers also mean new functionality and features become possible.
Improved reliability
A properly designed application that takes advantage of edge computing will be more reliable for end users. Even if network connection is lost to data centers, critical work can still be done using edge computing resources for things like IoT. Edge computing can help reduce single points of failure in your architecture.
Security and privacy protection
Edge computing can be used to improve both the security of your software and the privacy of your users. By keeping more data at the edge and away from centralized data centers, the blast radius for security breaches can be reduced compared to a more traditional architecture. On the other hand, having a large number of edge devices can also make security more challenging in some cases if proper security best practices aren’t followed.
Edge computing can also make following data privacy regulations easier. Rather than sending data to the cloud and storing it, processing can be done on the user’s own device or at the edge before being deleted or transformed to remove personally identifiable information.
Why use Kubernetes at the edge?
So you know there are a number of benefits to adopting edge computing, the question now is how to go about implementation. There are a number of potential solutions ranging from rolling your own platform or using a service provided by another company. Another strategy for handling edge computing is by using Kubernetes.
There are several advantages to using Kubernetes for edge computing, from both a technical and business perspective. From a technical perspective, K8s is already designed for working across data centers and dealing with issues that are similar to edge computing. Going from multi-region data centers to multiple edge locations isn’t that big a leap as a result.
From a business perspective, by choosing Kubernetes for your edge computing platform you get the benefits of the massive community which long-term saves you effort on building many common features and ensures the project is maintained and secure. You also get the benefit of having many developers familiar with Kubernetes which will make hiring and onboarding easier.
Kubernetes edge architectures
There are several different architecture options for how you can deploy Kubernetes for edge computing. Let’s look at some of the most popular options.
The first way to use Kubernetes for edge computing is to simply deploy an entire cluster at each edge location. This could be a high availability cluster if cost isn’t a huge factor, or a single server. Managing all these independent clusters brings some complexity with it and will require using a service from any of the major cloud providers or building your own custom tools to monitor and manage your clusters.
The next way to deploy Kubernetes is to only have a single Kubernetes cluster in your data center and then have your edge computing done by nodes deployed to each location. This setup is better for resource-constrained devices because the overhead of the control panel and other tasks performed by a Kubernetes cluster is managed in the cloud. The downside of this strategy is that networking becomes a bigger challenge because you need to be able to handle connectivity downtime and deal with syncing data between your control plane and edge locations.
The third major Kubernetes edge architecture is similar to the previous one, with the only difference being that edge processing nodes use some kind of very low-resource edge devices that handles passing data between the Kubernetes edge nodes and the devices themselves for processing.
Kubernetes edge computing distribution options
There are several options available for edge computing with Kubernetes when it comes to both architecture and which Kubernetes distribution to use. These distributions solve some of these problems that make it challenging to use standard Kubernetes for edge computing:
- Edge devices often don’t have enough hardware resources to support a complete base Kubernetes deployment
- Kubernetes by default doesn’t have great support to handle offline operation for devices
- No default support for protocols that don’t use TCP/IP like Modbus, UPC UA, or Bluetooth
To fill this gap in desired functionality, a few different Kubernetes distributions for edge computing have been created by different companies. The main options are K3s, MicroK8s, and KubeEdge. In the rest of this article, the focus will be on KubeEdge and the benefits it provides for using Kubernetes on the edge.
What is KubeEdge?
KubeEdge is an open source framework for edge computing built on Kubernetes that is an incubation-level CNCF project. KubeEdge helps developers deploy and manage containerized applications in the cloud and on the edge using the same unified platform. KubeEdge handles networking, deployment and data synchronization between edge and cloud infrastructure.
KubeEdge features and benefits
KubeEdge provides a number of features that make life easier for developers. Let’s take a look at a few of the most important features that make KubeEdge stand out for edge computing use cases.
Resiliency
One of the biggest challenges with edge computing and hybrid architectures is how to handle connectivity at the edge and how to synchronize data from the edge to the cloud. KubeEdge provides additional features on top of baseline Kubernetes to make this easier.
This will be looked at more in-depth in the architecture section, but an example would be that KubeEdge supports MQTT as a protocol for communication between edge nodes. MQTT was designed for IoT workloads and provides a number of ways to handle unreliable networks, which is just one way that KubeEdge makes edge computing simpler.
Low-resource footprint
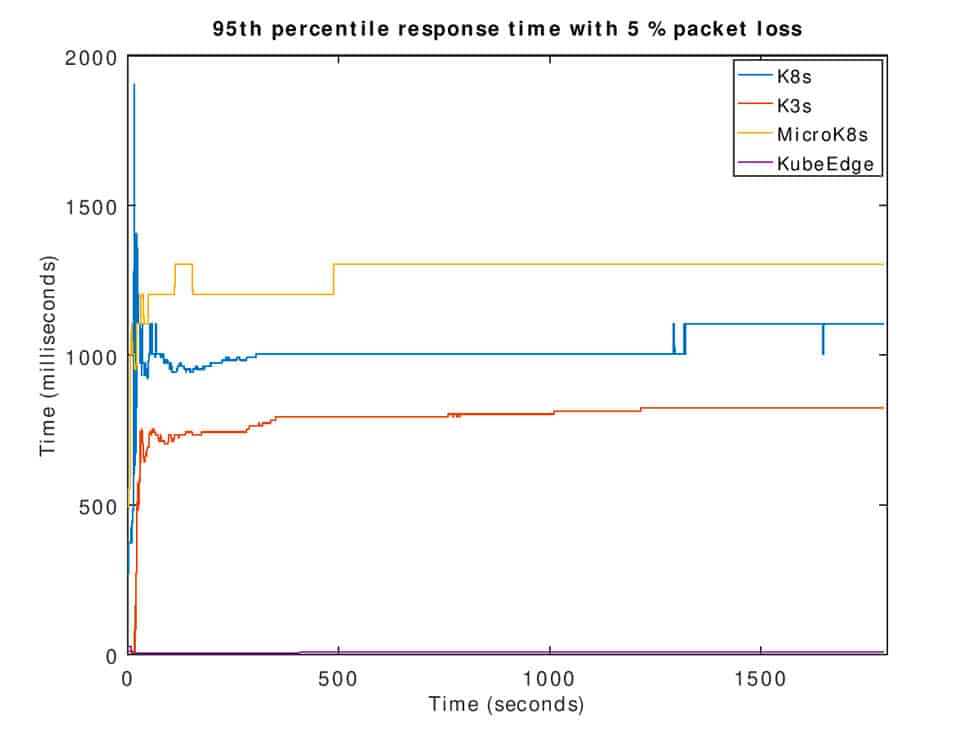
KubeEdge provides an edge component to communicate with the cloud Kubernetes cluster and deploy containers, which only requires 70MB of memory to run. While requiring a small amount of resources, KubeEdge is still able to outperform alternatives when it comes to request response time. This performance difference becomes even larger when dealing with unreliable networks involving packet loss. In these conditions Kube Edge was able to maintain a 6ms response time while K3s, K8s, and MicroK8s were close to a full second response time.
Scalability
A recent performance test showed that KubeEdge was able to successfully scale to 100,000 concurrent edge nodes and manage over 1,000,000 active pods on those edge nodes. This is compared to a default Kubernetes installation which according to their best practices documentation shouldn’t be used for anything over 5,000 nodes or 150,000 pods.
Security
KubeEdge places a large priority on keeping developers’ data secure. A recent independent security audit found no severe security bugs and only a handful of moderate-level vulnerabilities that were quickly patched.
KubeEdge architecture and components
KubeEdge’s architecture contains many different components, which are broken into Cloud and Edge components. In this section we’ll look at some of the major components for each side of KubeEdge.
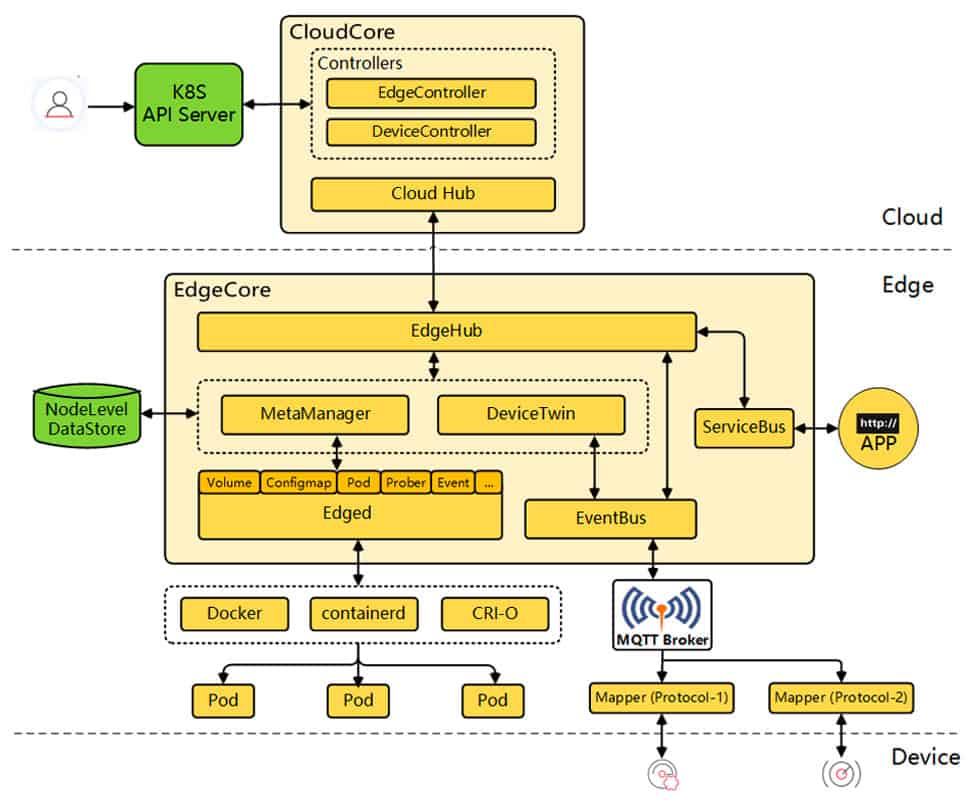
KubeEdge cloud components
KubeEdge cloud components all fall under what is called “CloudCore” which handles communication between the Kubernetes cluster via API and then communicates with the edge devices.
- CloudHub – Works by establishing a websocket connection with EdgeHub on edge devices and passes changes from the cloud to the edge
- EdgeController – Handles metadata for nodes and pods on the edge and allows data from cloud to be sent to specific edge nodes
- DeviceController – Similar to EdgeController and handles metadata for specific devices so data can be synced between edge and cloud
KubeEdge edge components
KubeEdge edge components fall under “EdgeCore” and handle communication between application containers, devices, and the cloud.
- EdgeHub – Connects to cloud via websocket and is responsible for passing data from devices back to the cloud and cloud data to devices
- Edged – The agent that runs on edge nodes and what manages the actual containers and pods running on edge devices
- MetaManager – MetaManager handles message processing between Edged and EdgeHub. MetaManager also provides persistence and querying of metadata via SQLite
- EventBus – MQTT client that allows edge devices to interact with MQTT servers and gives KubeEdge pub/sub capabilities
- ServiceBus – HTTP client that allows edge devices to interact with other services over HTTP
- DeviceTwin – Stores device status and syncs device status with cloud. DeviceTwin also provides the ability to query devices connected to KubeEdge
- Mappers – KubeEdge Mappers allow edge nodes to communicate over common IoT protocols like Modbus, OPC-UA, and Bluetooth.
KubeEdge use cases
Faster software deployment
The goal of KubeEdge is to bring Kubernetes and cloud native to edge computing. This means that developers gain all of the benefits associated with cloud native like faster deployments, fewer bugs, and more reliable software. Regardless of what type of application you are building, you will benefit from these at a high level.
Data storage and processing
A big reason for adopting edge computing is to allow data processing to be done faster and more efficiently by being closer to the source of where that data is being generated. Workloads at the edge often involve time series data and real-time processing of this data as sensors collect it.
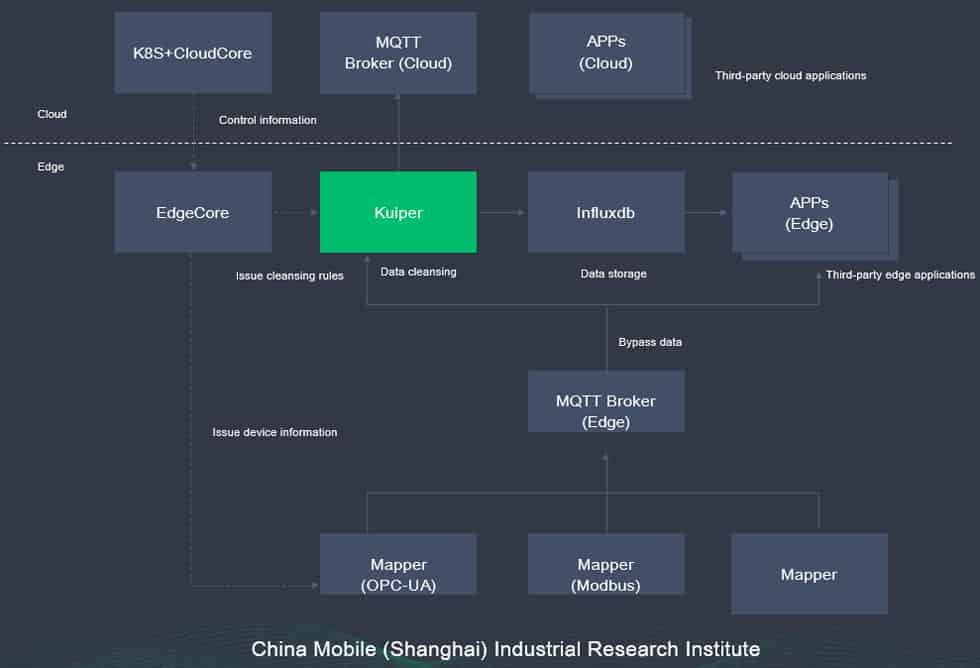
One example architecture from China Mobile shows how this can be done using KubeEdge. At the edge, Kuiper is used for processing data coming from an MQTT broker. That data is then stored on the edge with InfluxDB, an open source time series database ideal for edge workloads. Once stored inside InfluxDB, this data can be used for analysis, creating forecasts, generating data visualizations, or creating automated alerts and tasks. InfluxDB also has built-in edge data replication which can be used for mirroring your data back to the cloud from your edge instance.
Machine learning and AI
Deploying machine learning models is another common use case for edge computing. By moving your model to an edge device, you not only reduce bandwidth costs and latency but also gain the advantage of better privacy and security because data isn’t leaving the device or edge location to be analyzed.
KubeEdge provides its own toolkit called Sedna to make deploying models from popular machine learning frameworks like Tensorflow and Pytorch easier.
Getting started with KubeEdge
To get started with KubeEdge you will need a running Kubernetes cluster and hardware or VMs to act as edge nodes which are running Ubuntu or CentOS. Once that is set up, you can use Keadm to first install KubeEdge’s cloud components and then create a token which can be used with another Keadm command to install KubeEdge components on the edge device.
Another option for getting started with KubeEdge is to use KubeSphere, a Kubernetes distribution designed for multi-cloud and hybrid deployment. KubeSphere provides a component system to make adding functionality to Kubernetes easy and KubeEdge is officially supported. All you need to do is modify the default configuration file while installing KubeSphere and provide the IP addresses and ports for your Kubernetes cluster.
What next?
Once you have your KubeEdge-enhanced Kubernetes cluster running, you have a number of options available to learn more. One great resource is KubeEdge’s official example repo showing different use cases and real-world examples. These repos can be cloned and run on your hardware. Some good examples to check out:
- Edge data analytics – Setup Apache Beam at the edge for stream processing. This example could be used as a template and Beam could be replaced by any other stream processing tool.
- Face detection – This example shows how to deploy a service that uses OpenCV running on a Raspberry Pi with a camera module to detect faces and send that data back to the cloud.
- Virtual counting device – If you don’t have any hardware to act as your edge device, KubeEdge also provides this demo which provides a virtual device to generate data.
Beyond basic examples, case studies covering how companies are using Kubernetes at the edge in production and at scale are also useful. Here are a few resources to check out:
- Hong Kong-Zhuai-Macau Sea Bridge Monitoring – the HZMB bridge is the largest sea bridge in the world at 34 miles long. The bridge is monitored using KubeEdge via a series of towers along the length of the bridge. Each of these towers collectes 14 types of data, which includes CO2, light intensity, atmospheric pressure, noise, and temperature. KubeEdge is also used for deploying AI and other business applications for processing that data at the edge.
- China Telecom CDN – China Telecom is one of China’s largest technology and communications companies in China with a market cap of over 300 billion dollars. When rolling out a new CDN to reduce latency and improve performance of content and apps for over 360 million subscribers, they used KubeEdge as the foundation.
- Chick-fil-A – Chick-fil-A uses Kubernetes to manage their edge computing infrastructure that is located in each of their restaurants. Kubernetes was chosen because it gives them availability, low-latency at the edge, and the ability to iterate and deploy quickly.

The big takeaway here should be the versatility of how Kubernetes can be used for edge computing. Companies of all sizes across many different industries are taking advantage of the features provided by Kubernetes to make their software more efficient and reliable.