
Guest post originally published on NGINX’s blog by Robert Haynes of F5
Just as regular check‑ups with a doctor are an important part of staying healthy, regular checks on the health of your apps are critical for reliable performance. When reverse proxying and load balancing traffic, NGINX uses passive health checks to shield your application users from outages by automatically diverting traffic away from servers that don’t respond to requests. NGINX Plus adds active health checks, sending special probes that can detect unhealthy servers even before they fail to process a request. Which type of health check makes sense for your applications? In this post, we give you the info you need to make that decision.
What Is a Health Check?
In the most basic sense, a health check is a method for determining whether a server is able to handle traffic. NGINX uses health checks to monitor the servers for which it is reverse proxying or load balancing traffic – what it calls upstream servers.
Passive Health Checks
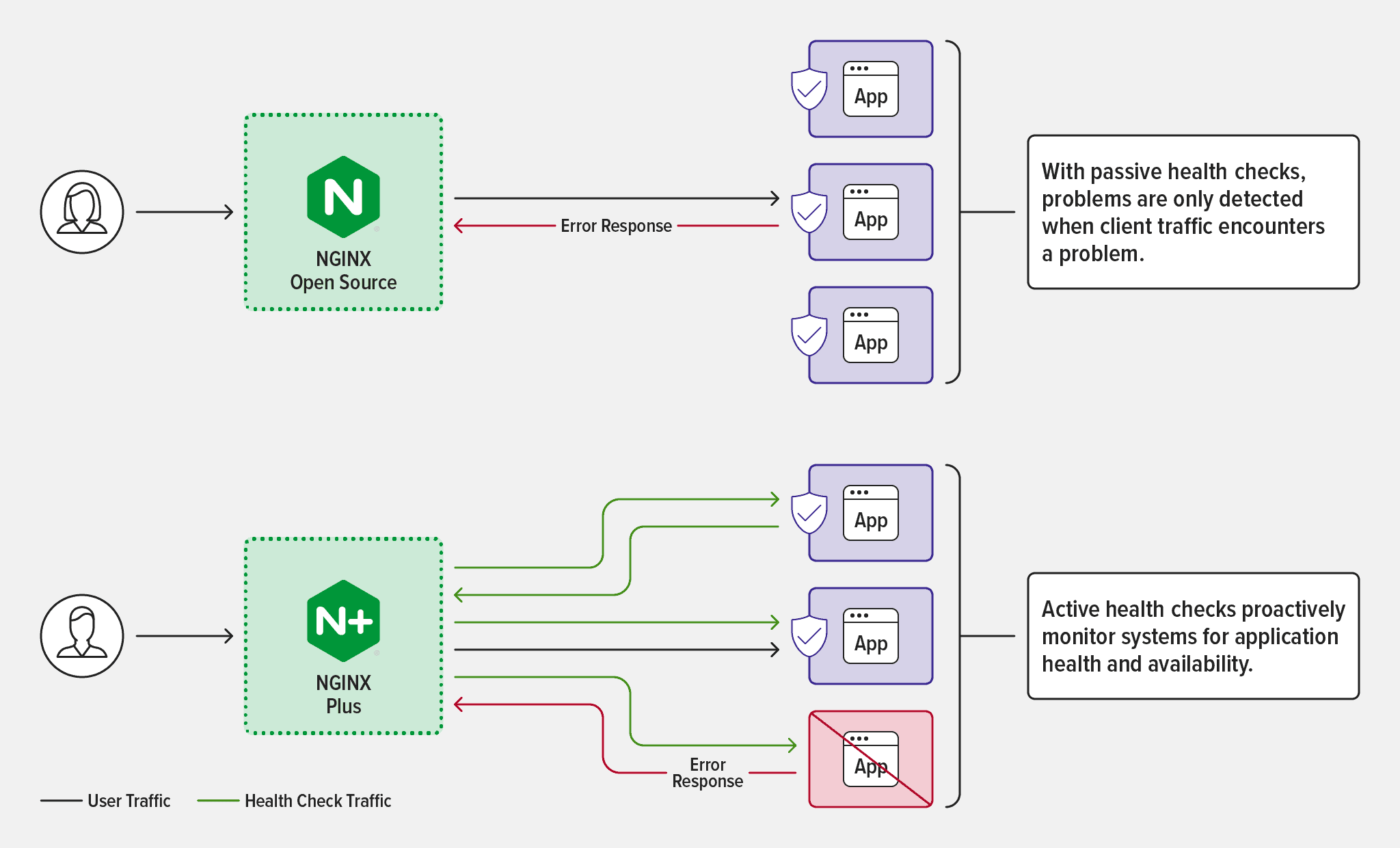
Passive health checks – available in both NGINX Open Source and NGINX Plus – rely on observing how the server behaves while handling connections and traffic. They help prevent users from experiencing outages due to server timeouts, because when NGINX discovers a server is unhealthy it immediately forwards the request to a different server, stops sending requests to the unhealthy server, and distributes future requests among the remaining healthy servers in the upstream group.
Note that passive health checks are effective only when the upstream group is defined to have multiple members. When only one upstream server is defined, it is never marked unavailable and users see an outage when it’s unhealthy.
How Passive Health Checks Work
Here’s a detailed look at how passive health checks work, but skip ahead to Active Health Checks if it’s not of interest.
By default, NGINX considers a TCP/UDP (stream) server unhealthy if there is a single error or timeout while establishing a connection with it.
NGINX considers an HTTP server unhealthy if there is a single error or timeout while establishing a connection with it, passing a request to it, or reading the response header (receiving no response at all counts as this type of error). You can use the proxy_next_upstream directive to customize these conditions for HTTP proxying, and there is a parallel directive for the FastCGI, gRPC, memcached, SCGI, TCP/UDP, and uwsgi protocols.
For both HTTP and TCP/UDP, NGINX waits a default ten seconds before again trying to connect and send a request to an unhealthy server. You can use the fail_timeout parameter to the server[HTTP][Stream] directive to change this amount of time.
You can use the max_fails parameter to the server directive to increase the number of errors or timeouts that must occur for NGINX to consider the server unhealthy; in this case, the fail_timeout parameter sets the period during which that number of errors or timeouts must occur, as well as how long NGINX waits to try the server again after marking it unhealthy.
Active Health Checks
Active health checks – which are exclusive to NGINX Plus – are special requests that are regularly sent to application endpoints to make sure they are responding correctly. They are separate from and in addition to passive health checks. For example, NGINX Plus might send a periodic HTTP request to the application’s web server to ensure it responds with a valid response code and the correct content. Active health checks enable continuous monitoring of the health of specific application components and processes. It constitutes a direct measurement of application availability, although that depends on how representative the specified health check is of overall application health.
You can customize many aspects of an active health check; see Use Cases for Active Health Checks.
Use Cases for Passive Health Checks
Passive health checks are table stakes. It’s a best practice for every Application Development, DevOps, DevSecOps, and Platform Ops team to run passive health checks as a part of its monitoring program for production infrastructure. NGINX runs passive health checks on load‑balanced traffic by default, including HTTP, TCP, and UDP configurations.
The advantages of passive health checks include:
- Available in NGINX Open Source
- Enabled by default for the servers included in an
upstream{}configuration block - No additional load on the upstream servers
- Configurable in terms of minimum number of failures within a time period, as described in How Passive Health Checks Work
- Configurable slow start (exclusive to NGINX Plus) – when a server returns to health, NGINX Plus gradually ramps up the amount of traffic forwarded to it, to give it time to “warm up”
The advantages of NGINX Open Source are cost (none, obviously), configurability, and a vast library of third‑party modules. Because the source code is available, developers can modify and extend the functionality to suit their specific needs.
For many applications (and their developers) passive health checks are sufficient. For example, active health checks might be overkill for microservices that are not facing customers and perform smaller tasks. Similarly, they may not be necessary for applications where caching can reduce chances of latency issues or content distribution networks (CDNs) can take over some of the application tasks. To summarize, passive health checks alone are best for:
- Monitoring HTTP traffic
- Monitoring infrastructure separately from applications
- Monitoring applications where latency is tolerable
- Monitoring internal applications where high performance isn’t important
Use Cases for Active Health Checks
For mission‑critical applications, active health checks are often crucial because customers and key processes are directly impacted by problems. With these applications, it is critical to test the application essentially as the customer or consumer of the application does, and that requires active health checks. Active health checks are similar to application performance monitoring tools such as New Relic and AppDynamics, which use out-of-band checks to measure application latency and responses. For active health checks, NGINX Plus includes a number of features and capabilities not included in NGINX Open Source:
- Out-of-band health checks for application availability
- Test configured end points and look for specific responses
- Test different ports than those handling real application traffic
- Keepalive HTTP connections for health checks, eliminating the need to set up a new connection for each check
- Greater control over failing and passing conditions
- Optionally test any newly added servers before they receive real application traffic
With active health checks, developers can set up NGINX Plus to automatically detect when a backend server is down or experiencing issues, then route traffic to healthy servers until the issue is fixed. The greater configurability of active health checks allows for more sophisticated health checks to be performed, possibly detecting application problems before they impact real application users. This can minimize downtime and prevent interruptions to user access to the application.
How to Configure Health Checks
Passive health checks are enabled by default, but you can customize their frequency and the number of failures that occur before a service is marked unhealthy, as described in How Passive Health Checks Work. For complete configuration instructions for both passive and active health checks, see our documentation:
Conclusion: Pick the Health Checks that Match Your Application Requirements
Health checks are an important part of keeping any production application running smoothly and responsively. They are the best way to detect problems and identify growing sources of latency before they affect end users. For many applications, passive health checks are sufficient.
For more critical applications, where direct insights into application behaviors at the user level are necessary, active checks are better. NGINX Open Source is free to use and provides configurable passive health checks. NGINX Plus provides advanced active health check capabilities as well as commercial support.
Want to try active health checks with NGINX Plus? Start your 30-day free trial today or contact us to discuss your use cases.