


Project post originally published on Istio’s blog by Ben Leggett, Yuval Kohavi, and Lin Sun
An innovative traffic redirection mechanism between workload pods and ztunnel.
The Istio project announced ambient mesh – its new sidecar-less dataplane mode in 2022, and released an alpha implementation in early 2023.
Our alpha was focused on proving out the value of the ambient data plane mode under limited configurations and environments. However, the conditions were quite limited. Ambient mode relies on transparently redirecting traffic between workload pods and ztunnel, and the initial mechanism we used to do that conflicted with several categories of 3rd-party Container Networking Interface (CNI) implementations. Through GitHub issues and Slack discussions, we heard our users wanted to be able to use ambient mode in minikube and Docker Desktop, with CNI implementations like Cilium and Calico, and on services that ship in-house CNI implementations like OpenShift and Amazon EKS. Getting broad support for Kubernetes anywhere has become the No. 1 requirement for ambient mesh moving to beta — people have come to expect Istio to work on any Kubernetes platform and with any CNI implementation. After all, ambient wouldn’t be ambient without being all around you!
At Solo, we’ve been integrating ambient mode into our Gloo Mesh product, and came up with an innovative solution to this problem. We decided to upstream our changes in late 2023 to help ambient reach beta faster, so more users can operate ambient in Istio 1.21 or newer, and enjoy the benefits of ambient sidecar-less mesh in their platforms regardless of their existing or preferred CNI implementation.
How did we get here?
Service meshes and CNIs: it’s complicated
Istio is a service mesh, and all service meshes by strict definition are not CNI implementations – service meshes require a spec-compliant, primary CNI implementation to be present in every Kubernetes cluster, and rest on top of that.
This primary CNI implementation may be provided by your cloud provider (AKS, GKE, and EKS all ship their own), or by third-party CNI implementations like Calico and Cilium. Some service meshes may also ship bundled with their own primary CNI implementation, which they explicitly require to function.
Basically, before you can do things like secure pod traffic with mTLS and apply high-level authentication and authorization policy at the service mesh layer, you must have a functional Kubernetes cluster with a functional CNI implementation, to make sure the basic networking pathways are set up so that packets can get from one pod to another (and from one node to another) in your cluster.
Though some service meshes may also ship and require their own in-house primary CNI implementation, and it is sometimes possible to run two primary CNI implementations in parallel within the same cluster (for instance, one shipped by the cloud provider, and a 3rd-party implementation), in practice this introduces a whole host of compatibility issues, strange behaviors, reduced feature sets, and some incompatibilities due to the wildly varying mechanisms each CNI implementation might employ internally.
To avoid this, the Istio project has chosen not to ship or require our own primary CNI implementation, or even require a “preferred” CNI implementation – instead choosing to support CNI chaining with the widest possible ecosystem of CNI implementations, and ensuring maximum compatibility with managed offerings, cross-vendor support, and composability with the broader CNCF ecosystem.
Traffic redirection in ambient alpha
The istio-cni component is an optional component in the sidecar data plane mode, commonly used to remove the requirement for the NET_ADMIN and NET_RAW capabilities for users deploying pods into the mesh. istio-cni is a required component in the ambient data plane mode. The istio-cni component is not a primary CNI implementation, it is a node agent that extends whatever primary CNI implementation is already present in the cluster.
Whenever pods are added to an ambient mesh, the istio-cni component configures traffic redirection for all incoming and outgoing traffic between the pods and the ztunnel running on the pod’s node, via the node-level network namespace. The key difference between the sidecar mechanism and the ambient alpha mechanism is that in the latter, pod traffic was redirected out of the pod network namespace, and into the co-located ztunnel pod network namespace – necessarily passing through the host network namespace on the way, which is where the bulk of the traffic redirection rules to achieve this were implemented.
As we tested more broadly in multiple real-world Kubernetes environments, which have their own default CNI, it became clear that capturing and redirecting pod traffic in the host network namespace, as we were during alpha development, was not going to meet our requirements. Achieving our goals in a generic manner across these diverse environments was simply not feasible with this approach.
The fundamental problem with redirecting traffic in the host network namespace is that this is precisely the same spot where the cluster’s primary CNI implementation must configure traffic routing/networking rules. This created inevitable conflicts, most critically:
- The primary CNI implementation’s basic host-level networking configuration could interfere with the host-level ambient networking configuration from Istio’s CNI extension, causing traffic disruption and other conflicts.
- If users deployed a network policy to be enforced by the primary CNI implementation, the network policy might not be enforced when the Istio CNI extension is deployed (depending on how the primary CNI implementation enforces NetworkPolicy)
While we could design around this on a case-by-case basis for some primary CNI implementations, we could not sustainably approach universal CNI support. We considered eBPF, but realized any eBPF implementation would have the same basic problem, as there is no standardized way to safely chain/extend arbitrary eBPF programs at this time, and we would still potentially have a hard time supporting non-eBPF CNIs with this approach.
Addressing the challenges
A new solution was necessary – doing redirection of any sort in the node’s network namespace would create unavoidable conflicts, unless we compromised our compatibility requirements.
In sidecar mode, it is trivial to configure traffic redirection between the sidecar and application pod, as both operate within the pod’s network namespace. This led to a light-bulb moment: why not mimic sidecars, and configure the redirection in the application pod’s network namespace?
While this sounds like a “simple” thought, how would this even be possible? A critical requirement of ambient is that ztunnel must run outside application pods, in the Istio system namespace. After some research, we discovered a Linux process running in one network namespace could create and own listening sockets within another network namespace. This is a basic capability of the Linux socket API. However, to make this work operationally and cover all pod lifecycle scenarios, we had to make architectural changes to the ztunnel as well as to the istio-cni node agent.
After prototyping and sufficiently validating that this novel approach does work for all the Kubernetes platforms we have access to, we built confidence in the work and decided to contribute to upstream this new traffic redirection model, an in-Pod traffic redirection mechanism between workload pods and the ztunnel node proxy component that has been built from the ground up to be highly compatible with all major cloud providers and CNIs.
The key innovation is to deliver the pod’s network namespace to the co-located ztunnel so that ztunnel can start its redirection sockets inside the pod’s network namespace, while still running outside the pod. With this approach, the traffic redirection between ztunnel and application pods happens in a way that’s very similar to sidecars and application pods today and is strictly invisible to any Kubernetes primary CNI operating in the node network namespace. Network policy can continue to be enforced and managed by any Kubernetes primary CNI, regardless of whether the CNI uses eBPF or iptables, without any conflict.
Technical deep dive of in-Pod traffic redirection
First, let’s go over the basics of how a packet travels between pods in Kubernetes.
Linux, Kubernetes, and CNI – what’s a network namespace, and why does it matter?
In Linux, a container is one or more Linux processes running within isolated Linux namespaces. A Linux namespace is simply a kernel flag that controls what processes running within that namespace are able to see. For instance, if you create a new Linux network namespace via the ip netns add my-linux-netns command and run a process inside it, that process can only see the networking rules created within that network namespace. It can not see any network rules created outside of it – even though everything running on that machine is still sharing one Linux networking stack.
Linux namespaces are conceptually a lot like Kubernetes namespaces – logical labels that organize and isolate different active processes, and allow you to create rules about what things within a given namespace can see and what rules are applied to them – they simply operate at a much lower level.
When a process running within a network namespace creates a TCP packet outward bound for something else, the packet must be processed by any local rules within the local network namespace first, then leave the local network namespace, passing into another one.
For example, in plain Kubernetes without any mesh installed, a pod might create a packet and send it to another pod, and the packet might (depending on how networking was set up):
- Be processed by any rules within the source pod’s network namespace.
- Leave the source pod network namespace, and bubble up into the node’s network namespace where it is processed by any rules in that namespace.
- From there, finally be redirected into the target pod’s network namespace (and processed by any rules there).
In Kubernetes, the Container Runtime Interface (CRI) is responsible for talking to the Linux kernel, creating network namespaces for new pods, and starting processes within them. The CRI then invokes the Container Networking Interface (CNI), which is responsible for wiring up the networking rules in the various Linux network namespaces, so that packets leaving and entering the new pod can get where they’re supposed to go. It doesn’t matter much to Kubernetes or the container runtime what topology or mechanism the CNI uses to accomplish this – as long as packets get where they’re supposed to be, Kubernetes works and everyone is happy.
Why did we drop the previous model?
In Istio ambient mesh, every node has a minimum of two containers running as Kubernetes DaemonSets:
- An efficient ztunnel which handles mesh traffic proxying duties, and L4 policy enforcement.
- A
istio-cninode agent that handles adding new and existing pods into the ambient mesh.
In the previous ambient mesh implementation, this is how application pod is added to the ambient mesh:
- The
istio-cninode agent detects an existing or newly-started Kubernetes pod with its namespace labeled withistio.io/dataplane-mode=ambient, indicating that it should be included in the ambient mesh. - The
istio-cninode agent then establishes network redirection rules in the host network namespace, such that packets entering or leaving the application pod would be intercepted and redirected to that node’s ztunnel on the relevant proxy ports (15008, 15006, or 15001).
This means that for a packet created by a pod in the ambient mesh, that packet would leave that source pod, enter the node’s host network namespace, and then ideally would be intercepted and redirected to that node’s ztunnel (running in its own network namespace) for proxying to the destination pod, with the return trip being similar.
This model worked well enough as a placeholder for the initial ambient mesh alpha implementation, but as mentioned, it has a fundamental problem – there are many CNI implementations, and in Linux there are many fundamentally different and incompatible ways in which you can configure how packets get from one network namespace to another. You can use tunnels, overlay networks, go through the host network namespace, or bypass it. You can go through the Linux user space networking stack, or you can skip it and shuttle packets back and forth in the kernel space stack, etc. For every possible approach, there’s probably a CNI implementation out there that makes use of it.
Which meant that with the previous redirection approach, there were a lot of CNI implementations ambient simply wouldn’t work with. Given its reliance on host network namespace packet redirection – any CNI that didn’t route packets thru the host network namespace would need a different redirection implementation. And even for CNIs that did do this, we would have unavoidable and potentially unresolvable problems with conflicting host-level rules. Do we intercept before the CNI, or after? Will some CNIs break if we do one, or the other, and they aren’t expecting that? Where and when is NetworkPolicy enforced, since NetworkPolicy must be enforced in the host network namespace? Do we need lots of code to special-case every popular CNI?
Istio ambient traffic redirection: the new model
In the new ambient model, this is how application pod is added to the ambient mesh:
- The
istio-cninode agent detects a Kubernetes pod (existing or newly-started) with its namespace labeled withistio.io/dataplane-mode=ambient, indicating that it should be included in the ambient mesh.- If a new pod is started that should be added to the ambient mesh, a CNI plugin (as installed and managed by the
istio-cniagent) is triggered by the CRI. This plugin is used to push a new pod event to the node’sistio-cniagent, and block pod startup until the agent successfully configures redirection. Since CNI plugins are invoked by the CRI as early as possible in the Kubernetes pod creation process, this ensures that we can establish traffic redirection early enough to prevent traffic escaping during startup, without relying on things like init containers. - If an already-running pod becomes added to the ambient mesh, a new pod event is triggered. The
istio-cninode agent’s Kubernetes API watcher detects this, and redirection is configured in the same manner.
- If a new pod is started that should be added to the ambient mesh, a CNI plugin (as installed and managed by the
- The
istio-cninode agent enters the pod’s network namespace and establishes network redirection rules inside the pod network namespace, such that packets entering and leaving the pod are intercepted and transparently redirected to the node-local ztunnel proxy instance listening on well-known ports (15008, 15006, 15001). - The
istio-cninode agent then informs the node ztunnel over a Unix domain socket that it should establish local proxy listening ports inside the pod’s network namespace, (on 15008, 15006, and 15001), and provides ztunnel with a low-level Linux file descriptor representing the pod’s network namespace.- While typically sockets are created within a Linux network namespace by the process actually running inside that network namespace, it is perfectly possible to leverage Linux’s low-level socket API to allow a process running in one network namespace to create listening sockets in another network namespace, assuming the target network namespace is known at creation time.
- The node-local ztunnel internally spins up a new proxy instance and listen port set, dedicated to the newly-added pod.
- Once the in-Pod redirect rules are in place and the ztunnel has established the listen ports, the pod is added in the mesh and traffic begins flowing thru the node-local ztunnel, as before.
Here’s a basic diagram showing the flow of application pod being added to the ambient mesh:
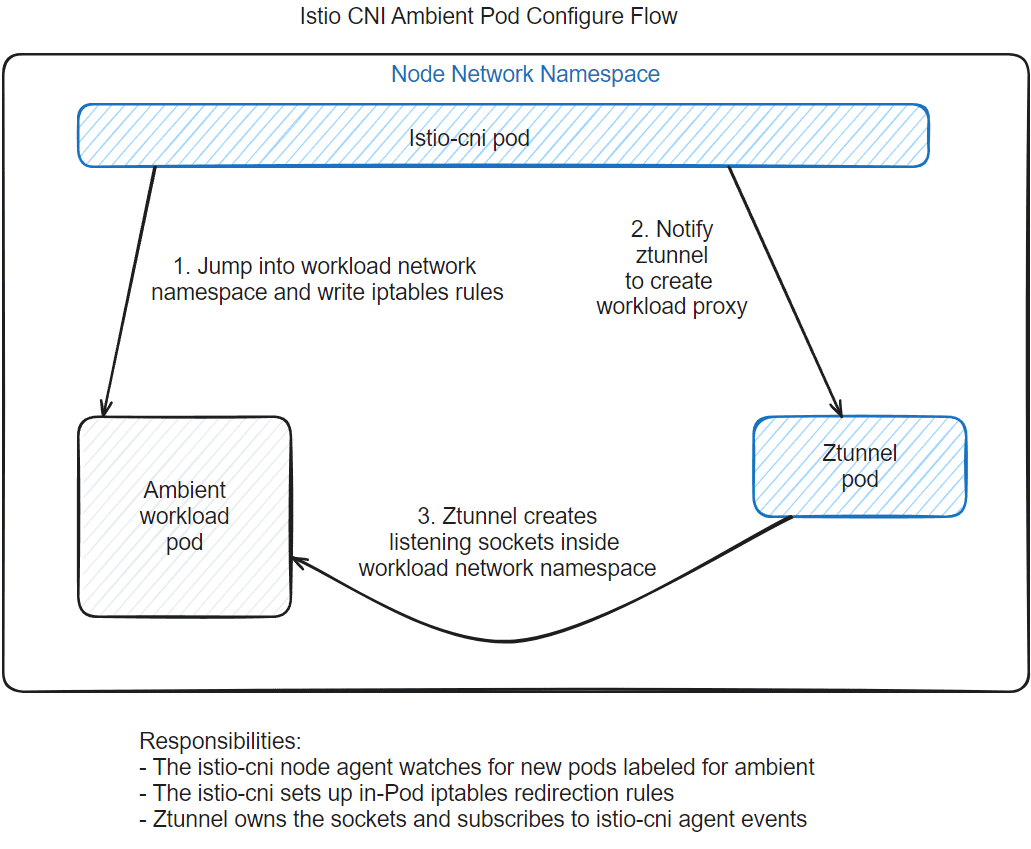
Once the pod is successfully added to the ambient mesh, traffic to and from pods in the mesh will be fully encrypted with mTLS by default, as always with Istio.
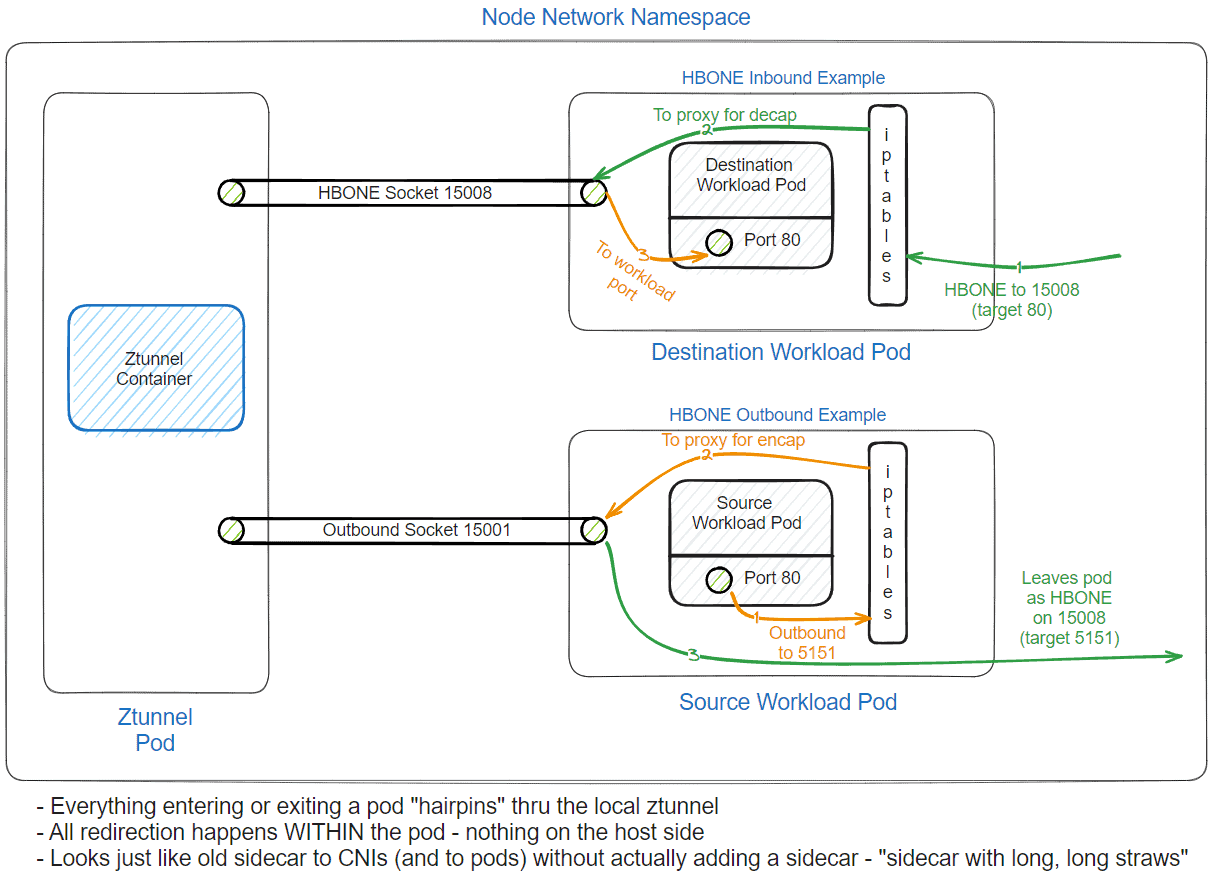
Traffic will now enter and leave the pod network namespace as encrypted traffic – it will look like every pod in the ambient mesh has the ability to enforce mesh policy and securely encrypt traffic, even though the user application running in the pod has no awareness of either.
Here’s a diagram to illustrate how encrypted traffic flows between pods in the ambient mesh in the new model:
And, as before, unencrypted plaintext traffic from outside the mesh can still be handled and policy enforced, for use cases where that is necessary:
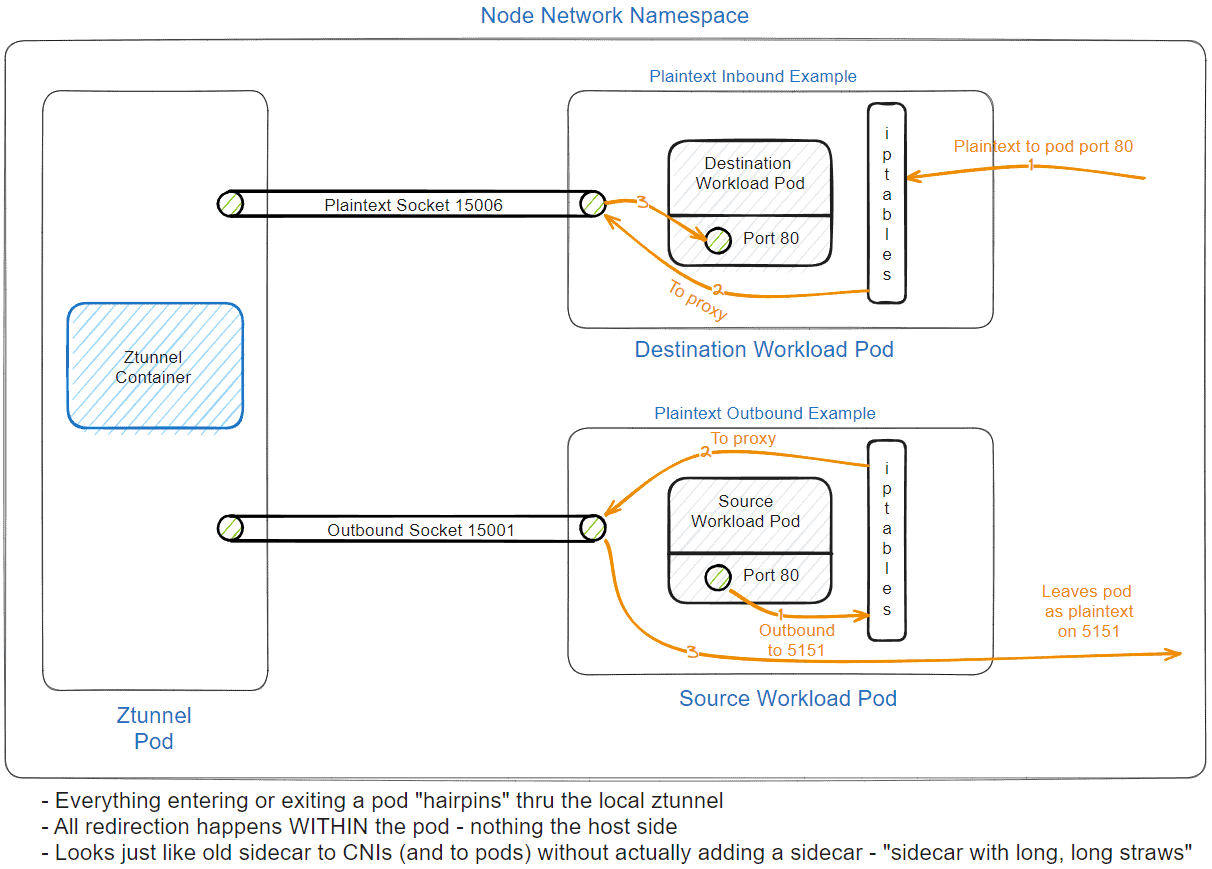
The new ambient traffic redirection: what this gets us
The end result of the new ambient capture model is that all traffic capture and redirection happens inside the pod’s network namespace. To the node, the CNI, and everything else, it looks like there is a sidecar proxy inside the pod, even though there is no sidecar proxy running in the pod at all. Remember that the job of CNI implementations is to get packets to and from the pod. By design and by the CNI spec, they do not care what happens to packets after that point.
This approach automatically eliminates conflicts with a wide range of CNI and NetworkPolicy implementations, and drastically improves Istio ambient mesh compatibility with all major managed Kubernetes offerings across all major CNIs.
Wrapping up
Thanks to significant amounts of effort from our lovely community in testing the change with a large variety of Kubernetes platforms and CNIs, and many rounds of reviews from Istio maintainers, we are glad to announce that the ztunnel and istio-cni PRs implementing this feature merged to Istio 1.21 and are enabled by default for ambient, so Istio users can start running ambient mesh on any Kubernetes platforms with any CNIs in Istio 1.21 or newer. We’ve tested this with GKE, AKS, and EKS and all the CNI implementations they offer, as well as with 3rd-party CNIs like Calico and Cilium, as well as platforms like OpenShift, with solid results.
We are extremely excited that we are able to move Istio ambient mesh forward to run everywhere with this innovative in-Pod traffic redirection approach between ztunnel and users’ application pods. With this top technical hurdle to ambient beta resolved, we can’t wait to work with the rest of the Istio community to get ambient mesh to beta soon! To learn more about ambient mesh’s beta progress, join us in the #ambient and #ambient-dev channel in Istio’s slack, or attend the weekly ambient contributor meeting on Wednesdays, or check out the ambient mesh beta project board and help us fix something!