
Member post by DatenLord
- What is Xline
Xline is an open source distributed KV storage engine, its core purpose is to achieve high-performance strong consistency across data centers, providing cross-data center metadata management. So how does Xline achieve this high-performance strong consistency across data centers? This article will lead you to find out.
- The Overall Architecture of Xline
Let’s take a look at the overall architecture of Xline, as shown below:
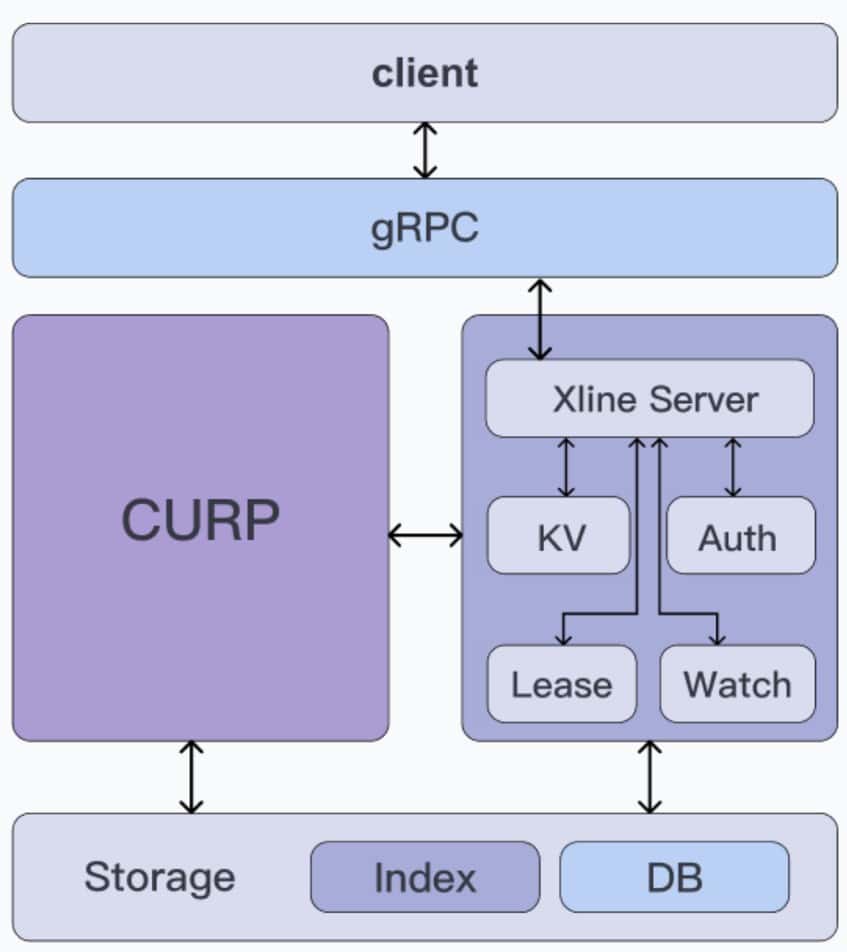
From top to bottom, Xline can be roughly divided into three layers, namely
- Access layer: Implemented using the gRPC framework, responsible for receiving requests from clients.
- Middle Layer: it can be divided into CURP Consensus Module (left) and Business Server Module (right), where:
- CURP Consensus Module: Implements the CURP consensus algorithm, the code corresponds to the curp crate in Xline, while the corresponding RPC service is defined in curp/proto.
- Business Server Module: It is responsible for realizing the upper layer business logic of Xline, such as KvServer for KV-related requests and AuthServer for authentication requests, etc. The code corresponds to the xline crate, while the corresponding RPC service is defined in the xlineapi crate.
- Storage layer: responsible for the persistence of data and metadata within Xline, providing abstract interfaces to the upper layer, the code corresponds to the engine crate.
- Introduction to the CURP protocol
What is CURP?
The consensus protocol used in Xline is not Paxos or Raft, but a new consensus protocol called CURP, which is called “Consistent Unordered Replication Protocol (CURP)”. It was initiated in NSDI 2019’s paper “Exploiting Commutativity For Practical Fast Replication,” which was authored by Seo Jin Park, a PhD student from Stanford, and Prof. John Ousterhout, who is also the authors of Raft algorithm.
Why the CURP Protocol?
Why did Xline use a new protocol like CURP instead of Raft or Multi-Paxos as the underlying consensus protocol? To illustrate, let’s look at the problems with Raft and Multi-Paxos.
The following figure shows a flow of Raft’s consensus process:
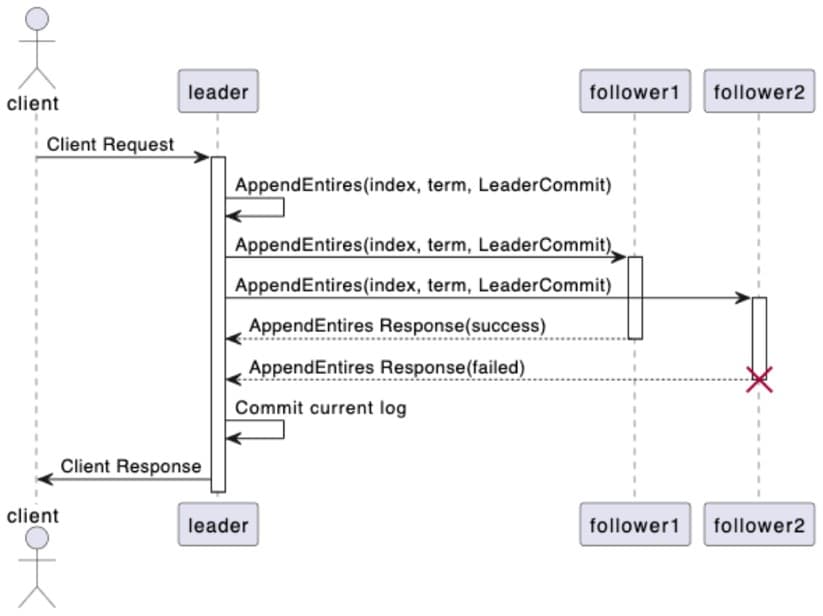
In this timing diagram, we can see how the Raft protocol reaches consensus:
- The client makes a proposal request to the leader.
- The leader receives the proposal request from the client, appends it to its state machine log, and broadcasts the AppendEntries request to other followers in the cluster.
- After receiving the AppendEntries request from the leader, the follower performs a log consistency check to determine whether it can be added to its own state machine log. It responds with a success message if the check is successful or a failure message if the check fails.
- The leader counts the number of successful responses received, and if it exceeds half of the number of cluster nodes, the consensus is considered reached and the proposal is successful, otherwise the proposal is considered to have failed and the result is returned to the client.
The following figure shows the flow of Multi-Paxos protocol to reach a consensus:
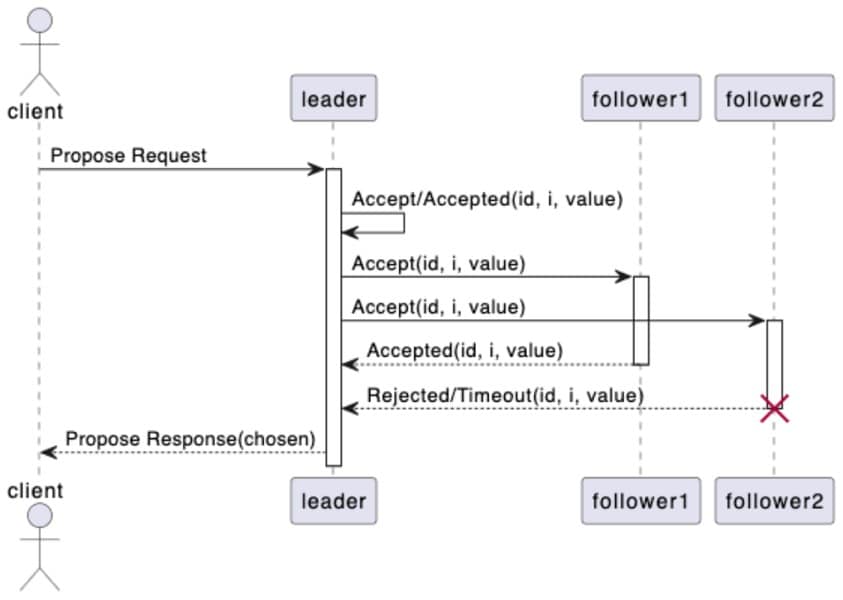
In this timing diagram, we can understand the flow of Multi-Paxos protocol to reach consensus:
- The client makes a proposal request to the leader.
- The leader finds the index of the first unapproved log entry in its state machine log, and then executes the Basic Paxos algorithm to propose the log at index with the proposal value requested by the client.
- The follower receives the proposal value from the leader and decides whether to accept the proposal value and return a successful response, or to return a failing response.
- The leader counts the number of successful responses received, and if it exceeds half of the number of nodes in the cluster, it considers that the consensus has been reached and the proposal is successful, otherwise, it considers that the proposal fails and returns the result to the client.
Be it Multi-Paxos or Raft, reaching consensus inevitably requires 2 RTTs. Both of them are based on a core assumption: the criteria of being durably stored and ordered must be met after command approval or log commit. As a result, the state machine can directly perform the approved commands or apply committed logs. Due to the inherent asynchrony of the network, ensuring orderliness is challenging. Therefore, a leader is required to enforce the execution order of different commands and achieve persistence by obtaining replication from the majority through broadcasting. This process cannot be completed within a single RTT.
That’s why Xline didn’t choose Raft or Multi-Paxos as the underlying consensus algorithm. Xline was primarily designed to manage metadata across data centers. As we all know, for a single data center, the latency of its intranet is often very low, only a few milliseconds or even less than 1ms, while for a cross-datacenter wide area network, the network latency can reach tens of milliseconds or even hundreds of milliseconds. Traditional consensus algorithms, such as Raft or Multi-Paxos, require 2 RTTs to reach a consensus, regardless of the state of the consensus, which often leads to serious performance bottlenecks in such high latency network environments. This makes us wonder whether two or more RTTs are necessary to reach consensus in any case.
The CURP algorithm is an unordered replication algorithm that breaks down the consensus scenarios into the following two categories:
- Fast path: In non-conflicting scenarios , relaxing the ordering requirements for consensus does not affect the final consensus under the premise of persistent storage. Since the fast path only requires storage persistency, only 1 RTT is needed to reach consensus. We call fast path the front-end of the protocol.
- Slow path: In conflicting scenarios, both the requirement for ordered concurrent request and persistent storage need to be satisfied, thus requring 2 RTTs to achieve consensus. We refer to the slow path as the back-end of the protocol.
Then reader may wonder, what exactly is the conflict here? Let’s use a simple KV operation as an example. In the nodes of a distributed system, the operations we do on the state machine are just read and write, and in the case of concurrent operations on the state machine, there are four scenarios: read-after-read, read-after-write, write-after-read, and write-after-write. Obviously, for read-after-read, which is a read-only operation with no side-effects, there is no conflict under any circumstances, and the final result is always the same, whether it is read first or next. When operating on different keys, for example, PUT A=1, PUT B=2, then for the final state of the state machine, no matter whether to execute PUT A=1 first, PUT B=2 next, or vice versa, the final result of reading from the state machine is A=1, B=2. The same applies to the scenario of read-write mixing. Therefore, when there is no intersection between the keys of multiple operations performed concurrently on a state machine, we say that these operations are non-conflicting. Conversely, if the concurrent operations include at least one write operation, and the keys of those operations are intersected, the operations are in conflict.
fast path vs. slow path
How does CURP implement fast path and slow path? Below is a sketch of the cluster topology in the CURP algorithm.
Let’s take a look at what’s going on in this diagram:
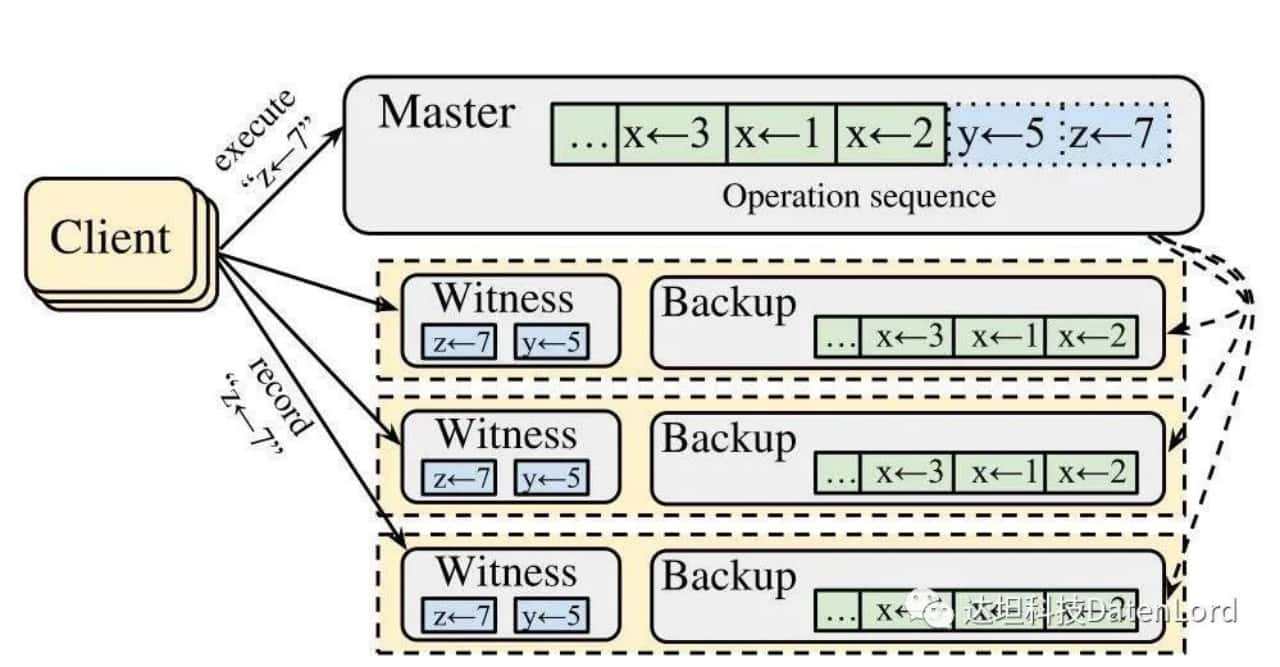
- Client: the client that makes the request to the cluster.
- Master: Corresponds to the leader node in the cluster, which holds the state machine logs, where the green part represents the logs that have been persisted to disk, and the blue part represents the logs that are stored in memory.
- Follower nodes: Corresponds to the yellow dotted box in the figure above, each follower contains the following two components.
a. Witness: it can be approximated as a memory-based HashMap, on one hand, it is responsible for logging the current requests in the cluster in the fast path process, on the other hand, CURP will also use Witness to determine whether there is a conflict in the current request. All the records saved in Witness are unordered.
b. Backup: Keeps state machine logs that are persisted to disk.
Next, let’s take the example PUT z=7 in the figure to see the execution flow of fast path:
- Client broadcasts a request for PUT z=7 to all nodes in the cluster.
- When a node in the cluster receives the request, it executes different logic depending on its role.
a. The leader receives the request and immediately writes the data z = 7 locally (that is, the blue part in the state machine log) and returns OK immediately.
b. When the follower receives the request, it uses witness to determine whether the request is in conflict . Since z = 7 does not conflict with y = 5, which is the only one in the witness, the follower saves z = 7 to the witness and returns OK to the client.
- Client collects and counts the number of successful responses received. For a cluster with 2f + 1 nodes, when the number of received successful responses reaches f+f/2+1, the operation is confirmed to be persisted to the cluster, which takes 1 RTT for the whole process.
Next, based on the previous fast path example, let’s take PUT z = 9 as an example to see the execution flow of slow path. Since z = 9 conflicts with z = 7, the fast path initiated by the client will fail and the slow path will be executed:
- Client broadcasts a PUT z=9 request to all nodes in the cluster.
- The nodes in the cluster receive the request and perform different logic according to their roles.
- The leader receives the request and writes z = 9 to the state machine log. Since z = 9 conflicts with z = 7, it returns a KeyConflict response to the client and asynchronously initiates an AppendEntries request to synchronize the state machine log to the other nodes in the cluster.
- The follower receives the request and refuses to save the proposal since z = 9 conflicts with z = 7 in the witness.
- Client collects and counts the number of successful responses received. Since the number of rejected responses received exceeds f/2, client needs to wait for the slow path to complete.
- When the AppendEntries in step 2 are executed successfully, the follower appends all three state machine logs (y = 5, z = 7, z = 9) of the leader to the Backup, removes the relevant logs from the witness, and returns the successful responses to the leader.
- The leader counts the number of successful responses received. If it exceeds half of the number of cluster nodes, the consensus is considered reached and the proposal succeeds. Otherwise, the proposal fails and the result is returned to the client.
- Summary
Xline is a distributed KV storage that provides strong consistency across data centers. One of its core problems is how to provide high-performance strong consistency in a high latency WAN environment across data centers. Traditional distributed consensus algorithms, such as Raft and Multi-Paxos, guarantee state machine consistency by making all operations satisfy storage persistency and the ordering prerequisite. The CURP protocol, makes a finer-grained division of consensus scenarios, splitting the protocol into front-end (fast path) and back-end (slow path), where the front-end only guarantees that the proposal will be persisted to the cluster, while the back-end not only guarantees persistence, but also ensures that all nodes that have saved the proposal will execute the commands in the same order, guaranteeing the consistency of the state machine.
This is the end of the introduction to the CURP protocol. For more details, please refer to our other articles and shares, as follows:
Rethinking the Curp Consensus Protocol
DatenLord | Xline Geo-distributed KV Storage
Xline is a geo-distributed KV storage for metadata management. Xline project is written in Rust, and you are welcomed to participate in our open source project!
GitHub link:
https://github.com/xline-kv/Xline
Xline official website: www.xline.cloud
Xline Discord: