Guest post originally published on the Miraxia blog by 川井拓真
Japanese version here.
Few weeks ago, I was struggling to optimize the Vertical Pod Autoscaler performance. We’d been planning a presentation in my company, and it should be 5 to 10 minutes long, so the default VPA behavior was too slow for us. Eventually, I had to modify its source to change pod’s resource requests dynamically in minutes.
In this article, I describe how VPA works and a way to optimize its performance, including code modification.
What is Vertical Pod Autoscaler?
The Vertical Pod Autoscaler, VPA, enables us to define resource requests dynamically. It observes the cpu and memory utilization of pods, and updates these resource requests at runtime.
How Vertical Pod Autoscaler works?
The VPA is consists of the following three components.
The admission-controller register an admission webhook to modify pod creation request.
The recommender checks the resource usage of the target pods, and estimate the recommended resource requests, then update the VPA object associated to the target pods. This process is performed periodically.
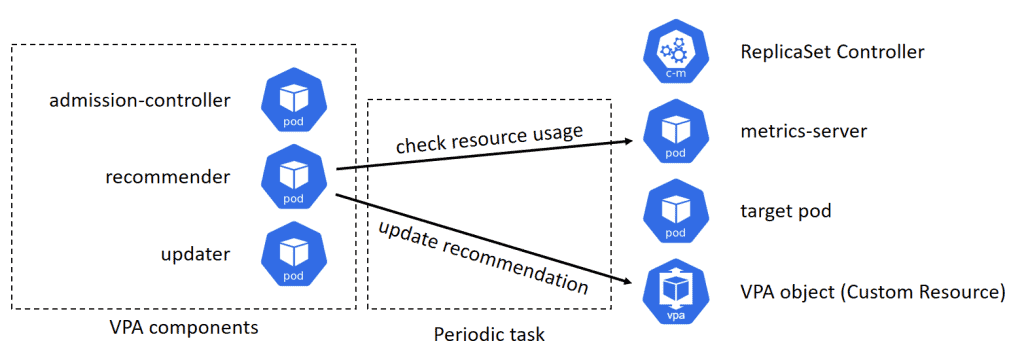
The updater checks the recommended resource requests recorded in the VPA object, and if the current resource requests of the target pod are not match with the recommendation, it deletes the pod.
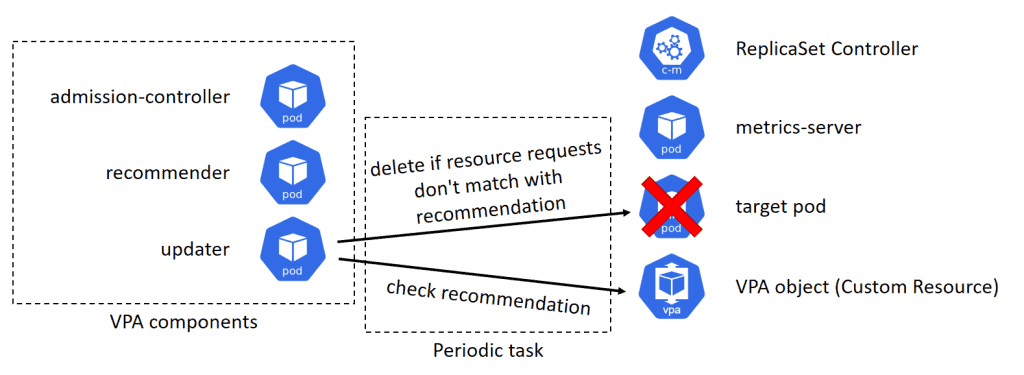
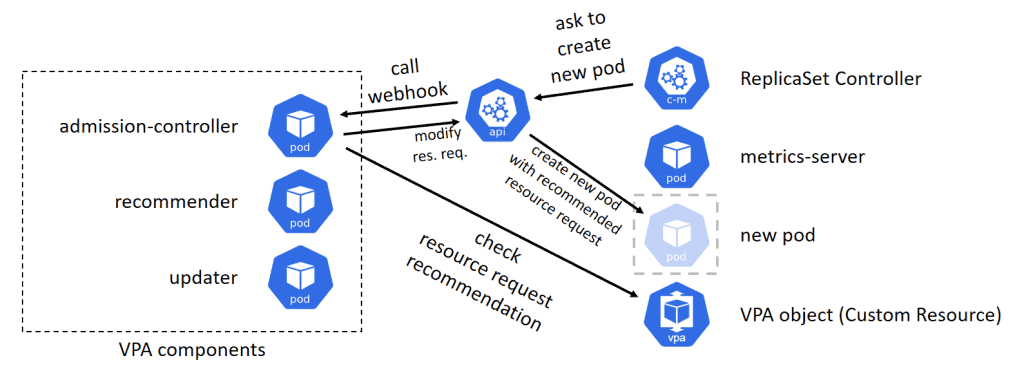
When a pod of a deployment or a replica set has deleted by the updater, the replica set controller will detect the number of pods is not enough, and will try to create a new pod. The pod creation request is sent to the api-server, and api-server calls the webhook registered by the admission-controller. The admission-controller modifies the pod creation request according to the recommended resource requests values. Finally, the new pod created with the appropriate resource requests.
Change periodic task frequency
The admission-controller works synchronously when a pod creation request is made, so we can forget about the admission-controller in this article. It never affect the responsiveness of VPA.
Since the recommender and updater work periodically, their frequency is important. These can be modified by --recommender-interval and --updater-interval options.
You can change these options by modifying recommender-deployment.yaml and updater-deployment.yaml, like this:
Patch license: Apache-2.0 (same as original autoscaler)
https://github.com/kubernetes/autoscaler
diff --git a/vertical-pod-autoscaler/deploy/recommender-deployment.yaml b/vertical-pod-autoscaler/deploy/recommender-deployment.yaml
index f45d87127..739c35da6 100644
--- a/vertical-pod-autoscaler/deploy/recommender-deployment.yaml
+++ b/vertical-pod-autoscaler/deploy/recommender-deployment.yaml
@@ -38,3 +38,9 @@ spec:
ports:
- name: prometheus
containerPort: 8942
+ command:
+ - /recommender
+ - --v=4
+ - --stderrthreshold=info
+ - --prometheus-address=http://prometheus.monitoring.svc
+ - --recommender-interval=10s
diff --git a/vertical-pod-autoscaler/deploy/updater-deployment.yaml b/vertical-pod-autoscaler/deploy/updater-deployment.yaml
index a97478a8e..b367f1a04 100644
--- a/vertical-pod-autoscaler/deploy/updater-deployment.yaml
+++ b/vertical-pod-autoscaler/deploy/updater-deployment.yaml
@@ -43,3 +43,7 @@ spec:
ports:
- name: prometheus
containerPort: 8943
+ args:
+ - --v=4
+ - --stderrthreshold=info
+ - --updater-interval=10sThe other options, --v, --stderrthreshold and --recommender-interval are default ones defined in recommender/Dockerfile and updater/Dockerfile.
Warning: --recommender-interval=10s and --updater-interval=10s are too frequent for normal usecases. Do not copy and paste this for your real-world cluster!
The recommendation algorithm
Despite the updater responsiveness could be controlled only by --updater-interval, for the recommender we need some more modification. To improve the responsiveness of the recommender, we have to understand the recommendation algorithm.
The recommender defines the lower and upper limit of the resource requests for pods, and the updater checks the current resource requests of a pod is in the recommended range. So the problem is, the recommender is designed to make these limits wider if the resource utilization of the pods are changing fast. This design is reasonable for the real-world use cases, but for our demonstration, I want them to react more quickly.
The recommender records resource utilization history of the target pods and makes recommendation range wider if its volatility is too high. You can reduce the effect of the volatility with --cpu-histogram-decay-half-life option.
Patch license: Apache-2.0 (same as original autoscaler)
https://github.com/kubernetes/autoscaler
diff --git a/vertical-pod-autoscaler/deploy/recommender-deployment.yaml b/vertical-pod-autoscaler/deploy/recommender-deployment.yaml
index 739c35da6..09113a02e 100644
--- a/vertical-pod-autoscaler/deploy/recommender-deployment.yaml
+++ b/vertical-pod-autoscaler/deploy/recommender-deployment.yaml
@@ -44,3 +44,4 @@ spec:
- --stderrthreshold=info
- --prometheus-address=http://prometheus.monitoring.svc
- --recommender-interval=10s
+ - --cpu-histogram-decay-half-life=10sWarning: --cpu-histogram-decay-half-life=10s is too fast for normal usecases. Do not copy and paste this for your real-world cluster!
Another factor that makes recommendation range wider is the length of the resource utilization history.
According to the CreatePodResourceRecommender implementation, it combining the following estimators.
percentileEstimator: returns the actual resource utilizationmarginEstimator: adds safety margin to the recommendationconfidenceMultiplier: make recommendation range wider regarding the resource utilization history length
The confidenceMultiplier make recommendation range wider with the folowing formulae.

If we have only 3 minutes long history, and the MeasuredResourceUtilization = 0.6 cpu, the confidenceMultiplier calculates as like this:

In this situation, while the pod’s resources.requests.cpu is in range [0.27 cpu, 289 cpu], nothing happens. In other words, the updater determines “Ah, the pod’s requesting resource is in the suggested range, so I have nothing to do so far”.
Since this suggestion range varies in the order of a day, as long as I use the default implementation, I never see any reaction of the VPA in our 5 to 10 minutes long presentation.
Note that the description in this section is bit inaccurate because I didn’t explain about resource utilization histogram, but the conclusion is almost correct, I think.
Modifying the recommendation algorithm
Unfortunately, the parameters determine the extent of the recommendation range are hardcoded. So I decided to modify the code.
The requirements for our presentation are…
- The recommendation limits shouldn’t be affected by the hitory length
- The recommendation should reflect the measured resource utilization
- We should be able to manipulate the actual resource usage to be out of the recommendation range in minutes
I created the new design reflecting these requirements as follows. Simpler is better for manual manipulation.
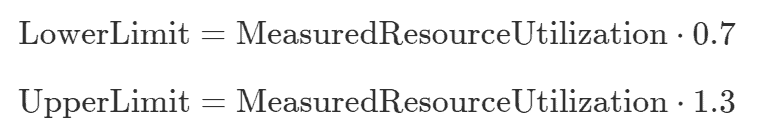
This new design can be implemented as follows.
Patch license: Apache-2.0 (same as original autoscaler)
https://github.com/kubernetes/autoscaler
diff --git a/vertical-pod-autoscaler/pkg/recommender/logic/recommender.go b/vertical-pod-autoscaler/pkg/recommender/logic/recommender.go
index bc2320cca..cdce617fd 100644
--- a/vertical-pod-autoscaler/pkg/recommender/logic/recommender.go
+++ b/vertical-pod-autoscaler/pkg/recommender/logic/recommender.go
@@ -111,9 +111,9 @@ func CreatePodResourceRecommender() PodResourceRecommender {
lowerBoundEstimator := NewPercentileEstimator(lowerBoundCPUPercentile, lowerBoundMemoryPeaksPercentile)
upperBoundEstimator := NewPercentileEstimator(upperBoundCPUPercentile, upperBoundMemoryPeaksPercentile)
- targetEstimator = WithMargin(*safetyMarginFraction, targetEstimator)
- lowerBoundEstimator = WithMargin(*safetyMarginFraction, lowerBoundEstimator)
- upperBoundEstimator = WithMargin(*safetyMarginFraction, upperBoundEstimator)
+ targetEstimator = WithMargin(0, targetEstimator)
+ lowerBoundEstimator = WithMargin(-0.3, lowerBoundEstimator)
+ upperBoundEstimator = WithMargin(0.3, upperBoundEstimator)
// Apply confidence multiplier to the upper bound estimator. This means
// that the updater will be less eager to evict pods with short history
@@ -126,7 +126,7 @@ func CreatePodResourceRecommender() PodResourceRecommender {
// 12h history : *3 (force pod eviction if the request is > 3 * upper bound)
// 24h history : *2
// 1 week history : *1.14
- upperBoundEstimator = WithConfidenceMultiplier(1.0, 1.0, upperBoundEstimator)
+ // upperBoundEstimator = WithConfidenceMultiplier(1.0, 1.0, upperBoundEstimator)
// Apply confidence multiplier to the lower bound estimator. This means
// that the updater will be less eager to evict pods with short history
@@ -140,7 +140,7 @@ func CreatePodResourceRecommender() PodResourceRecommender {
// 5m history : *0.6 (force pod eviction if the request is < 0.6 * lower bound)
// 30m history : *0.9
// 60m history : *0.95
- lowerBoundEstimator = WithConfidenceMultiplier(0.001, -2.0, lowerBoundEstimator)
+ // lowerBoundEstimator = WithConfidenceMultiplier(0.001, -2.0, lowerBoundEstimator)
return &podResourceRecommender{
targetEstimator,Conclusion
- The Vertical Pod Autoscaler is designed as not modifying resource requests too frequent
- Unfortunately, the parameters that determine how frequent the modification made are hardcoded
- In order to react changes of resource utilization in the order of a minute, you’ll have to modify the source code
Related works by others
- In-place Pod Vertical Scaling feature (Work in progress)
References
- https://github.com/kubernetes/autoscaler/tree/vertical-pod-autoscaler-0.11.0/vertical-pod-autoscaler
- https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/
- https://kubernetes.io/docs/reference/access-authn-authz/extensible-admission-controllers/
- Trademarks and registered trademarks of other companies