
Guest post originally published on Gemini Open Cloud’s blog by Patrick Fu

With the fine granularity and the plugin architecture of the new Kube scheduler framework, the default scheduler can be customized to handle different workload to increase performance and optimize the use of hardware resources. Workload scenarios like Gang Scheduling (Ref #5), Capacity Scheduling (Ref #6), and GPU Binpacking (Ref #7) can all benefit from the new scheduler framework, by implementing plugins to filter, prioritize, and bind tasks (i.e. PODs) to worker nodes to satisfy the requirements. Please see the corresponding references for details.
At Gemini Open Computing, we also leverage the scheduler framework to schedule Machine Learning and Inference jobs to optimize the use of GPU’s. Let’s explore.
Why we need to consider Accelerators in AI Workload
Accelerators like GPU have become extremely popular for Machine Learning (ML) in recent years, due to its ability to handle massively distributed computing tasks. Also due to the agility of container architecture and the abundant availability of ML framework images, the use of Kubernetes to manage clusters of ML workloads has also been very prevalent. We need to modify the default scheduler for ML workload because of 3 reasons:
1. GPU has significant impact to the performance of ML workloads
The default Kube scheduler considers only the CPU, Network, Memory utilization of the worker nodes. It does not consider the GPU utilization at all. In addition, the Accelerator computing is asynchronous, master/slave architecture, once the CPU hands off a vector computation to the GPU, it cannot interrupt the GPU even if the CPU becomes idle. Therefore, there is a high likelihood the default scheduler will not be able to select the best worker node for PODs running ML workload.
2. Ability for multiple PODs to share a physical GPU (GPU Partitioning)
Kubernetes cluster manager does not allow GPUs to be shared, meaning you have to assign the whole GPU to a POD during the entire ML workload. With GPU’s becoming more and more powerful in recent years, the GPUs are frequently under-utilized in ML computing.
3. Ability to do fair share scheduling
Depending on the specific type of machine learning, the use of GPU can vary greatly. We can optimize the use of the GPU’s by allocating a dynamic time fragment on a real time basis to improve GPU utilization.
GPU Partitioning
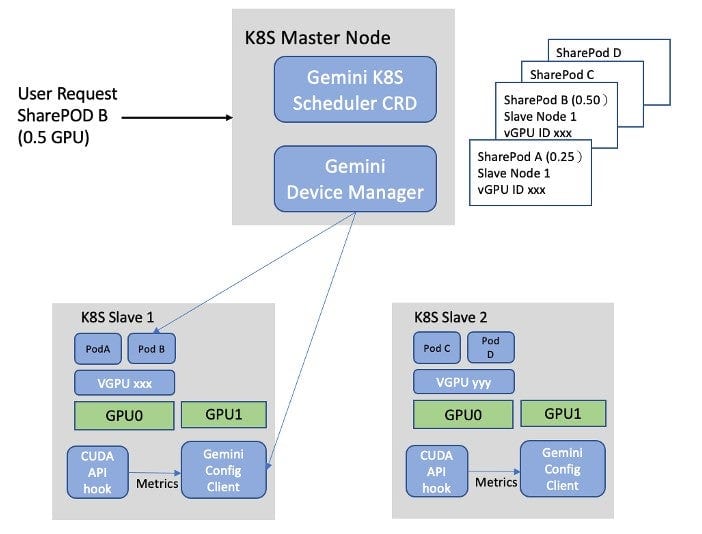
Gemini achieves GPU sharing by customizing the scheduler to TIME SLICE a physical GPU among a set of PODs (called sharePODs). Each sharePOD is part of an ML workload and can use up to a target % of physical GPU. The backend of the GPU partitioning scheduler implementation includes a device manager that maps the virtual GPUs to the physical GPUs. The device manager also keeps track of the physical GPU usage for each sharePOD.
From the user’s point of view, a sharePOD is just like a regular POD. A user just needs to specify a target % of a physical GPU this POD is allowed to consume. Gemini GPU partitioning scheduler includes a front-end on each worker node to monitor the GPU usage. The front-end will send the real-time usage of the POD to the scheduler backend, so it can decide the next POD to.
From the scheduler backend point of view, when the user creates a sharePOD with a partial GPU flavor, it will go through the set of worker nodes and bind a node with remaining capacity that satisfies the sharePOD. Thus, a set of sharePODs are bind with a worker node that shares the GPU. The front-end is a CUDA API hook library, which detects when the GPU is freed up. When that happens, the backend schedules the PODs that is waiting for the GPU as well as currently furthest away from its target utilization.
Figure 4 depicts the implementation of Gemini GPU Partitioning. When a user requests a POD with a partial GPU, the Gemini scheduler will allocate a sharePOD and ask the device manager to map this sharePOD to a worker node best suited for the request. Our customized scheduler includes a front-end to collect the actual GPU usage of the sharePOD and sends it back to the device manager to update the total consumption on a real-time basis. Thus, the Gemini scheduler backend can determine the next sharePOD to schedule this worker node.
We also designed a fair share scheduling policy. Please refer to our next article for more information.
Gemini Open Cloud is a CNCF member and a CNCF-certified Kubernetes service provider. With more than ten years of experience in cloud technology, Gemini Open Cloud is an early leader in cloud technology in Taiwan.
We are currently a national-level AI cloud software and Kubernetes technology and service provider. We are also the best partner for many enterprises to import and management container platforms.
Except for the existing products “GOC AI Console” and “GOC API Gateway”, Gemini Open Cloud also provides enterprises consulting and importing cloud native and Kubernetes-related technical services. Help enterprises embrace Cloud Native and achieve the goal of digital transformation.