
Member post by Sergey Pronin, Percona
Before joining Percona almost 4 years ago I was a strong believer of the “Kubernetes is for stateless” and 12-factor apps approach. But there are two north stars that were guiding Percona’s leadership to prove it otherwise:
- Kubernetes adoption growth, that was an indicator that it will become a de-facto choice for platform builders, including stateful apps.
- Open Source and no-vendor lock-in narrative that Percona strongly protects and Kubernetes provides out of the box. You can run your favorite orchestrator in any cloud and on-prem, and have the same APIs. You have full freedom to migrate from one cloud to another.
This is how I started working on Kubernetes Operators for Databases. For the last few years we saw a hockey-stick adoption growth for databases on kubernetes not only in Percona, but also in the community. DoKC – Data on Kubernetes Community – when we joined had less than 100 participants, whereas today it is getting closer to 5000.
MongoDB is by far the most popular Document database and Percona happens to provide a source-available Percona Server for MongoDB and the Operator for it. Percona Operator for MongoDB is 100% open source and comes with various production-grade features that are available for free for everyone. We accumulated a lot of knowledge on how users and customers deploy and manage MongoDB on Kubernetes. In this blog post we will share the best practices and architecture recommendations to run production-grade MongoDB on Kubernetes. We will look at it through these three dimensions: Availability, Performance and Security.
MongoDB on Kubernetes – 101
Even though MongoDB is one of the most popular databases in the world, there are not a lot of solutions available to run it in Kubernetes. I looked into available options in this blog post.
MongoDB is quite a complex database, especially when it comes down to sharding, arbiters, and non-voting members. Don’t get me started on multi-kubernetes. With this complexity in mind, it is obvious that good tooling is required to automate the deployment and management. Operators are good at removing toil, fully automating deployment and management of complex applications on Kubernetes. User specifies the desired state in the Custom Resource manifest and Operator does the rest automagically:
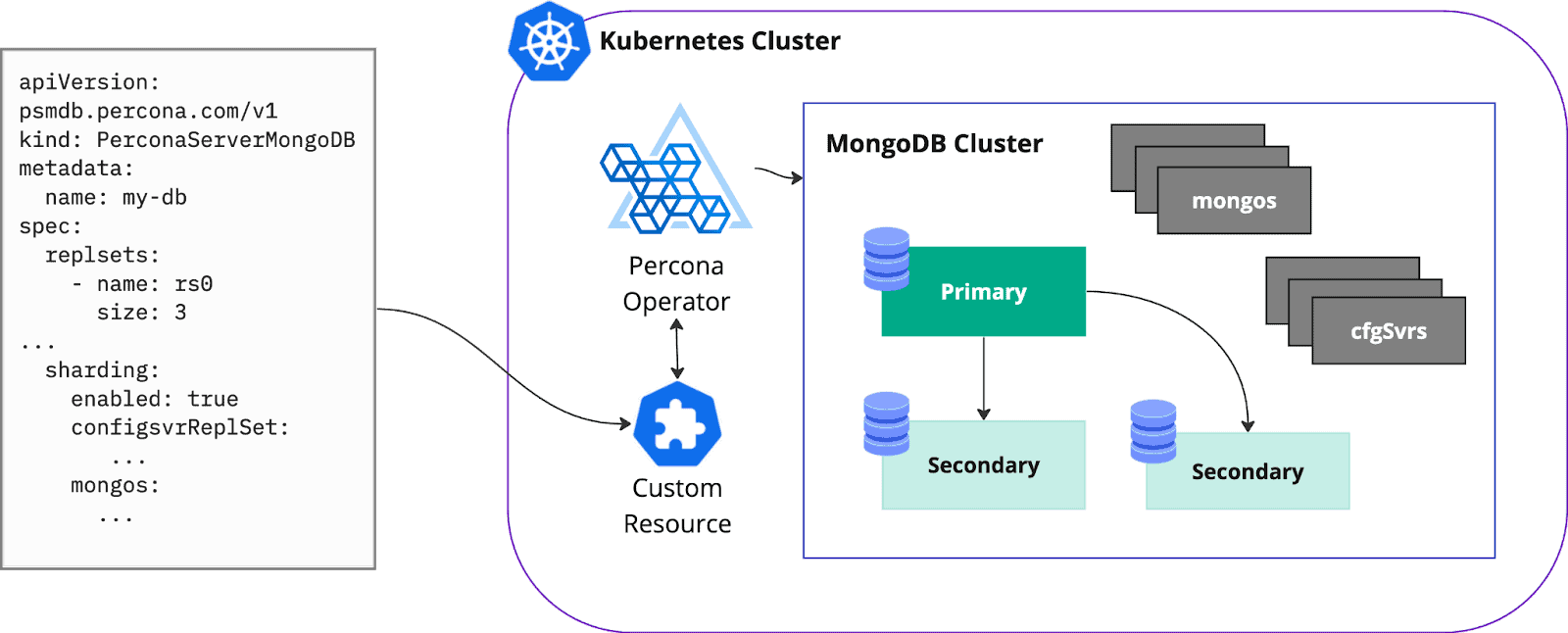
Availability
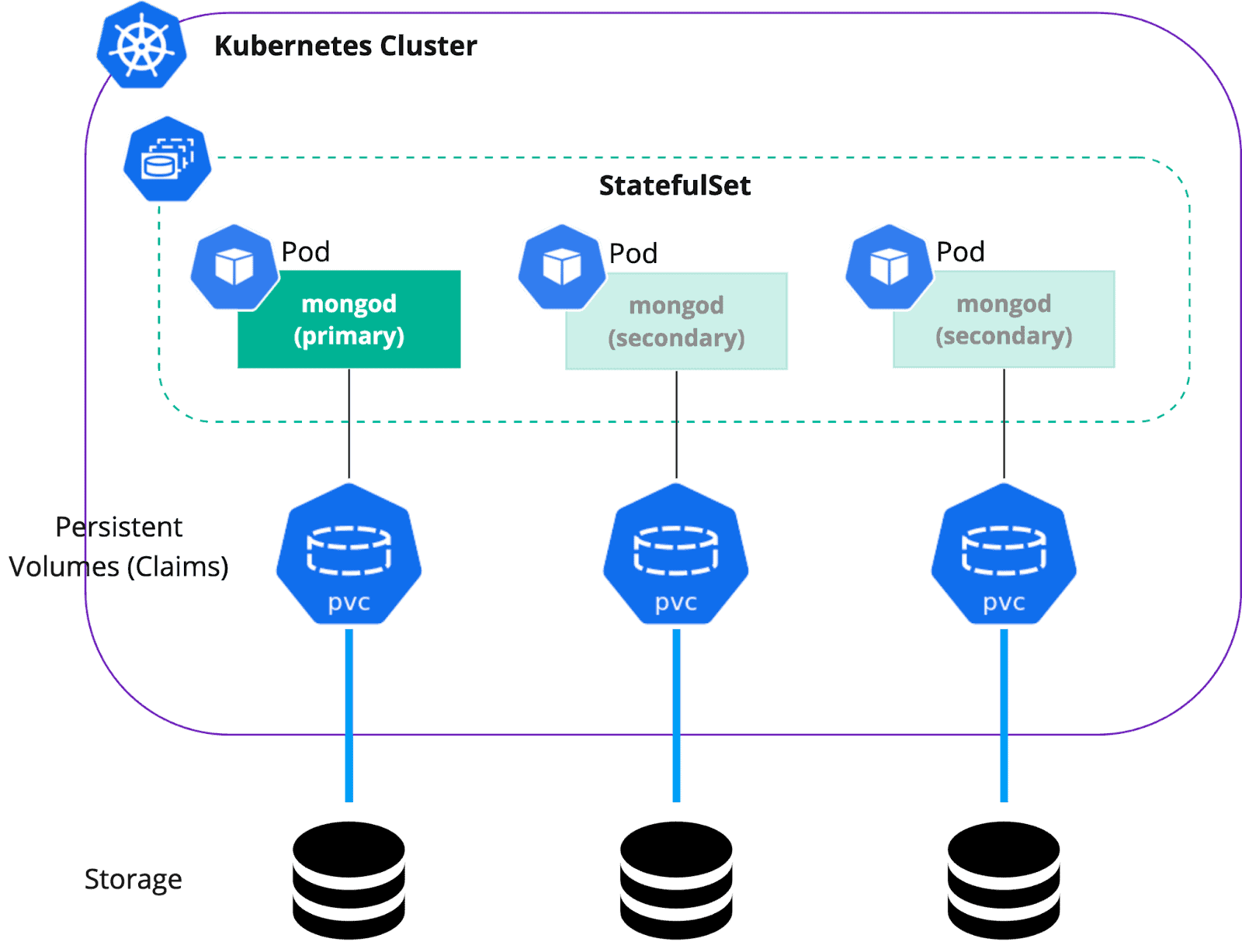
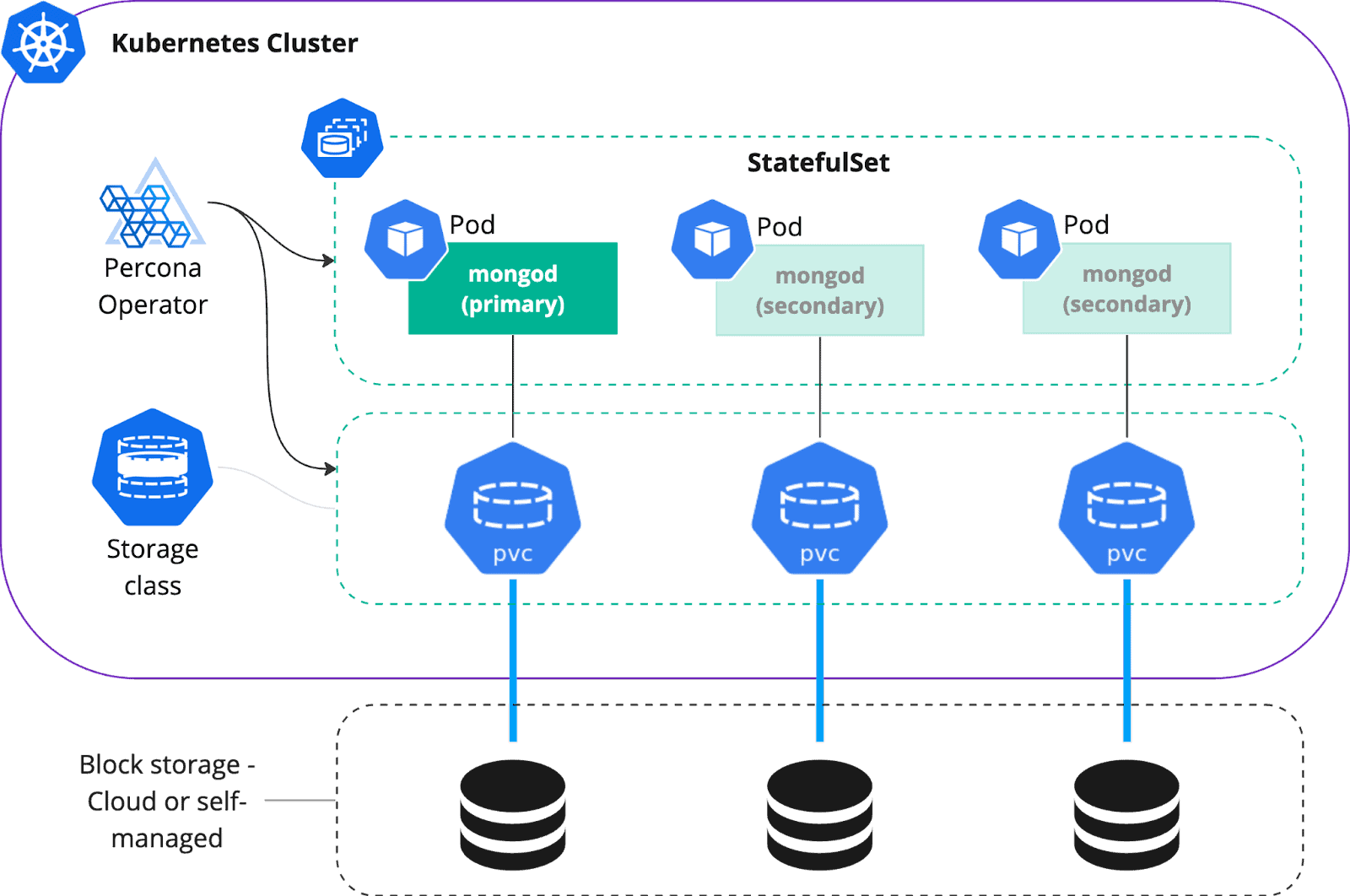
Replica Set
First off, we want our MongoDB to be highly available. This can be done through a replica set – a group of mongod processes that maintain the same dataset. In Kubernetes, a single mongod node is represented by a container (and a Pod) and a replica set is usually a StatefulSet resource.
Affinity
We don’t want our replica set nodes to land on a single Kubernetes Worker Node, because it becomes a single point of failure. With affinity and anti-affinity it is possible to define various constraints and enforce scheduling to different worker nodes or even availability zones (AZ).
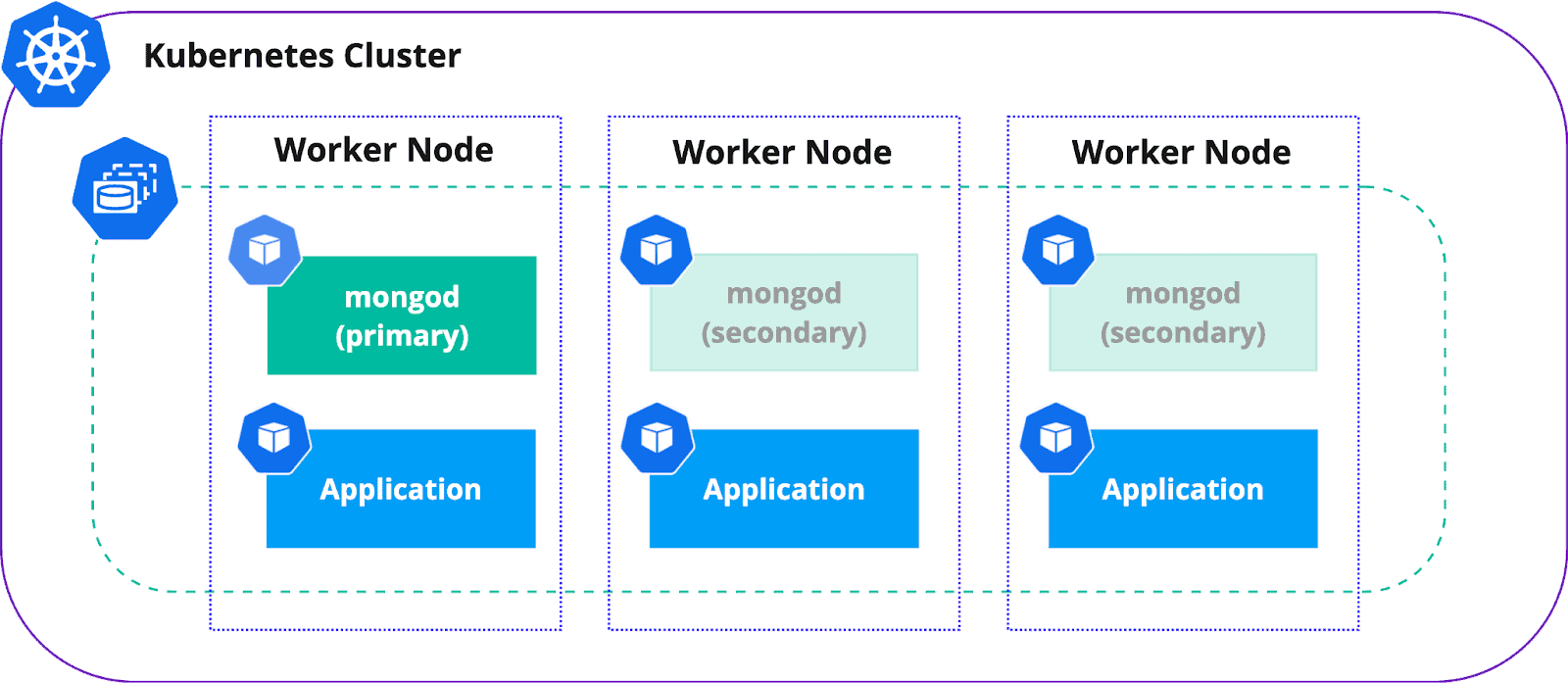
It might also be wise to run applications and databases on separate nodes. What we see a lot is having nodes dedicated to databases, especially for production environments. This isolation helps with both availability and performance, as application usage spikes do not interfere with database resources needs.
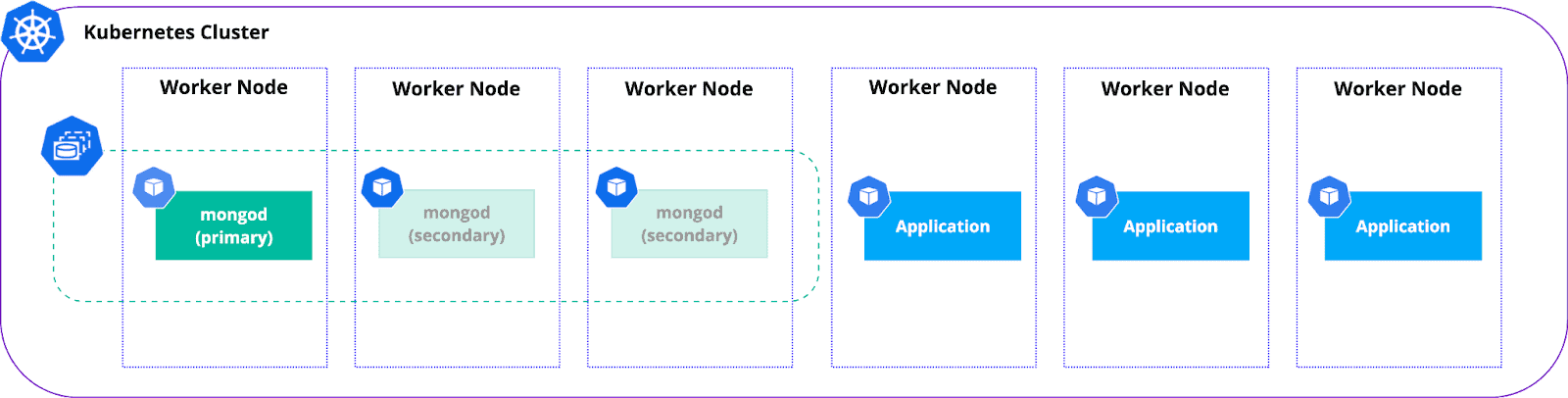
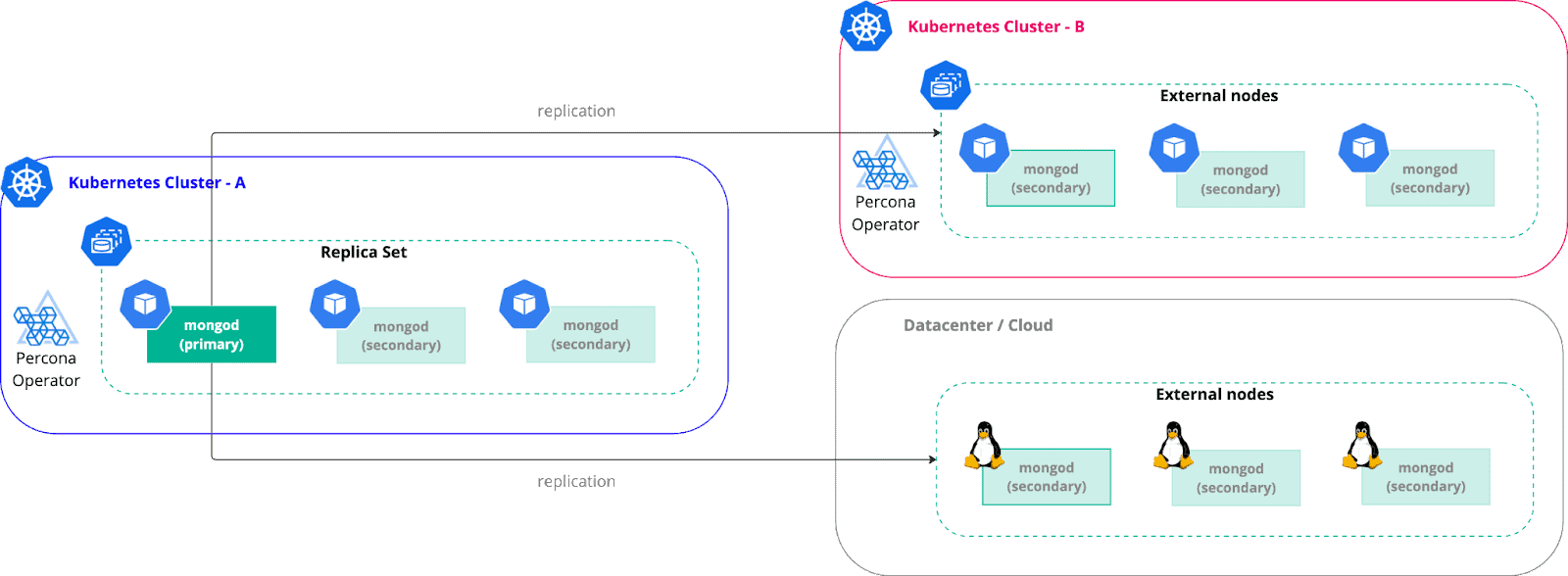
Beyond the Single Kubernetes cluster
Sometimes it is required to go beyond the single Kubernetes cluster. There might be various reasons for this:
- Disaster Recovery requirements
- Geo distribution of the data
- Migrations
In MongoDB this can be done through adding more nodes into a replica set. These nodes can be outside of Kubernetes at all, and run on a virtual machine or bare metal. If you want to run across 2 or more Kubernetes clusters and leverage Operator features, with Percona Operator you need to have an operator per cluster.
Performance
It is important to understand that there is no performance degradation on Kubernetes compared to virtual machines or regular servers, if k8s is configured correctly and uses the same hardware.
Compute
Compute resources – CPU and Memory – in Kubernetes are controlled through requests and limits. Requests – is how much resources you think your application needs. Kubernetes uses requests to make scheduling decisions – puts the Pod on the node that has the required amount of resources. Limits – is a hard limit, which maps to cgroup limits in Linux.
As recommended above, we recommend isolating production database nodes on separate machines. This way, your limit would equal the machine’s capacity.
If you make a decision to share resources of a worker node with other applications, it is strongly recommended to set requests equal to limits. This way your Pod gets assigned a guaranteed Quality of Service (QoS) class and guaranteed performance:
resources:
requests:
cpu: 2
memory: 4G
limits:
cpu: 2
memory: 4G
Storage
Database performance heavily depends on storage. Storage in Kubernetes is managed by Container Storage Interface (CSI). It provides the user with various resources and APIs to manage volumes. The main resource is StorageClass – it delivers a way to describe the required storage that will be used by the application eventually. Kubernetes cluster administrators can specify storage type (io3, gp3, etc), IOPs, filesystem and various other parameters there. Persistent Volumes are created based on the parameters set in the Storage Class. K8S Operators automate the creation of volumes for MongoDB, but StorageClass is something you should create beforehand.
Choosing storage parameters heavily depends on your MongoDB workloads, but usually it is recommended to use SSD-backed storage with high IOPs.
XFS
XFS is a high-performance journaling file system. As per MongoDB documentation: “With the WiredTiger storage engine, using XFS is strongly recommended for data bearing nodes to avoid performance issues that may occur when using EXT4 with WiredTiger.”
Most Container Storage Interfaces allow users to specify a filesystem in a StorageClass resource. Once done, you can reference it in the StatefulSet or in the Operator Custom Resource. The following example sets the XFS filesystem in a storage class managed by AWS EBS CSI which is used in EKS.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: ebs-sc
provisioner: ebs.csi.aws.com
volumeBindingMode: WaitForFirstConsumer
parameters:
csi.storage.k8s.io/fstype: xfs
...Local storage
Most commonly we see the use of network attached storage for stateful workloads in Kubernetes, solutions like AWS EBS, Ceph, etc. But k8s allows you to use the local storage that comes with a worker node, like SSD NVMe. Using those gives an additional boost to your performance and also reduces the cloud bill.

The decision whether to use local storage or not depends on your cost strategy and performance needs. There are also some operational downsides that come with local storage. I wrote about it in this blog post.
Scaling
Scaling in Kubernetes is straightforward and automated by most Operators:
- Vertical scaling – adding more resources (requests and limits) to the containers and worker nodes
- Horizontal scaling – adding more containers
You can scale vertically till you hit the ceiling of the biggest server in the rack. Horizontally you can scale your replica set to up to 50 nodes, but it scales reads only. Where all writes will still land on the primary node. This gets us to sharding.
Sharding
In simple terms, sharding is splitting your dataset into multiple replica sets. This allows you to scale reads and writes horizontally almost indefinitely.
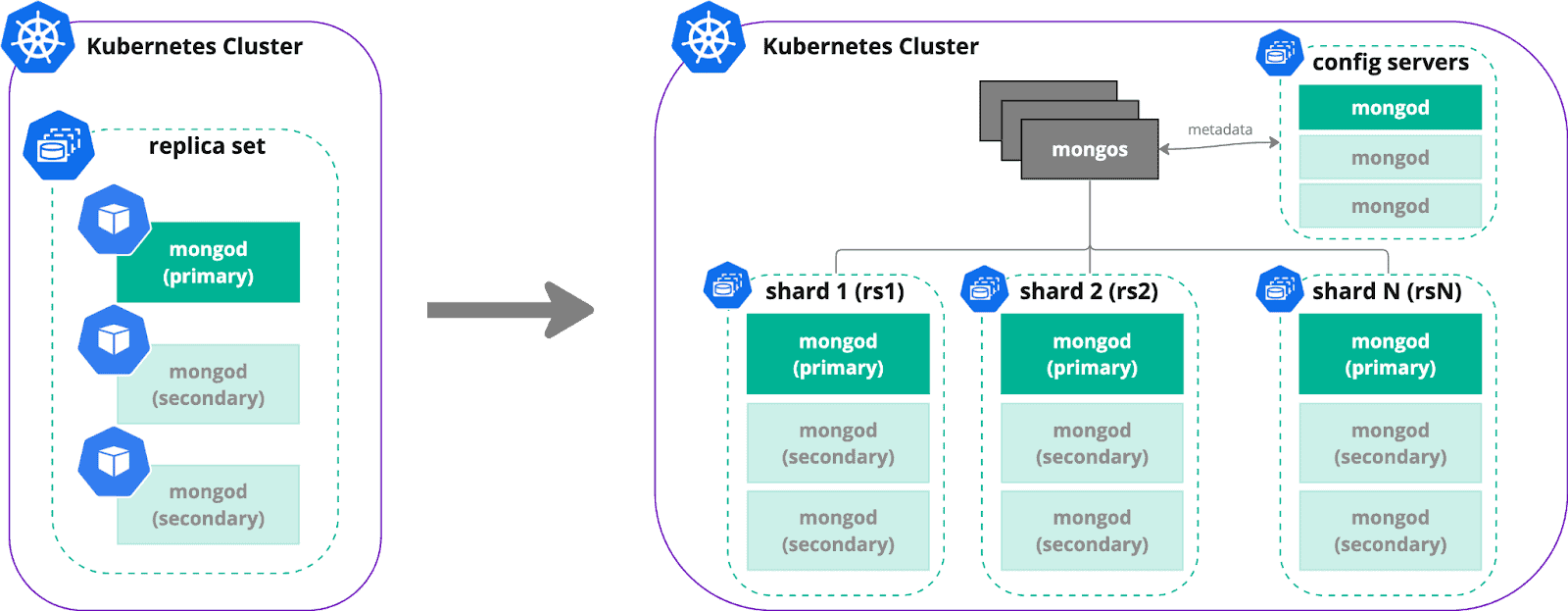
From Kubernetes perspective, every shard is a replica set represented by the StatefulSet resource. Mongos can be both Deployment or Statefulset – it acts as a query router and usually completely stateless. Config Servers store metadata about data whereabouts and cluster configuration. It is a special replica set which is also a StatefulSet usually.
With Operators, like Percona Operator for MongoDB, shards are automatically provisioned and configured.
Security
Encryption
Data is one of the most valuable assets of a business. Protecting it at all costs is a huge responsibility. Percona Server for MongoDB provides both data-at-rest encryption capabilities and transport encryption. For Kubernetes, Operator exposes various parameters that allow you to control the behavior. Data-at-rest means that your data is encrypted, where Transport is all about the traffic between the user (or application) and MongoDB nodes.
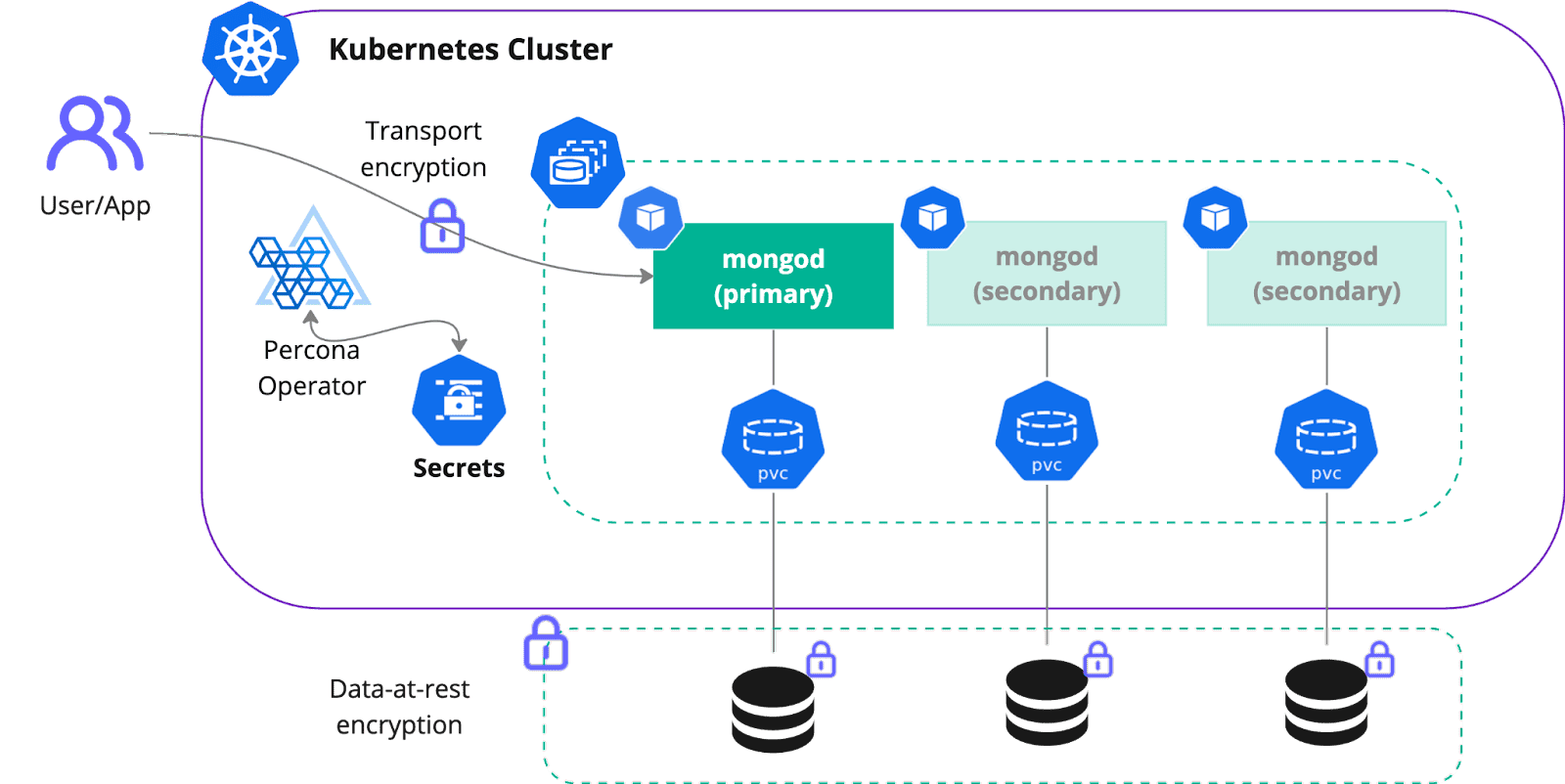
The key ingredient is a Secret resource. It contains Certificate Authority (CA), certificate itself and a private key to encrypt the data. Operator generates self-signed certificates automatically enabling encryption by default, but it is strongly recommended to have certificates signed by your CA. Especially when it comes to custom domains.
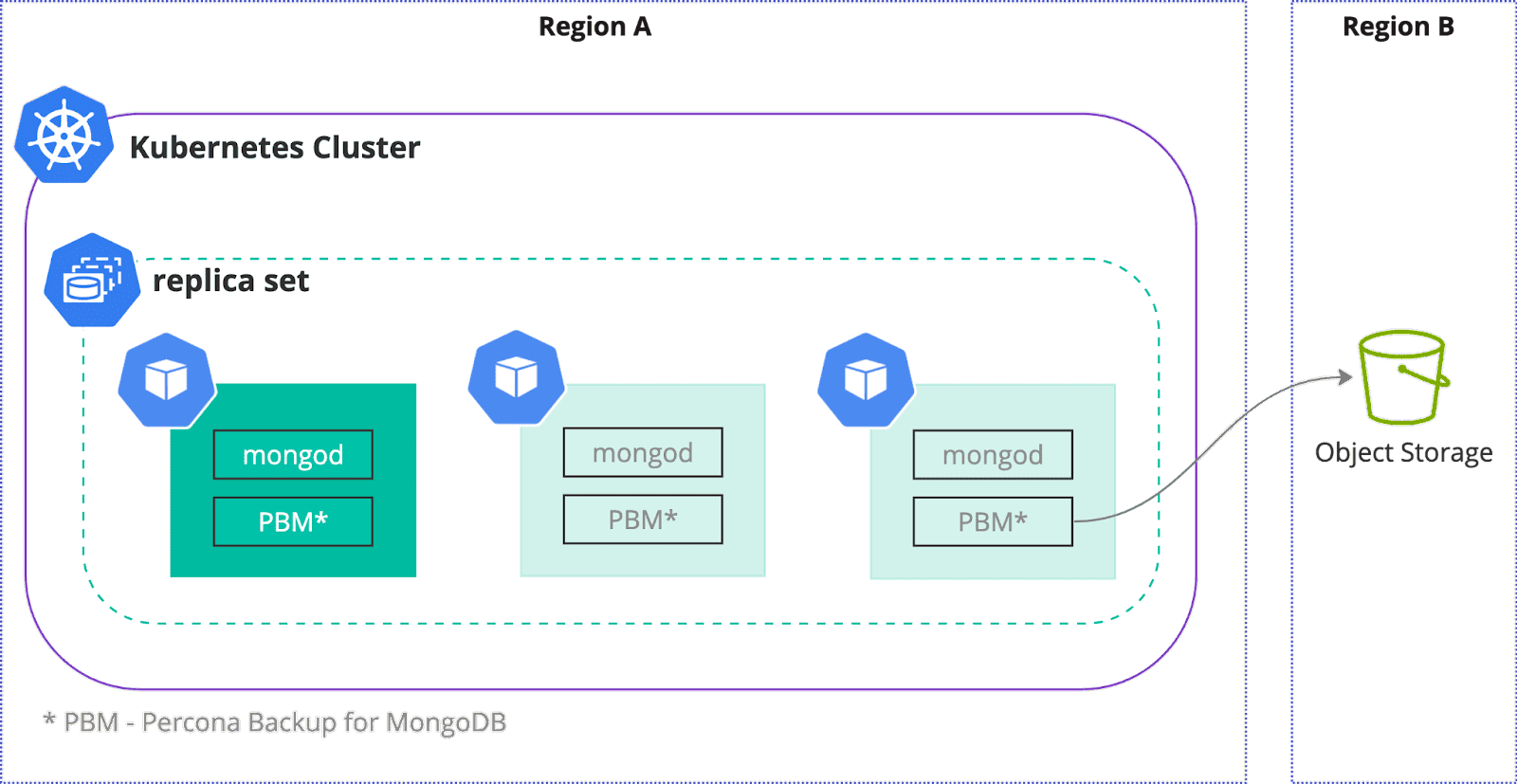
Backups
Another good way to keep the data safe is to have a strong backup strategy. Backups should be taken regularly and the restoration process should be well tested. In the Cloud Native world storing backups on an object storage (S3, Azure Blob, GCS, etc) is a de-facto standard. There are multiple factors to consider when creating a backup strategy:
Recovery Point Objective (RPO)
How recent should the data be in the backup. To lower RPO significantly, make sure that you have oplogs uploaded continuously to the object storage. This will allow you to use Point-in-Time recovery, to restore to the most recent date. Percona Operator backups are powered by Percona Backup for MongoDB, it allows you to fine tune oplogs uploads.
Recovery Time Objective (RTO)
How fast can you restore from the backup? Restoring a terabyte dataset might take time. One of the options is to leverage physical backup capability. Compared to logical backups recovery takes 5x less time. Operator has it all automated and figured out.
Backup safety∑
It is strongly recommended to store backups in different availability zones, datacenter or in a distinct region. Regional outages happen in public clouds more often than we think. It might be more expensive due to network egress costs, but keeping data safe is more important.
Conclusion
The landscape of database management is evolving, and Kubernetes is at the forefront of this transformation, offering a dynamic and scalable environment for stateful applications like MongoDB. Percona’s commitment to open-source and no-vendor lock-in perfectly complements Kubernetes’ flexibility, making the Percona Operator for MongoDB an ideal solution for deploying production-grade MongoDB on Kubernetes. By embracing the best practices outlined—focusing on availability, performance, and security—you can leverage the full potential of MongoDB in a Kubernetes ecosystem. The Percona Operator simplifies complex operations, automates deployment, and ensures that your MongoDB clusters are highly available, performant, and secure. Whether you’re scaling your operations, managing cross-cluster deployments, or ensuring your data’s integrity through encryption and backups, the Percona Operator for MongoDB is designed to meet the challenges head-on.
My journey from skepticism about stateful applications on Kubernetes to witnessing the hockey-stick adoption growth of databases like MongoDB on The platform underscores the viability and strategic advantage of this approach.
We encourage you to take the next step in your Kubernetes journey by trying out the 100% open source Percona Operator for MongoDB. Explore how it can transform your MongoDB deployment into a more manageable, scalable, and secure operation.