

Member post originally published on the Buoyant blog by William Morgan
Topology Aware Routing is a feature of Kubernetes that prevents cluster traffic within one availability zone from crossing to another availability zone. For high-traffic applications deployed in multi-zone clusters, this can provide significant cost savings: cloud providers can charge for traffic that crosses zone boundaries, and these costs can be expensive at scale.
However, Topology Aware Routing is designed to always prohibit cross-zone traffic, regardless of overall system health or performance. This means that any failure, latency, or other problem localized to one zone can never be compensated for by sending traffic to other zones—defeating much of the purpose of having a multi-zone cluster in the first place!
In this blog post, we take a deep look at Topology Aware Routing and show an example of the type of catastrophic failure it can be susceptible to.
A high availability primer
First, let’s take a step back and see why Topology Aware Routing exists in the first place.
To do this, we need to understand how to build highly available systems. Much like security, reliability is an exercise in defense in depth: there are many ways for systems to become unavailable, and there is no single silver bullet that fixes all of them. Also like security, reliability is an exercise in diminishing returns. Each subsequent “nine” of reliability is dramatically more expensive. (The Google SRE book is an excellent starting point for a modern approach to reliability, especially around quantification of risk.)
One critical tool for reliability is the failure domain: which components can fail, and when they do, can we contain how far that failure “spreads”?
Keep reading
- The latest trends in workload reliability
- A look at OS fuzzing projects for security and reliability
- Understand dynamic request routing and circuit breaking
- Register for KubeCon + CloudNativeCon North America 2024 today
Systems that are built in the cloud have, at the macro level, three basic tiers of failure domains available. The cloud provider itself is the first tier. Almost every provider also provides two further levels of locality: the region, which typically corresponds to a geographical location in which they run a datacenter (e.g. “Eastern US” or “Oregon” or “Melbourne”), and the availability zone (AZ), which might be a particular datacenter, building, rack, or something else within that region.
Providers, regions, and zones are all—at least theoretically—independent failure domains. If one provider goes down, the others should remain unaffected. If one region goes down, the other regions should be unaffected. And finally, if one zone goes down, the other zones should continue functioning.
Of course, the exact degree of independence is never perfect! Failure in a critical Internet network backbone could affect multiple regions across multiple providers at the same time. Failure in the networking within a datacenter could affect multiple AZs at once. But at least to a first approximation, zones, regions, and providers can be treated as independent failure domains.
Of these three tiers, zones are a little unique. They provide weaker guarantees of independence than regions do, but they also introduce less latency: communicating between zones is supposed to be fast.
Because of this, zones get special treatment in Kubernetes: while spanning providers or regions is not really supported, Kubernetes explicitly supports multi-zone clusters. A Kubernetes cluster can, for example, have nodes across three zones, and if one or even two zones fail, the cluster as a whole should keep functioning. Because of these reliability advantages, multi-zone clusters are explicitly recommended by providers such as AWS as a best practice.
The problem with multi-zone clusters is that when your cloud bill arrives, and you find out that your cloud provider charges for traffic crossing zones! If your system is relatively low traffic, this may not be an issue. If your system is high traffic, this bill can be a big surprise.
How much does cross-AZ traffic cost in Kubernetes?
The answer depends on your cloud provider. In AWS, for example, cross-AZ traffic is actually billed at the same rate as cross-region traffic: $20 per terabyte. Google charges half that, at $10.24 per terabyte. Azure (which confusingly defines “zone” to be something different from Availability Zone) currently does not charge for cross-AZ traffic at all—though in the past, they’ve claimed they were going to.
Whether this cost is significant for you depends not just on your cloud provider, but also how much traffic is sent across regions. For example, if you have an EKS cluster in AWS sitting across 3 zones, then assuming your traffic is evenly distributed, on average two thirds of it will be cross zone boundaries. This means you’ll be paying, as a function of total traffic on the cluster:
- 1 KB/s average traffic: 40 cents per year
- 1 MB/s average: $401 per year
- 1 GB/s average: $410,000 per year
If you’re on GCP, you can cut those numbers in half. And if you’re on Azure, you can ignore them entirely… until Azure decides to start charging for it.
Note that this applies both to in-cluster traffic that crosses AZ boundaries as well as to off-cluster traffic—including cross-cluster traffic. In other words, if you have two Kubernetes clusters that are in the same region and are both multi-AZ, and they communicate with each other, that traffic is going to cross zone boundaries as well.
Why not simply cut the baby in half?
Topology Aware Routing (TAR) to the rescue. Formerly called Topology Aware Hints, TAR is a Kubernetes feature designed to address exactly this cross-AZ cost. TAR eliminates cross-zone traffic within a Kubernetes cluster by simply preventing it at the network level: when TAR is active, kubeproxy will filter the endpoints for a destination to be in the same zone as the client.
The diagram below illustrates normal Kubernetes load balancing when TAR is not enabled. Service A calls service B, all pods across all zones for service B are available to service A, and Kubernetes can load balance connections across all of them—including cross-zone connections, marked in red.
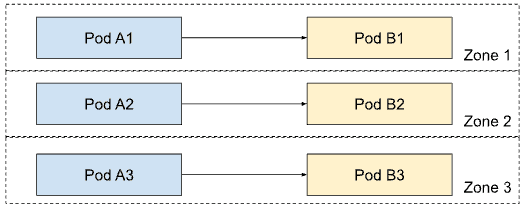
When TAR is enabled, we instead see the next diagram below. Pods in service A are only ever balanced to Pods for service B within the same zone. They won’t ever see pods for B that are located in other zones. All traffic stays within its zone.
And even if you’re using a service mesh with TAR, the same still holds. Linkerd, for example, replaces Kubernetes’s naive TCP connection load balancing with a highly sophisticated dynamic L7 request balancer which is capable of distributing individual HTTP and gRPC requests based on the latency of individual pods, transparently upgrading HTTP/1.1 to HTTP/2 connections, appling retries, timeouts, and circuit breaking, and much much more. Despite this, when TAR is enabled, Linkerd respects its rules. It will only establish connections to endpoints in the same zone as the client.
So: problem solved, right? Service mesh or not, cross-zone traffic is prevented, unnecessary costs are eliminated, and all is well. Or is it?
What happens when things go wrong?
TAR is great when everything is healthy. But if one zone experiences problems—pods fail, or become slow, or traffic becomes unevenly distributed—the zone is left to its own devices.TAR prevents pods in the failing zone from ever being able to reach pods in the other zones to compensate.
Here’s a Grafana dashboard from a simple three-AZ cluster we set up to demonstrate a particularly catastrophic example of this. In this simple application, we have a nine-pod orders service sending traffic to a nine-pod warehouse service. Each service is evenly distributed across three zones, i.e. with three pods in each zone.
TAR is enabled and all is well at first. Traffic stays within the same zone and the system is healthy. But if we disable the warehouse pods in just one zone (around the 11:32 mark), we see disaster: we drop to 0% success rate in that zone, as its orders pods are unable to reach any other pod—despite the fact that there are healthy pods elsewhere in the cluster!
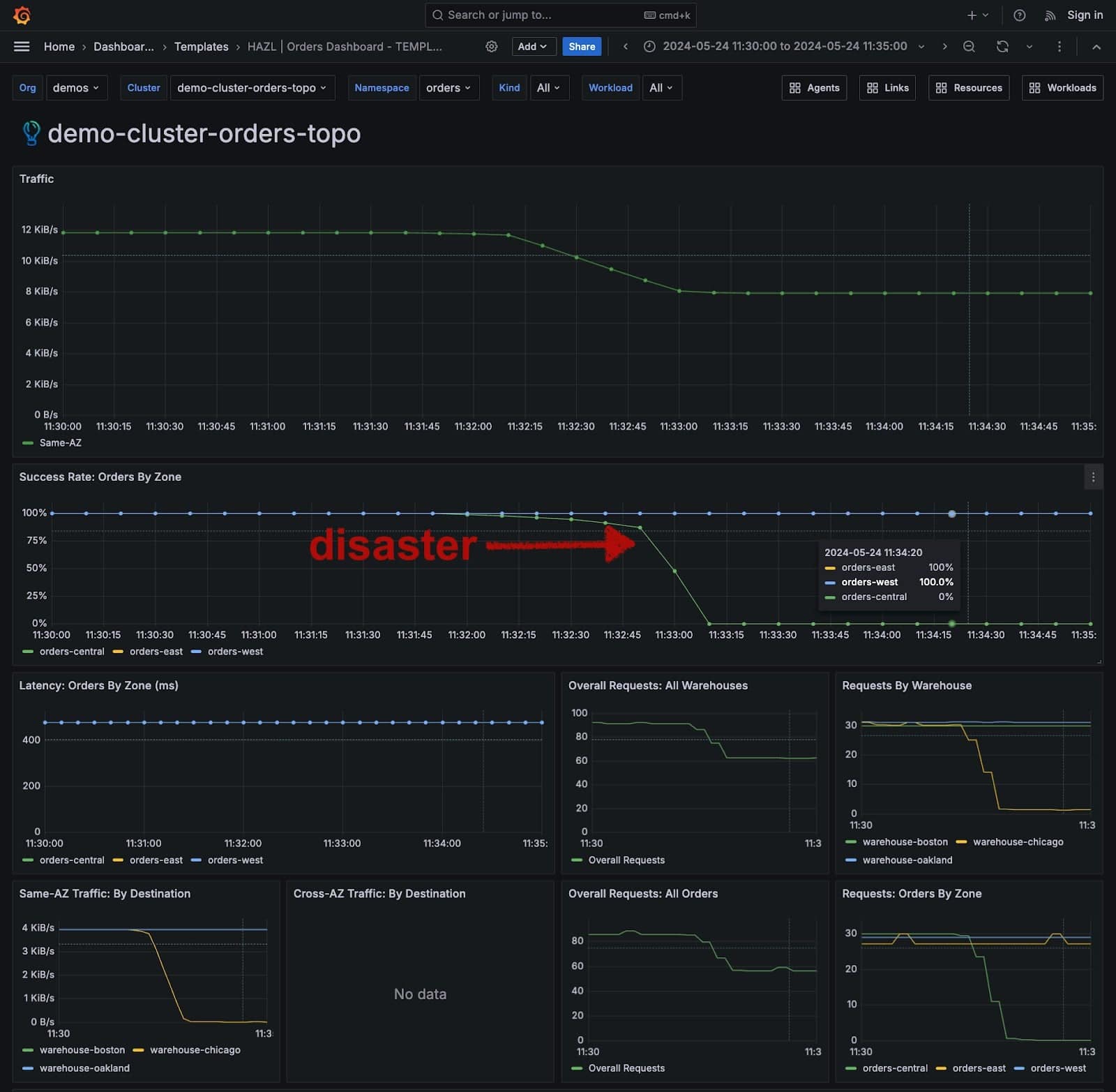
If Topology Aware Routing were not in effect, those pods would be able to balance requests across the other remaining pods in the cluster. In other words, by adding Topology Aware Routing to the system, we’ve introduced a whole new way for the system to fail!
(If you want to try this yourself, we have a repo here with all the relevant code. We’re using our bb application to generate the client and server, and the very cool oha load generator to generate the load.)
Topology Aware Routing has some other issues, as well. Remember when I said our “simple” demo setup had 9 pods? This is because TAR will not enable itself consistently with fewer than 3 pods in any zone. (The exact description from the docs is mildly alarming: “If there are fewer than 3 endpoints per zone, there is a high (≈50%) probability that” TAR will be disabled. So it might enable itself. Or it might not.)
The docs also provide a laundry list of conditions under which TAR will not work, i.e. will disable itself in an otherwise functioning system. Finally, TAR also plays poorly with features such as horizontal pod autoscaling.
Abandon all hope…?
What we we demonstrated above was an extreme example of TAR leading to a catastrophic failure: we killed the pods in one zone for one specific service, all at once. This kind of total failure is hopefully rare in practice—though not impossible, especially in the world of stateful services such as databases). And to be fair to TAR, there are ways it would have survived even this scenario: If we had deleted the pods (or if they had failed health checks and Kubernetes removed them from the set of available endpoints) TAR actually would have disabled itself once the minimum number of pods in a zone fell below 3 and cross-zone traffic would have been allowed.
But TAR’s inability to ever allow cross-zone traffic manifests in other types of failures as well. Any increase in the latency within a single zone, or the level of traffic within a single zone could trigger failure in a similar way. Denying all cross-zone traffic entirely is a very large hammer in a world of very small, nuanced, um, failure mode nails.
Happily, hope is not lost. In this blog post, we’ve really only explored two options:
- Without Topology Aware Routing: you get a highly reliable multi-AZ cluster, but you have to pay for cross-zone traffic.
- With Topology Aware Routing: you don’t have to pay for cross-zone traffic, but you cannot recover from all in-zone failures by relying on other pods (even though they’re in the same cluster.)
There is a third option, and in Part II of this blog post I’ll describe a way to get the best of both worlds—low cost and high availability. But in order to do that, we’re going to have to leave the world of simple L4 connection balancing behind, and move to the world of—you guessed it—L7 request balancing, where we can make explicit decisions about where to route traffic based on the health of the system.
Part II will be published next week. Stay tuned!
(Image credit: Photo by Dave Goudreau on Unsplash.)