




Member post originally published on Bouyant’s blog by Scott Rigby
Progressive delivery is a vital tool for ensuring that new code is deployed safely to production with automated protections if things go wrong. But how do we accomplish this on Kubernetes? Tools like Argo, Flux, and even service meshes like Linkerd provide different parts of the puzzle. In this post we’ll walk you through what you need to know to gracefully roll out progressive delivery in Kubernetes.
This post begins by summarizing the concepts and options for implementing progressive delivery on Kubernetes. It clarifies what a service mesh like Linkerd adds to this, and explains when and why you would want to use each deployment strategy. If you’re already clear on all this, you may want to skip to the comparison at the end.
I’ll compare the two leading progressive delivery tools—Flagger and Argo Rollouts–in a head to head battle for the progressive delivery crown! I’ll cover how they differ and overlap, their compatibility with GitOps tools, and what use cases each primarily caters to. After reading this post, you should feel have the insights you needto make informed decisions about progressive delivery tailored to your unique deployment needs.
What is progressive delivery?
Progressive delivery is a powerful technique that allows you to detect and roll back any problems with a new application version during the release process itself. It’s not a replacement for pre-deployment testing, or post-deployment monitoring with a full rollback strategy if it later becomes necessary. Instead, progressive delivery minimizes the need for the latter by rolling out a new version incrementally, allowing its success to be evaluated at each step and rolled back whenever needed, before it reaches your entire audience.
This incremental testing can be done automatically, manually, or a combination of the two. We’ll get into this more later in the tool comparison. But either way, the end goal is the same: to figure out if a new release update meets your standards for success before it’s fully deployed. These standards can include internal error thresholds, latency checks, and any other measurable service level indicator information that fits your team’s SLOs or SLAs.
To get this measurable information, your applications need traffic, which can be generated in different ways depending on your needs. You can choose to have this traffic come from either random users, a select group of users, or mock traffic, and these choices directly map to known deployment strategies for progressive delivery. So what are those strategies?
Deployment strategy choices
These strategies can be thought about in terms of how end user traffic is handled at what stage of updating an application or system from a previous version to a new version.
Canary Release
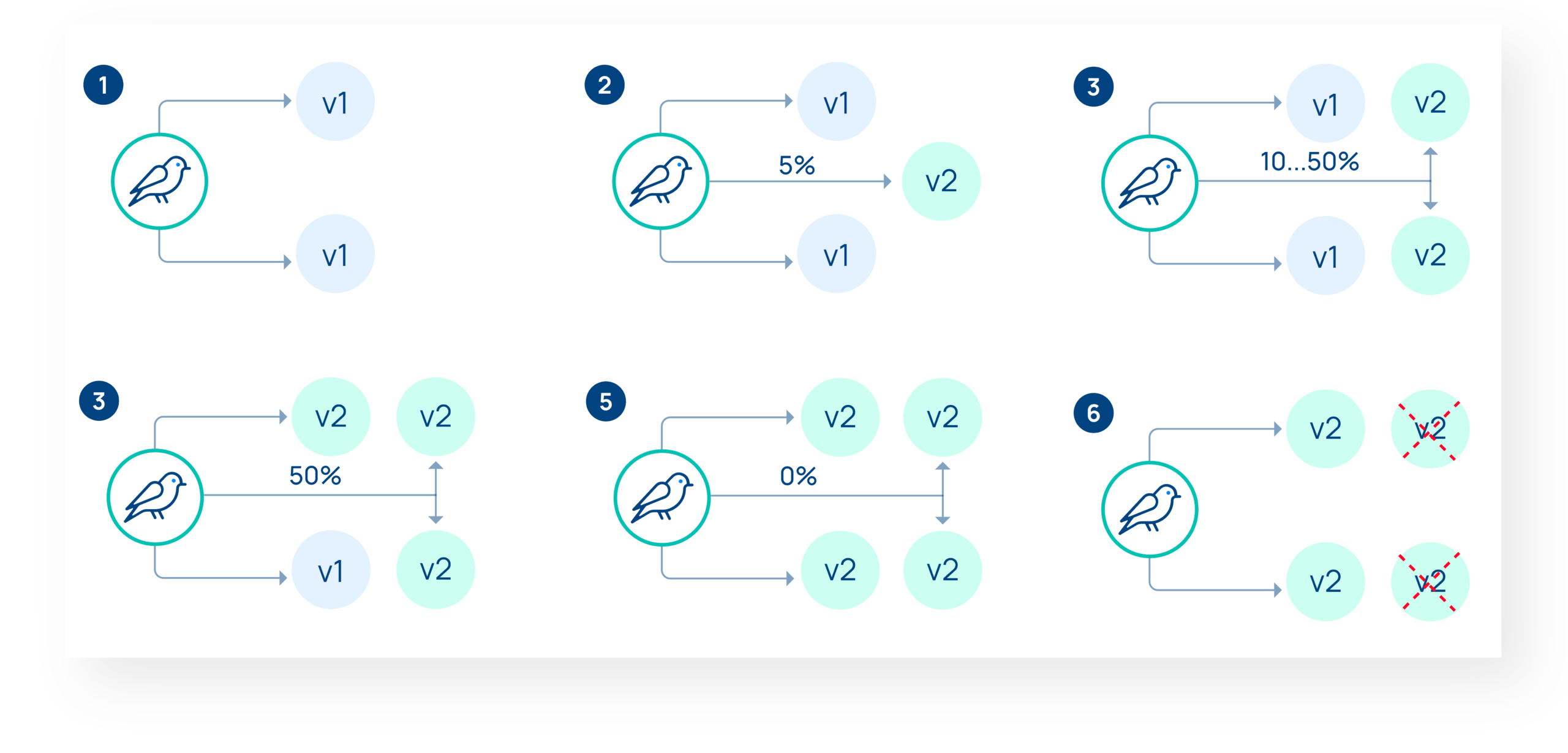
Canary release is progressive shifting by percentage of production traffic from the previous version of an application to a new version, with analysis along the way, and the ability to roll back at any point if the analysis doesn’t meet your expectations. Any user might experience either version of the application during this traffic shift. See Canary Deployment in the CNCF Glossary to learn more.
A/B Testing or Experiments
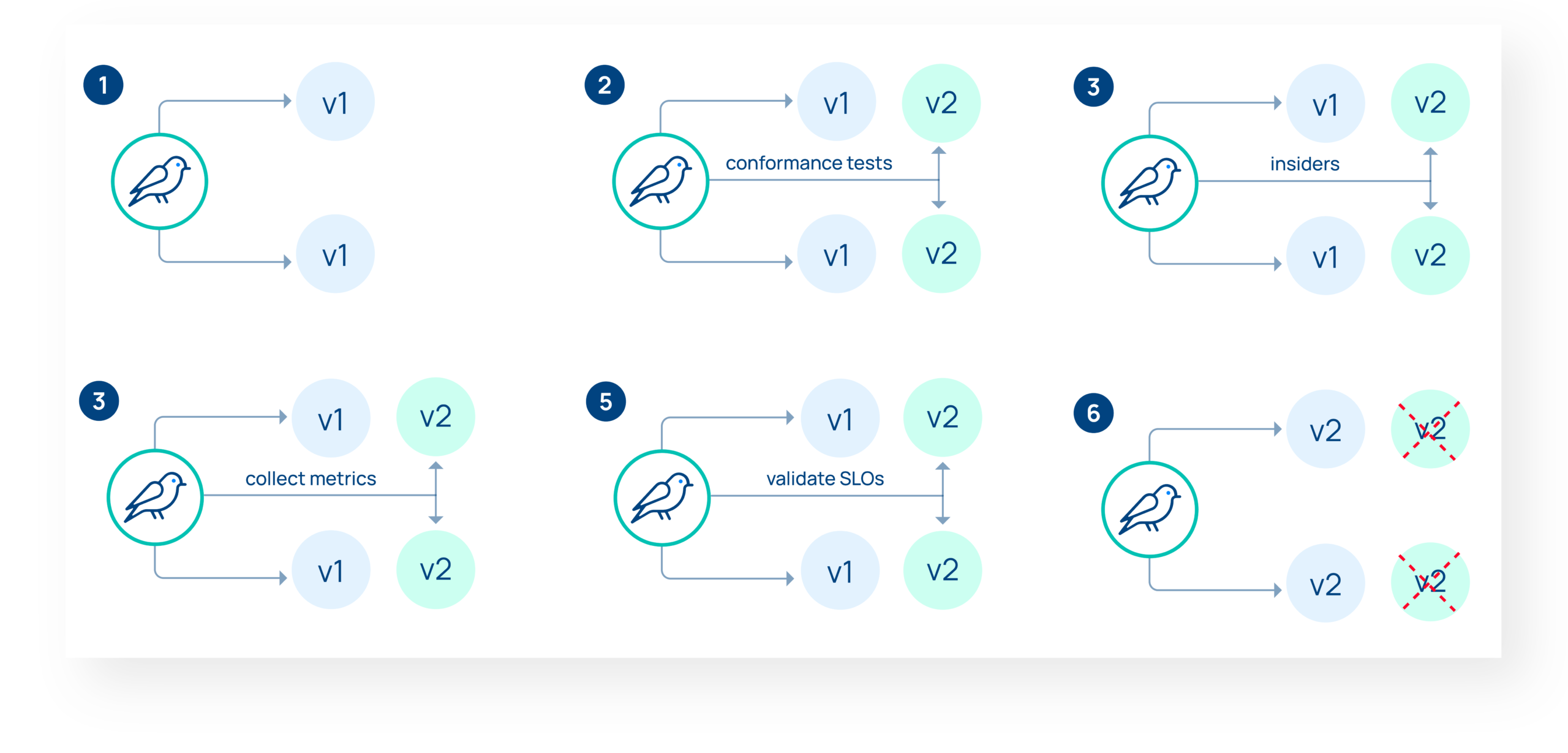
A/B testing is all about making sure that a select group of users will stay on the new version for the whole duration of the test. This is critical for applications that require session affinity (like many front end applications) or for some kinds of larger changes, and is usually done with HTTP header matching or cookies. Sometimes referred to as A/B/C testing, because you may want to gather data from multiple subsets of users testing different features. Argo Rollouts calls these “experiments”.
Blue/Green
Blue/Green deployments are all about testing with no end user involvement, and then once tests pass switching live traffic to the new version all at once. Testing usually involves simulated traffic to green until everyone is happy. After green is live, blue is kept for a period of time in case actual live traffic causes the need for rollback. See Blue-Green Deployment in the CNCF Glossary to learn more.
For more information about the differences between all of these strategies, see Flagger’s Deployment Strategies documentation, as well as Argo Rollouts documentation on Canary, Experiments, Blue/Green, and summaries on their Concepts page.
What does a service mesh bring to progressive delivery?
A service mesh is an optional component of a progressive deployment strategy, but it’s a powerful one. One big benefit is that it adds additional Deployment Strategy options. Several extensions of the strategies listed above are only possible with the addition of a compatible service mesh. Depending on the scale of your deployments and the amount of risk you are willing to tolerate, a service mesh like Linkerd can be a critical part of your progressive deployment strategy.
Session Affinity for Canary Release
If you want to extend your Canary with sticky sessions, both Flagger and Argo Rollouts support this, effectively mixing Canary with A/B testing. This means once a user is routed to a Canary using weight-based routing, they are, from that point on, always routed to that version using a cookie. This is helpful for applications that may break if a user is routed to a new version and then back to the old version in different requests. For more details, see Flagger Canary Release with Session Affinity, and Argo Rollouts header-based traffic routing for Canary.
Traffic Mirroring for Blue/Green
You can also extend Blue/Green by mirroring (or shadowing) traffic, with both Flagger and Argo Rollouts, when used with certain service meshes, including Linkerd. Traffic Mirroring copies requests made to the primary to simultaneously also send to the canary. No responses from canary sent back to the user – the requests are mirrored only for the purpose of collecting metrics to determine canary health. You should only use this when requests will not harm your application if processed twice. See Flagger’s Blue/Green Traffic Mirroring, and Argo Rollouts traffic mirroring docs for more.
SMI vs Gateway API
Wait, this isn’t a different blog post topic? Bear with me for a sec, Gateway API is relevant to the deployment strategies we’ll be discussing below for progressive delivery.
In a nutshell, if you’ve been one of the many people unsure how long to continue using Service Mesh Interface (SMI) and when or if to adopt the newer Gateway API, the choice has now been made a lot easier. As of last month, it’s officially time for new projects to adopt and existing projects to upgrade to Gateway API.
Quick timeline to put your mind at ease: This summer SMI maintainers joined forces with the Gateway API Kubernetes subproject to consolidate service mesh support under Gateway API, adding east/west traffic (internal service-to-service or service-to-datastore within a Kubernetes cluster) capabilities to existing support for north/south traffic (external ingress or egress between your cluster and end users or outside services). Two months ago, CNCF Announced the SMI project is now archived, and recommended contributors to participate in the consolidated GAMMA initiative. And finally, last month the Gateway API announced a v1.0 General Availability (GA) release, so it’s ready for production.
Gateway API is also supported natively by Flagger, and by Argo Rollouts using a plugin.
So now that you know you’ll be using Gateway API for your networking abstraction layer with Linkerd, what tools should you use for progressive delivery?
Flagger vs Argo Rollouts 🍿

Both part of popular, graduated CNCF projects, Flux and Argo respectively each tie seamlessly into GitOps. Both support advanced Continuous Delivery techniques such as Canary Releases, A/B Testing, and Blue/Green deployment. Both provide extended functionality with a Service Mesh such as Linkerd. So, when it comes to Progressive Delivery, how do you choose?
Architecture comparison
Flagger and Argo Rollouts effectively allow you to do the same things for progressive delivery, but because they are architected differently, that affects how you interact with the K8s objects responsible for each. Here’s a quick breakdown:
Flagger has a Custom Resource Definition (CRD) that holds configurations for your chosen deployment strategy. This CRD does not contain a Pod spec, but only references an existing K8s Deployment object. Based on the referenced Deployment, Flagger creates a second, shadow deployment. So there are two K8s Deployment objects: one for the already deployed application version, and one for the new version being evaluated. Flagger doesn’t modify your application Deployments/ReplicaSets in any way. This allows you to get up and running with Flagger immediately on existing workloads, and to be able to remove Flagger any time, without migration in either direction.
Argo Rollouts takes a different approach. Rather than working with an existing Deployment, it instead replaces the standard K8s Deployment with a custom CRD, which has two different ReplicaSets instead of just one that a Deployment would create. It is up to the user to migrate existing applications from a K8s Deployment to an Argo Rollouts CRD. However, this is generally seen as less complicated to understand than Flagger’s shadow deployment approach, making Rollouts easier to reckon with if any problems arise.
Apart from this major difference in approach, there are mostly minor differences between how Flagger and Argo Rollouts work. Flux and Argo Rollouts effectively can accomplish the same things – with different levels of effort either on the setup side (Argo Rollouts) or the conceptual learning curve side (Flagger).
Extensibility and flexibility
Flagger and Argo Rollouts are both flexible and extensible, using different methods requiring more or less effort depending on your use case.
Flagger webhooks add additional flexibility to progressive delivery. Flagger calls webhooks at every stage of the analysis. Here is an example case study published by Blinkit, explaining how they extended Flagger’s capabilities by adding an additional webhook to meet their needs. Now after each traffic percentage increment, Flagger informs you how it went so at any point, you can send a webhook to roll back the deployment if something wasn’t what you expected. See the Flagger webhooks documentation page for reference.
Argo Rollouts also has webhooks that allow manual gating at the Analysis stage. You can tell analysis to make an HTTP call to some endpoint, then interpret the response to decide if it is okay to proceed. If you don’t want to write a webhook, you can pause by patching the rollout object, so that the canary will not proceed to the next step until unpaused through another patch (both their CLI and web UI offer convenient ways to do this). In addition to the web metric Argo Rollouts allows you to use a job, so you can script a solution. If these don’t suit your use case then you can write your own plugin. See Argo Rollouts web metrics and plugin system documentation to learn more.
GitOps compatibility
What if you want to do progressive delivery with GitOps?
Both Argo Rollouts and Flagger can work independently of any other tooling. But if you do also want to manage your systems with GitOps, you’re in luck.
Flagger is part of the Flux project; as such, it is tested regularly to ensure they work seamlessly together. Similarly, Argo Rollouts was built as part of the Argo suite and is regularly tested to work seamlessly with – you guessed it – ArgoCD.
But does this mean when doing GitOps and progressive delivery, you should always pair Flagger with Flux, and Argo Rollouts with ArgoCD? You don’t necessarily have to. Argo Rollouts can be used with Flux, even if there have been some reported minor problems (see this discussion for details). And Flagger can also work with ArgoCD. There is even a Flagger health check bundled with ArgoCD (ArgoCD maintainer confirms). Most users choose their progressive delivery tool from within the same ecosystem, but you may want to cross over if you have a major preference for any of the differences between Rollouts and Flagger mentioned in this post, and that happens to be in the other ecosystem to your chosen GitOps tool. Whatever the reason, if you do choose to use GitOps with progressive delivery, you can use either Flagger or Argo Rollouts with either Flux or ArgoCD without fear of compatibility lock-in.
Seeing is believing
Let’s take a look at how Flagger and Argo Rollouts stack up in terms of a web UI for visualization of progressive delivery activity.
When each is used entirely on its own, or even with their parent projects – Argo CD and Flux, respectively – this is an area where Argo Rollouts wins. Argo Rollouts comes with its own standalone UI. However, Rollouts maintainers recommend the Argo CD UI rollout extension for a nicer experience visualizing Rollouts – as long as you’re using ArgoCD too. Flagger, on the other hand, has no standalone UI. The makers of Flagger – Weaveworks – did create a dashboard for Weave GitOps Enterprise that displays Flagger activity, however, this is not present yet in the Weave GitOps OSS (free) version.
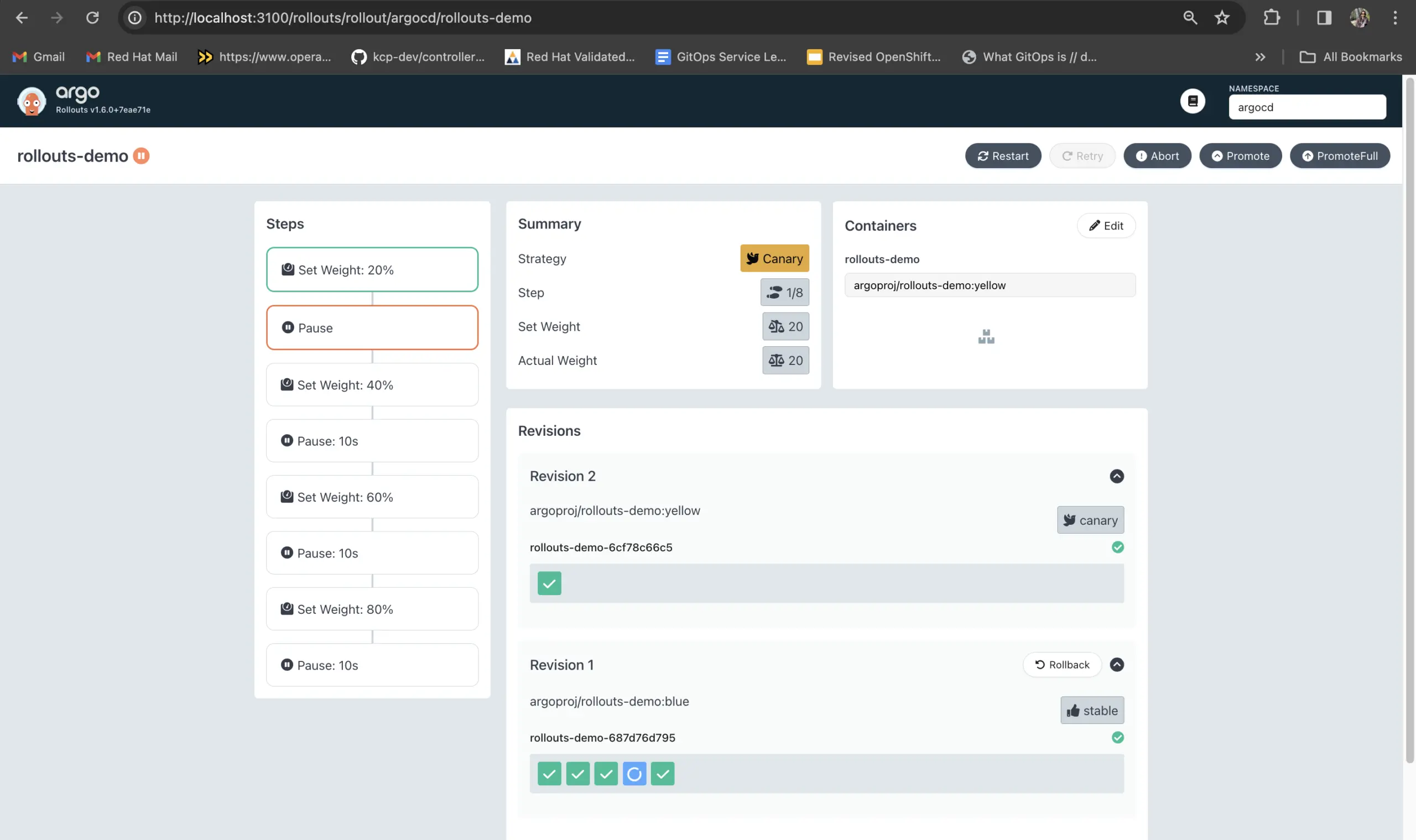
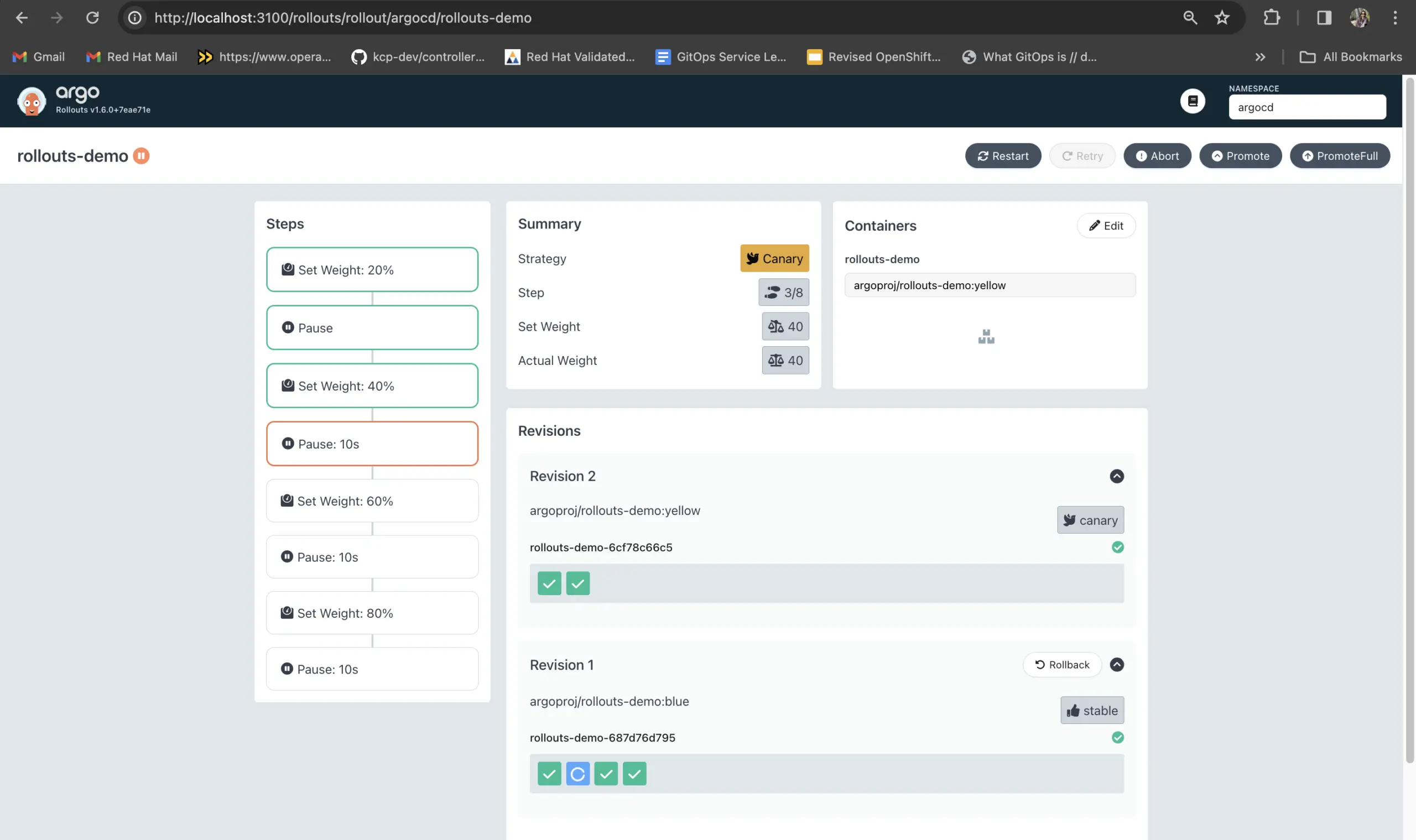
The good news for Flagger? There are good visualization options when paired with other tools. Flagger comes with a custom Grafana Dashboard made for Canary analysis. However, the Flagger team did not build a Linkerd dashboard just for Flagger, for one simple reason – there’s no need! The Linkerd UI already provides an easy to follow visualization of Flagger activity, and is recommended by Flagger maintainers as the best dashboard for viewing its activity. This is because Linkerd understands everything Flagger does, and – unlike Rollouts – Flagger creates two deployments (see architecture comparison), so you can see everything that happens with traffic switching in real-time.
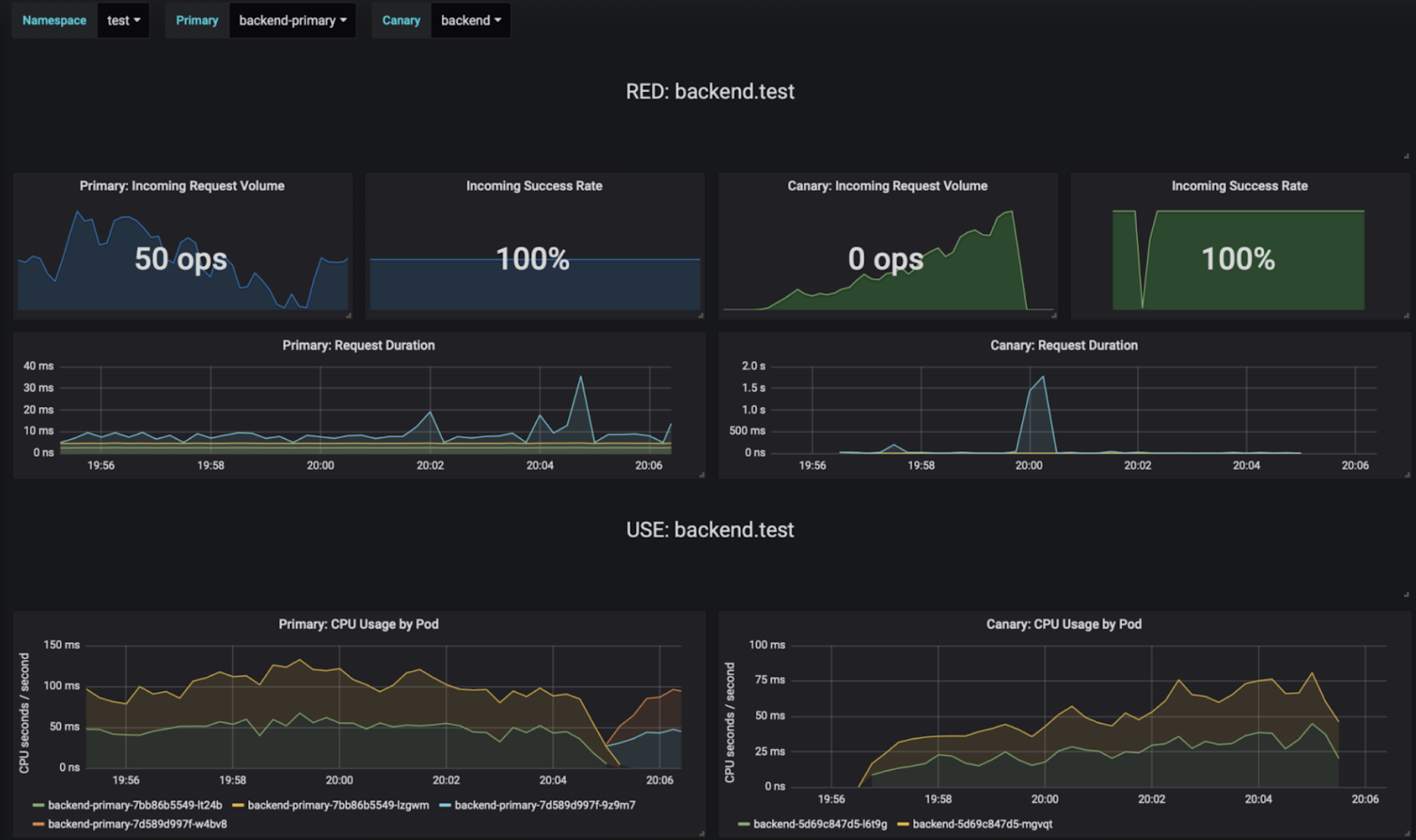
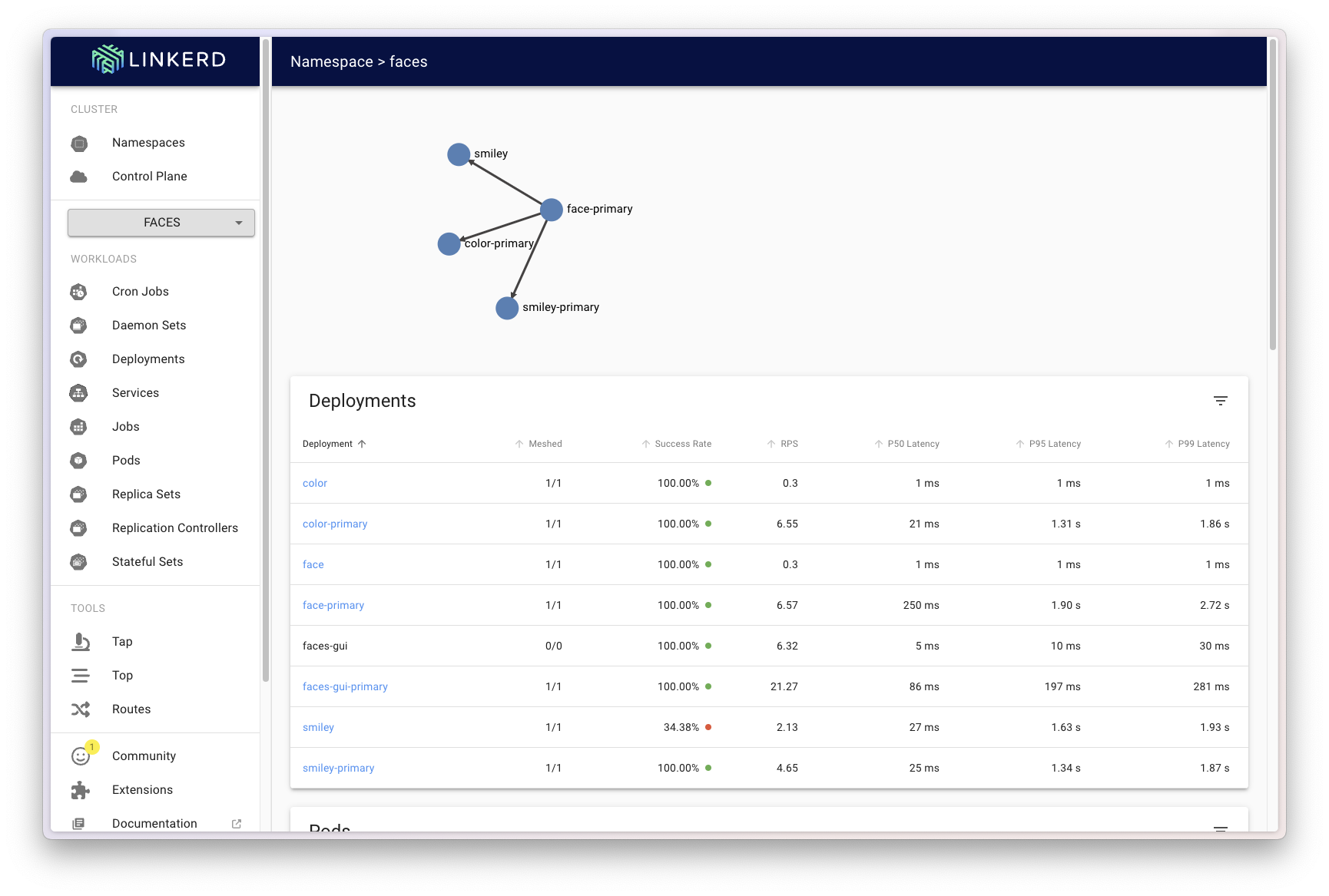
The final call about which of the two is a better user experience – visualizing Argo Rollouts in Argo CD, or visualizing Flagger in Linkerd – is up to user preference. In my opinion, both visualize the information you need to know to monitor progressive delivery well. This is true whether you’re fully automating or manually guiding your progressive delivery.
Manual or automated analysis
It’s important to ask yourself whether you want to automate your progressive delivery or monitor and progress traffic shifting manually. However, you don’t have to know the answer fully before you get started with either tool.
As mentioned above, you can configure both Flagger and Argo Rollouts to do roughly the same things for progressive delivery. Both can accommodate either a fully automated or manually guided progressive delivery experience, as well as many use cases in-between. One of the biggest differences between the two tools, however, is which use cases the defaults for each primarily cater to.
In short, Flagger’s defaults cater to use cases around automated progressive delivery and rollbacks, while Argo Rollouts’ defaults cater to use cases that require manual guidance through those processes. Flux is easier to set up, get started, and see value immediately. Argo Rollouts is easier to reason about when things go wrong.
With Flagger, you can follow a tutorial and be up and running using any of the above deployment strategies with a sample app on Linkerd in 5 minutes. Flagger has sensible defaults for automating rollbacks based on common metrics that are also easy to configure and extend. It comes with an automated traffic generator to test your progressive delivery setup in non-production environments before you set it up in production (because all of these deployment strategies require traffic), and many other niceties that go unnoticed by design for a seamless developer experience. These defaults work particularly well for modern applications – whether stateless or stateful – that are more tolerant of rollbacks without manual intervention steps by a development or platform team. Flagger also includes predefined default templates for every major service mesh and Ingress controller to get you going right away. However, the tradeoff is that, because all this seamless integration is hidden by design, Flagger is more complicated to reason about and debug when automation goes wrong.
Argo Rollouts requires more manual setup to get the same kinds of automation that Flux gives you out of the box. Argo Rollouts gives basic and flexible primitives and building blocks, but provides fewer opinionated defaults and does not include predefined default templates and examples for other service meshes and Ingress controllers. But while more complicated to set up, Argo Rollouts is easier to understand and troubleshoot when things go wrong precisely because it’s doing less magic under the hood.
And just as Argo Rollout allows you to set up full automation if you want to put in the work, Flagger also allows you to set up the same kinds of pauses, gates, and other steps for a more manually guided experience if you wish. Each requires some extra work needed to accommodate its non-default use case.
Better together?
Probably not. But maybe? There’s certainly nothing stopping you from using both Flagger and Argo Rollouts for progressive delivery of different applications on the same cluster, as long as you pay attention to a few caveats. In a similar vein, you can run both of their connected GitOps projects – Flux and Argo CD – on the same cluster, as long as you don’t configure both tools to try managing the same resources. It may even be a good idea for evaluation purposes to run them all in the same cluster, and who knows, maybe you’ll find that your team enjoys using them all at the same time – there are some known use cases that call for this. Open source interoperability FTW!
Conclusion
Which tool wins the progressive delivery crown really depends on your use case. 👑🙋
Some questions to ask yourself:
- Which deployment strategies would give each of my apps end users the most seamless experience during upgrades?
- Do I want progressive delivery for my existing workloads or only new ones?
- What level of visualization do I need for progressive delivery activity?
- Can my apps handle automated delivery and rollbacks or do they require manual guidance?
- Do I want my setup experience tailored to starting immediately with common case automation, or do I want it tailored to building a bespoke solution
Keep in mind that progressive delivery is a journey, not a destination, and as such, it can be… progressive! Start where you’re at now and experiment with what works best for you. You can always add, modify, or replace things later.
Give it a try!
Hopefully at this point we’ve guided you through your decisions around Argo vs Flux. It’s time to give it a try and see for yourself how it works. Install Linkerd today and unlock the full potential of your progressive delivery strategy!
💖 Big thanks to people from all three projects – Jesse Suen (Argo Rollouts maintainer), Ishita Sequeira (ArgoCD maintainer), Stefan Prodan (Flagger creator and maintainer), Sanskar Jaiswal (Flagger maintainer), Jason Morgan and Flynn (Linkerd evangelists) – who both agreed to be interviewed at the beginning of this idea, and who also reviewed this post all along the way.