Ambassador post by Miley Fu, CNCF Ambassador, DevRel at CNCF WasmEdge project
Introduction:
The recent surge in popularity of large language models and their applications, driven by the success of ChatGPT, has sparked immense interest in the technical innerworkings behind these models. To delve into the infrastructure behind large language models and related applications, WasmEdge, under the support of Cloud Native Computing Foundation (CNCF) has organized a meetup in Beijing on July 8th. This event brought together experts and developers from various domains around AI cloud-native open-source communities, to discuss and analyze together the different technologies in the ecosystem of large language models.

We explored the following 5 topics:
Michael Yuan – Building Lightweight AI Applications with Rust and Wasm
Michael Yuan, the founder of CNCF’s WasmEdge runtime, explores the utilization and construction of WebAssembly (Wasm) container infrastructure for large language model (LLM) plugins.
He outlined several key problems with current LLM functions and plugins:
- LLM lock-in forces users to stay within a single vendor’s ecosystem. This limits flexibility.
- Model workflow lock-in means you can’t easily swap out components like the tokenizer or inference engine. Everything has to stay within one monolithic framework.
- UI lockin restricts the UI/UX to what the vendor provides with little space for customization.
- Lack of support for machine inputs – LLMs today are built for conversational models with human inputs. They don’t handle structured, machine-generated data very well.
- LLMs cannot initiate conversations or proactively provide information. The user has to drive all interactions.
Existing open source frameworks also pose challenges:
- Developers must build and manage infrastructure even for basic applications. There is no serverless option.
- Everything relies on Python which is slow for inference compared to compiled languages like Rust.
- Devs must write custom auth and connectors to external services like databases. This overhead slows down development.
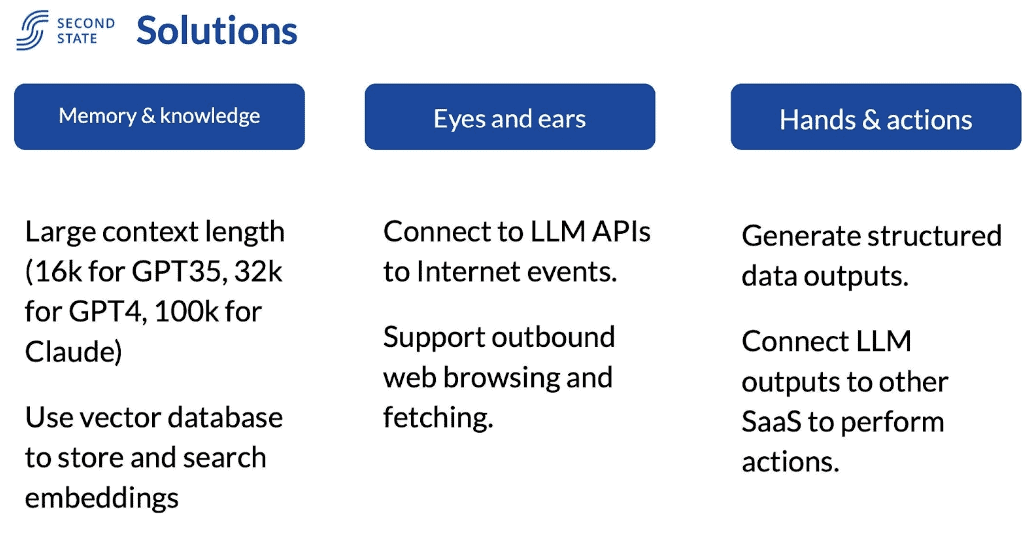
To overcome these limitations, WebAssembly and serverless functions are a great approach for building lightweight LLM applications. Wasm provides a portable runtime with fast startup times, supporting multiple languages including Rust which is ideal for computing intensive inference.
A serverless platform, flows.network powered by WasmEdge, allows devs to run serverless rust functions in WasmEdge in R&D management, DevRel, marketing automation and training/learning, to give memory & ears, hands and actions to LLMs, enabling the implementation of LLM applications in several minutes using a serverless approach. This can cut down development time from months to minutes. It could enable a new generation of customizable, specialized LLM applications.
Through this talk, the audience learns how to use flows.network to build AI applications in a serverless way in less than 3 minutes.

Wang Fangchi – FATE-LLM: Federated Learning Meets Large Language Models
Wang Fangchi, a senior engineer from VMware’s CTO Office and a maintainer of the FATE project, introduced FATE-LLM, a forward-thinking solution that combines federated learning with large language model technologies. FATE-LLM allows multiple participants to collaborate on fine-tuning large models using their private data, ensuring data privacy without sharing it beyond local domains. The talk covers the latest efforts in applying federated learning to large language models like ChatGLM and LLaMA, discussing technical challenges, design concepts, and future plans.
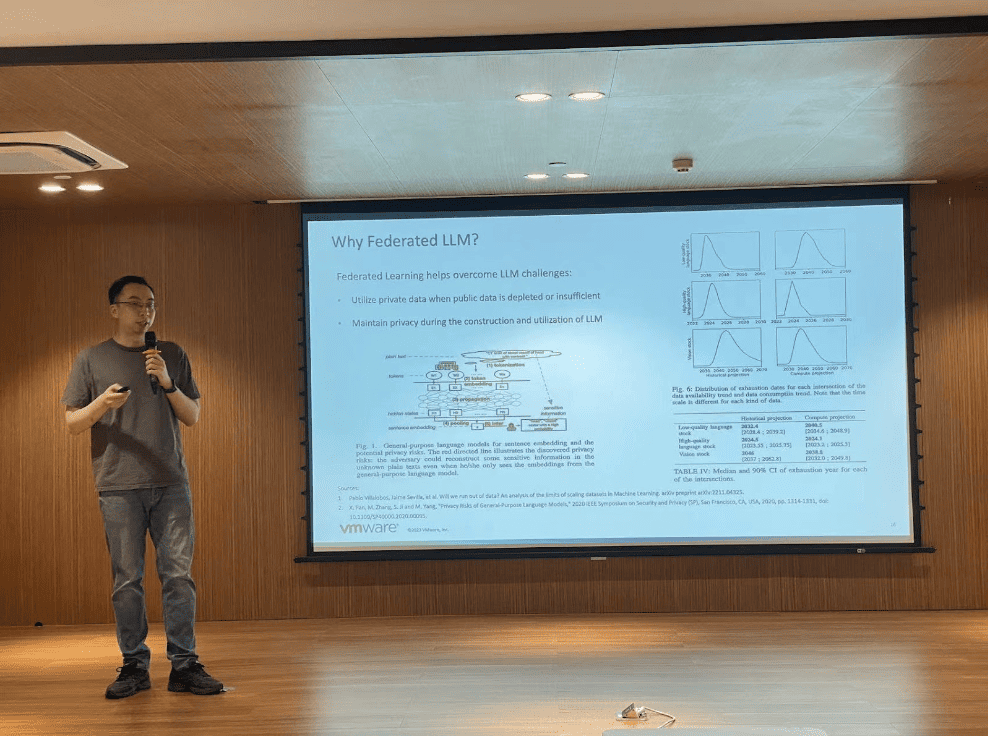
Federated learning is a promising approach for addressing data privacy concerns with LLMs. Federated Learning helps overcome LLM challenges:
- Utilize private data when public data is depleted or insufficient
- Maintain privacy during the construction and utilization of LLM
FATE-LLM (FATE Federated Large Language Model) allows participants to fine-tune a shared model using their own private data without transferring the raw data. This could enable more organizations to benefit from LLMs.
- Multiple clients can perform horizontal FL through FATE’s built-in support of pre-trained model and use private data for large-scale model fine-tuning;
- Support 30+ participants for a collaborative training
Li Chen – Vector Database: The Long-Term Memory of Large Models
Li Chen, VP of operations and ecosystem development at Milvus, highlights the significance of vector databases for organizations building building custom large language models. Milvus is an open source vector database designed for cloud-native environments. It adopts a microservices architecture based on Kubernetes (K8s), enabling distributed cloud-native operations. With a storage-compute separation approach, Milvus offers elastic scalability, allowing for seamless expansion and contraction based on workload demands. Its high availability ensures rapid recovery from failures, typically within minutes.
One of Milvus’ remarkable capabilities lies in its ability to handle billions of vectors, showcasing its scalability and suitability for large-scale applications. Leveraging message queues, Milvus enables real-time data insertion and deletion, ensuring efficient data management.
Milvus boasts integrations with various AI ecosystems, including OpenAl, Langchain, Hugging Face, and PyTorch, providing seamless compatibility with popular frameworks and libraries. Additionally, it offers a comprehensive set of ecosystem tools, such as GUI, CLI, monitoring, and backup functionalities, empowering users with a robust toolkit for managing and optimizing their Milvus deployments.
In summary, Milvus delivers a distributed, cloud-native vector database solution that excels in scalability, fault tolerance, and integration with diverse AI ecosystems. Its microservices design, combined with its extensive set of ecosystem tools, establishes Milvus as a powerful tool for managing large-scale AI applications.
Zhang Zhi – Model Quantization Techniques in AI Development
Zhang Zhi, an engineer from the PPQ team at SenseTime, dives into the widely applied technique of neural network quantization. The talk focuses on various quantization techniques used in large language models, such as weight-only quantization and groupwise kv cache quantization. Zhang discusses the application scenarios and performance benefits of these techniques and provides insights into model deployment on servers, performance optimization, and reducing storage and computational costs.

Model quantization and compression are crucial for deploying large language models, especially on resource-constrained devices. Tools like PPQ can quantize neural networks to reduce their size and computational cost, enabling them to run on a wider range of hardware.
This speech was full of practical technical details in the development of neural network model quantification and received warm acclaims from the audience.
Tea break with Pizzas and Fruits:
Marked with the WasmEdge and CNCF Phippy and Friends Stickers

Conclusion:
This meetup turns out to be an exciting event for attendees passionate about cloud-native and AI technologies bracing the heatwave. With a focus on large language models, the speakers delved into various aspects of large language models via these 5 open source projects, including lightweight AI application development, federated learning with large models, vector databases, model quantization, and LLM evaluation. Attendees gain valuable insights into the intricate details of these technologies, enabling them to leverage the synergy among open source Cloud Native and AI projects and applications.
Overall, this meetup highlights how open source technologies are empowering organizations to build and apply large language models. By sharing knowledge and collaborating, the AI and cloud native communities can together tackle the challenges involved in advancing and productizing this new generation of AI systems.
