
Guest post also published on the Grafana Labs blog by Hrittik Roy
Kubernetes, a graduated project of the Cloud Native Computing Foundation (CNCF) ecosystem, is the most prominent and widely used container orchestration systems. It’s used to manage and deploy containers in a wide range of environments, from IoT devices based on Raspberry Pis to enterprise environments consisting of millions of services.
However, the teams that manage these clusters need to know what’s happening to the state of objects in the cluster, and this in turn introduces a requirement to gather real-time information about cluster statuses and changes. This is enabled by Kubernetes events, which give you a detailed view of the cluster and allow for effective alerting and monitoring.
In this guide, you’ll learn how Kubernetes events work, what generates them, and where they’re stored. You’ll also learn to integrate Grafana with your Kubernetes environment to effectively use the information supplied by those events to support your observability strategy.
What are Kubernetes events?
Kubernetes events provide a rich source of information. These objects can be used to monitor your application and cluster state, respond to failures, and perform diagnostics. The events are generated when the cluster’s resources — such as pods, deployments, or nodes — change state.
Whenever something happens inside your cluster, it produces an events object that provides visibility into your cluster. However, Kubernetes events don’t persist throughout your cluster life cycle, as there’s no mechanism for retention. They’re short-lived, only available for one hour after the event is generated. (Later in this post, we’ll show you how to get actionable insights from these events by using Grafana.)
The events can be generated for a number of reasons, but the following examples are some of the most common causes.
1. State change
Kubernetes events are automatically generated when certain actions are taken on objects in a cluster, e.g., when a pod is created, a corresponding event is created. Other examples are changes in pod status to pending, successful, or failed. This includes reasons such as pod eviction or cluster failure.
Remember: services, PersistentVolumes, StorageClasses, and other objects also produce events; we’re using a pod as an example for simplicity.
2. Configuration changes
Events are also generated when there’s a configuration change. Configuration changes for nodes can include scaling horizontally by adding replicas, or scaling vertically by upgrading memory, disk input/output capacity, or your processor cores.
3. Scheduling
Scheduling or failed scheduling scenarios also generate events. Failures can occur due to invalid container image repository access, insufficient resources, or if the container fails a liveness or readiness probe.
This is not an exhaustive list; there are many more reasons for this to occur.
Types of Kubernetes events
You can use Kubernetes events to monitor your system for problems by tracking the number of events and their content over time and setting up alerts for specific conditions. The alerts and frequency tracking ensure that problems are detected and dealt with in a timely manner. To understand how to track these events, you need to understand more about the five types of events.
1. Failed events
Failed events are caused when there’s a manifest-level error on your object manifest, or there’s a problem pulling the container image from the repository. Image pull errors can happen due to:
The wrong credentials for a private repository Rate limiting A typo on the image name or tags
The best way to troubleshoot this is to check that the image address and tags are correct. To do this, pull the image through docker pull <image_name> before you add it to your manifest. If it fails to pull or download your image locally, it will throw an ImagePullBackOff error. While there are many image-related errors, the most common ones involve a faulty tag or name, followed by incorrect credentials.
2. Evicted events
Kubelet is responsible for running containers on nodes in a Kubernetes cluster. It ensures that all containers are healthy and running, and it coordinates with the primary node to provide an accurate view of the cluster state. In some scenarios, though, insufficient resources will cause it to evict your pods from your node with resource constraints.
If other nodes with sufficient resources are available, the scheduler will then schedule your pods to that node. To prevent evictions, use taint to prevent new pods from being scheduled on nodes with high utilization.
3. Failed scheduling events
A failed Kubernetes scheduling event happens when there isn’t a sufficient node. This can be caused by a taint on your nodes, insufficient resources, or nodes that don’t match selectors for your pod or deployment.
The FailedScheduling message provides details about the conditions surrounding the failure, which you can use to develop a plan for how to resolve the conflict. Use the kubectl describe object/object-name command to get details about the error and make rectifications.
4. Volume events
Whenever you want to persist data for your workloads, you need persistent volumes in Kubernetes. FailedMount and FailedAttachVolume are common events caused by a networking or configuration error between your persistent volume and claims, which prevents disks from being used by your pods. Causes of configuration error include incorrect access modes, new nodes with insufficient mount points, or new nodes with too many disks attached.
Events can provide visibility into the corrections needed for your application to run correctly and resolve errors. Troubleshooting steps can involve detaching the disk manually or using selectors, labels, and tolerations to tell Kubernetes Scheduler to start the pod in a specific node.
5. Node events
Kubernetes nodes are the machines in a cluster that run your applications and store your data. You can run Kubernetes on a number of platforms, including public clouds, private clouds, bare metal servers, and even your laptop. However, unhealthy nodes can cause 5XX errors, unhealthy deployments, or other infrequent or frequent events.
Rebooting your node will help to resolve this, and the rebooted event is generated when a restart occurs. You can reboot manually, or the control plane can do it automatically.
NodeNotReady is an event that occurs when your node is still in preparation mode and isn’t yet ready to schedule pods. Another node event is HostPortConflict, which occurs when your cluster becomes unreachable or is unable to connect, possibly due to an incorrect NodePort, DaemonSet conflicts, or a node failure.
Accessing your Kubernetes events
Kubectl is a powerful Kubernetes utility that helps you manage your Kubernetes objects and resources. The simplest way to view your event objects is to use kubectl get events.
When you add an Nginx pod to your cluster, you’ll see output similar to this:
hrittik@Azure:~$ kubectl get events
LAST SEEN TYPE REASON OBJECT MESSAGE
5s Normal Scheduled pod/nginxreplica Successfully assigned default/nginxreplica to aks-nodepool1-26081864-vmss000004
5s Normal Pulling pod/nginxreplica Pulling image "nginx"
5s Normal Pulled pod/nginxreplica Successfully pulled image "nginx" in 272.563572ms
5s Normal Created pod/nginxreplica Created container nginxreplica
5s Normal Started pod/nginxreplica Started container nginxreplica
Here, details about container creation, start, and image pull are all shown.
To view your data in JSON, pass in the -o json flag to your events command. The new command will look like this:
kubectl get events -o json
You can also get events through a specific namespace by using the --namespace=${NAMESPACE} flag. If you need to get events related to specific objects, this can be achieved by describing an object using the command kubectl describe object/object_name. You’ll find all the object-specific events in the Events section of the object description.
Taking the above example of a newly created pod, you can get the same information about the pod’s events by running kubectl describe pods/nginxreplica, then scrolling through the sections to reach Events:
hrittik@Azure:~$ kubectl describe pods/nginxreplica
Name: nginxreplica
Namespace: default
Priority: 0
Node: aks-nodepool1-26081864-vmss000004/10.224.0.4
Start Time: Wed, 17 Aug 2022 22:32:13 +0000
Labels: run=nginxreplica
Annotations: <none>
Status: Running
IP: 10.244.0.10
IPs:
IP: 10.244.0.10
Containers:
nginxreplica:
Container ID: containerd://975825f21309b2d56af402018f3a1678812ec41ad287fe30bfd61f2430e236be
Image: nginx
Image ID: docker.io/library/nginx@sha256:790711e34858c9b0741edffef6ed3d8199d8faa33f2870dea5db70f16384df79
Port: <none>
Host Port: <none>
State: Running
Started: Wed, 17 Aug 2022 22:32:14 +0000
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-fbhx4 (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-fbhx4:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 4m28s default-scheduler Successfully assigned default/nginxreplica to aks-nodepool1-26081864-vmss000004
Normal Pulling 4m28s kubelet Pulling image "nginx"
Normal Pulled 4m28s kubelet Successfully pulled image "nginx" in 272.563572ms
Normal Created 4m28s kubelet Created container nginxreplica
Normal Started 4m28s kubelet Started container nginxreplica
While events contain a great deal of insight and information, they’re inherently limited, since you can’t query or retain them longer than an hour. To develop actionable insights, you have to fetch and retain the events so you can draw conclusions from an aggregate view over a period of time.
To do this effectively, you need a more robust solution, like Grafana.
Grafana Agent and monitoring
The Grafana Agent is a lightweight data collector that can be installed in your Kubernetes cluster to collect telemetry data, such as logs, events, and traces. That data can then be forwarded to the Grafana LGTM Stack (Loki for logs, Grafana for visualization, Tempo for Traces, and Mimir for metrics), Grafana Cloud, or Grafana Enterprise. No matter what form of Grafana you deploy, you can create and share dynamic dashboards that monitor and alert on your cloud native applications, tools, and Kubernetes clusters.
With the help of the Grafana Agent, you can track all the events in your cluster — not just the ones from an hour ago.
Metrics eventhandler
The eventhandler_config is a Grafana Agent integration for Kubernetes that allows your agent to fetch real-time events from the Kubernetes API and forward them to Grafana Loki, which acts as your log aggregator. You can deploy the Grafana Agent as a Kubernetes DaemonSet or a Deployment.
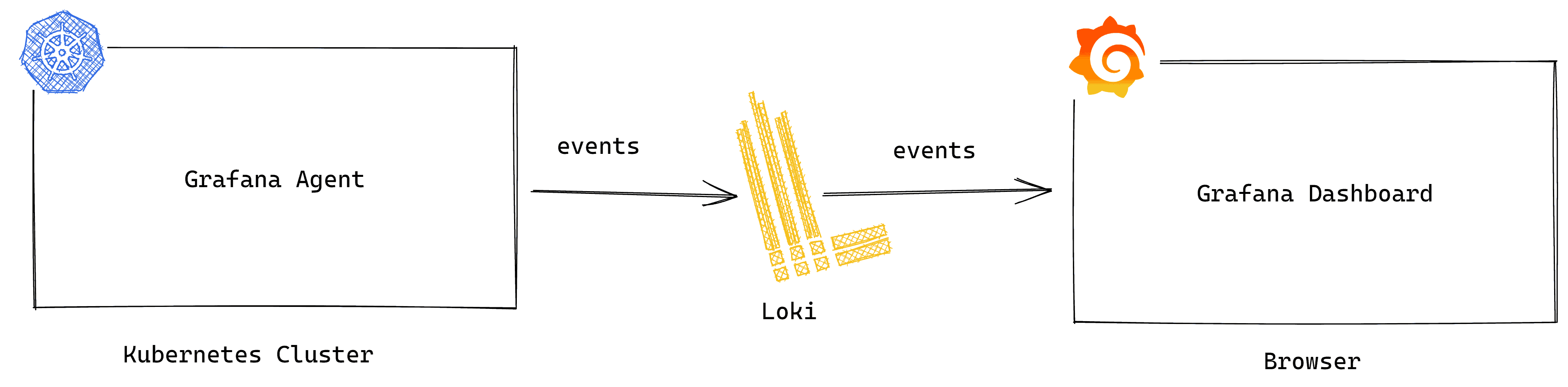
Deploying the Grafana Agent can sometimes cause log replication issues due to the lack of a cache file (cache_path) that stores all logs since the integration’s activation with DaemonSet. Because of this, duplicate entries can be shipped when a restart occurs; however, you can de-duplicate your logs at the dashboard level.
Grafana, which has long been a part of the CNCF ecosystem as a tool for monitoring and observability, comes in handy when you’re looking for simple solutions for your Kubernetes cluster. When you use the event handler extension, you gain access to a very wide range of features. Some of the most important include:
- Scalable metric collection with host_filtering and sharding.
- The ability to use LogQL on top of your queries.
- Specific filters, such as
clusterwith the name of your cluster, to find events from specific clusters. - Alerting on Slack, emails, or other channels when there’s a change of state, evictions, or errors.
- Aggregating events over a period of time to provide a more comprehensive view in your logs and dashboards.
Using the Grafana Agent is very simple. You need to have access to a Kubernetes cluster and a Grafana instance, which can either be SaaS-based or self-hosted. Edit the agent manifest to reflect the correct values for your Loki credentials, then apply it to your cluster and connect it to your Grafana instance.
If you’re interested in monitoring your Kubernetes clusters but don’t want to do it all on your own, we offer Kubernetes Monitoring in Grafana Cloud — the full solution for all levels of Kubernetes usage that gives you out-of-the-box access to your Kubernetes infrastructure’s metrics, logs, and Kubernetes events as well as prebuilt dashboards and alerts. Kubernetes Monitoring is available to all Grafana Cloud users, including those in our generous free tier. If you don’t already have a Grafana Cloud account, you can sign up for a free account today!