
Member post by Sergey Pronin, Percona
Kubernetes launched in June 2014 – since then, it has played a huge part in popularizing cloud-native application designs and supporting more microservices deployments. The growth of container deployments is massive, and Kubernetes is essential for companies to manage those deployments – according to findings from the last CNCF report, 84 percent of organizations are either using or evaluating Kubernetes while 66% of potential and actual consumers were using Kubernetes in production.
Today Kubernetes is much more than a container orchestrator. It is a platform to build platforms. The unified API makes Kubernetes a great tool to run workloads across multiple clouds and in hybrid environments (where both on-premise and public clouds are in play), enabling businesses to avoid vendor lock-in. This in turn provides flexibility in architecture decisions and significantly reduces the infrastructure costs (cloud bill specifically).
Such an adoption growth year over year creates an image of inevitability of Kubernetes in every organization in quite a short time.
The question is – what is next for Kubernetes? Are all problems solved?
Databases complexity
In the database sector, various community groups began to engage with Kubernetes to evaluate how it could work with their projects, and conversely how they could implement projects to run on Kubernetes as well. The key questions that these communities wanted to answer were around the challenges that existed in running databases on Kubernetes, as well as sharing best practices for initial deployments and performance optimization steps that could be used.
The start was bumpy. With the first releases of StatefulSets and Persistent Volumes engineers were able to run stateful workloads in Kubernetes. But starting a database and keeping it alive and well are two different challenges. The complexity of running the database in k8s was not well understood (see image below of some of the k8s primitives required to run for a single Percona XtraDB Cluster). That led to wrong assumptions that Kubernetes is for stateless workloads only.
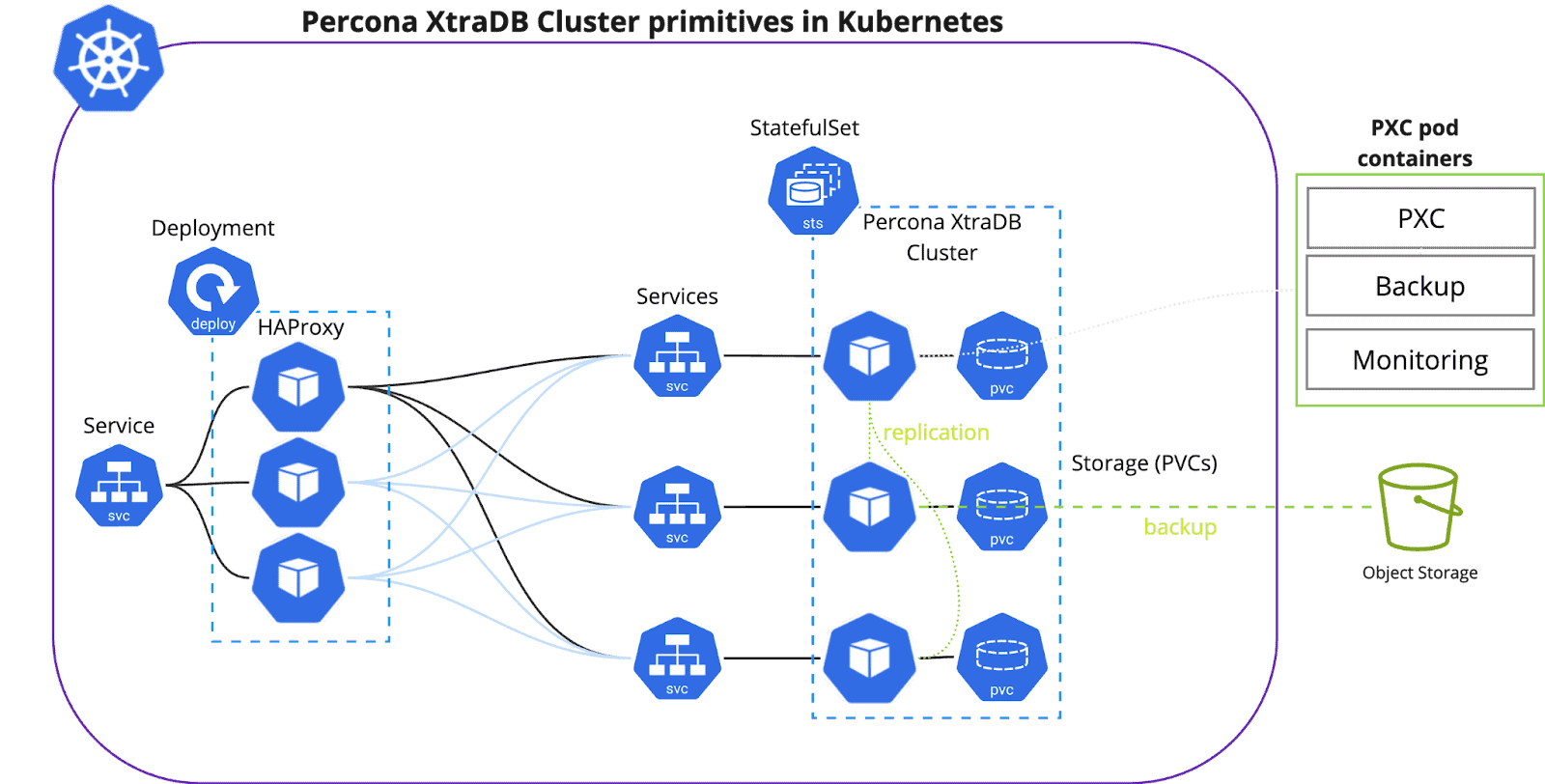
But gladly engineers’ curiosity did not stop. Container Storage Interfaces matured, providing administrators with much better control over storage. And with the launch of Kubernetes Operators, developers were able to greatly simplify the deployment and management of complex applications (such as databases).
By making it easier to run databases like PostgreSQL, MySQL and MongoDB in containers as cloud-native data deployments, more developers were able to adopt cloud-native application approaches in general. That migration drove more value and more opportunities for companies – according to the Data on Kubernetes community, 83 percent of companies surveyed attributed more than 10 percent of their revenue to running their data on Kubernetes, and one third of organizations saw their productivity increase twofold. These companies are now running more complex workloads on Kubernetes, including analytics (67 percent) and AI/ML (50 percent).
Keep reading
- Looking to the past and future of Kubernetes
- Build a managed database service with K8s operators
- Streamline monitoring in Kubernetes
- Register for KubeCon + CloudNativeCon North American 2024 today
Operators issues
Operators for sure simplified database deployment, but more importantly what they did for day-2 operations – removed the need to execute routine tasks and minimized the possibility of human error.
But not all problems are solved.
Complexity
Operators abstract Kubernetes primitives and removes the need to configure databases. But this does not remove complexity completely, still requiring engineers to connect to Kubernetes and interact with kubectl to troubleshoot issues or execute various operational tasks.
Multi-cloud
As mentioned above, Kubernetes abstracts the infrastructure and provides a unified API. That way it becomes an ideal tool to build multi- and hybrid-cloud platforms. But at the same time the multi-cloud story is not complete. There were attempts to solve multi-cluster deployments through Federation (famous retired KubeFed), and ongoing projects like Elotl Nova or Karmada.
The lack of a unified solution forces engineers to create their own ways to deliver multi-cluster capabilities. For instance, all Percona Operators allow users to set up cross-cluster replication for databases, but failure detection and failover are manual.
Multi-database
According to Redgate, 79% of the companies use two or more database technologies in their stack. Mapping it to Kubernetes, it would require to run an operator per database tech. Each Operator comes with its own configuration patterns and learning curve. This again increases complexity and operational burden.
The Future: Seeing Beyond Operators
Going forward we expect to see another level of abstraction, that would help users to battle the complexity of the issues listed above. We suspect that more open source solutions will be coming in the form of web applications or new APIs. This is the power of open source software – building solutions like Kubernetes and then making it better.
Percona is one example of a company that is trying to address the complexity, multi-cloud, and multi-database problems head on. We recently released Percona Everest, an open source cloud native database platform that provides users with a click-and-run experience for running and managing databases on Kubernetes. What makes Percona Everest unique and a tool worth trying is that in one platform we are solving the issues stated above.
Percona Everest simplifies the inherent complexity of Kubernetes and Operators themselves by providing a user-friendly graphical interface and a robust API. This directly addresses the challenges of troubleshooting and Kubernetes management. We eliminate the complexity of Multi-cloud database deployments by streamlining the orchestration of multiple Operators across different Kubernetes clusters. This transforms multi-regional and cross-site replication from a YAML puzzle into a simple click-and-configure experience. (This feature is yet to come.)
Here is some initial data – cool graphs below.
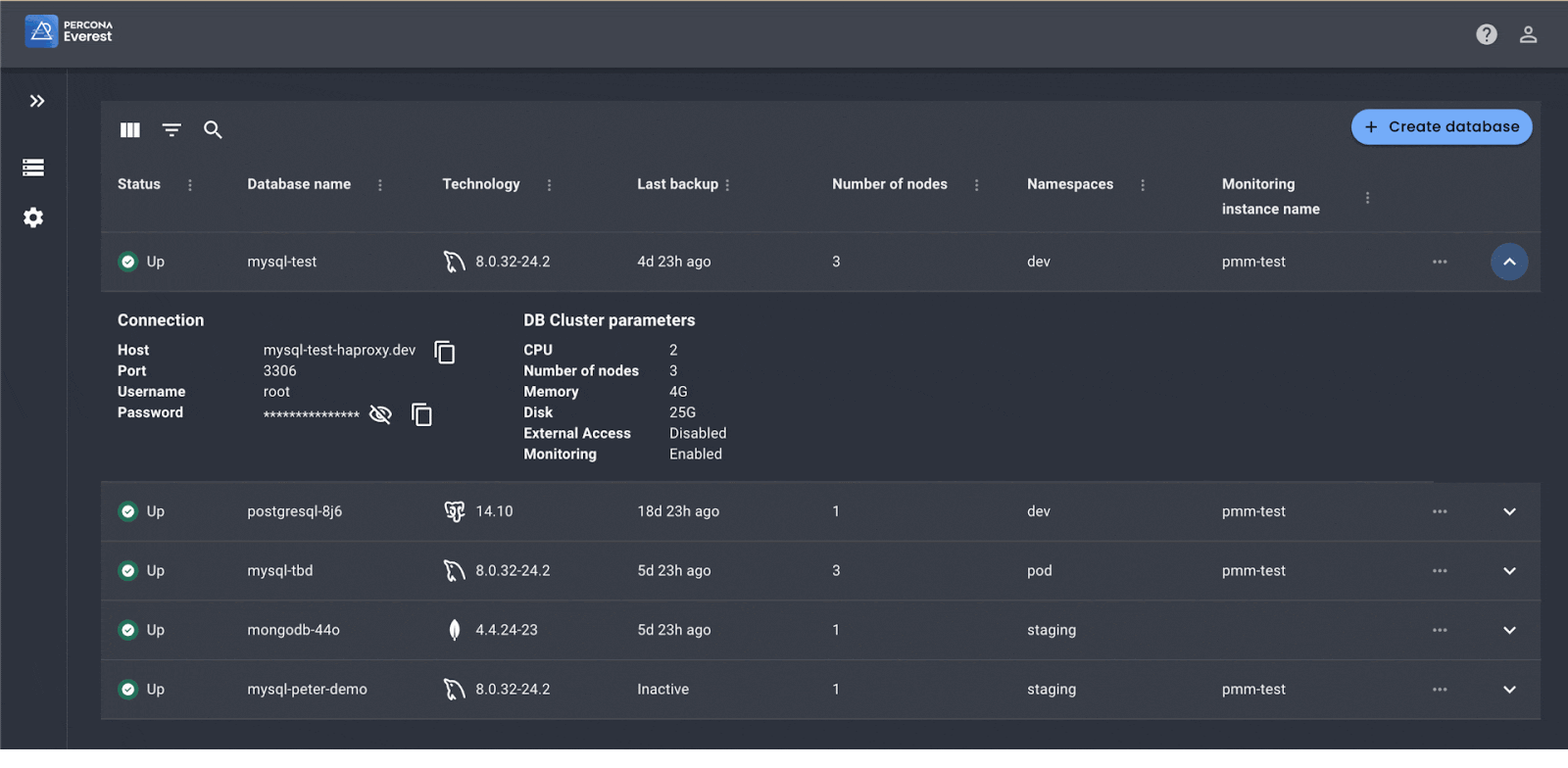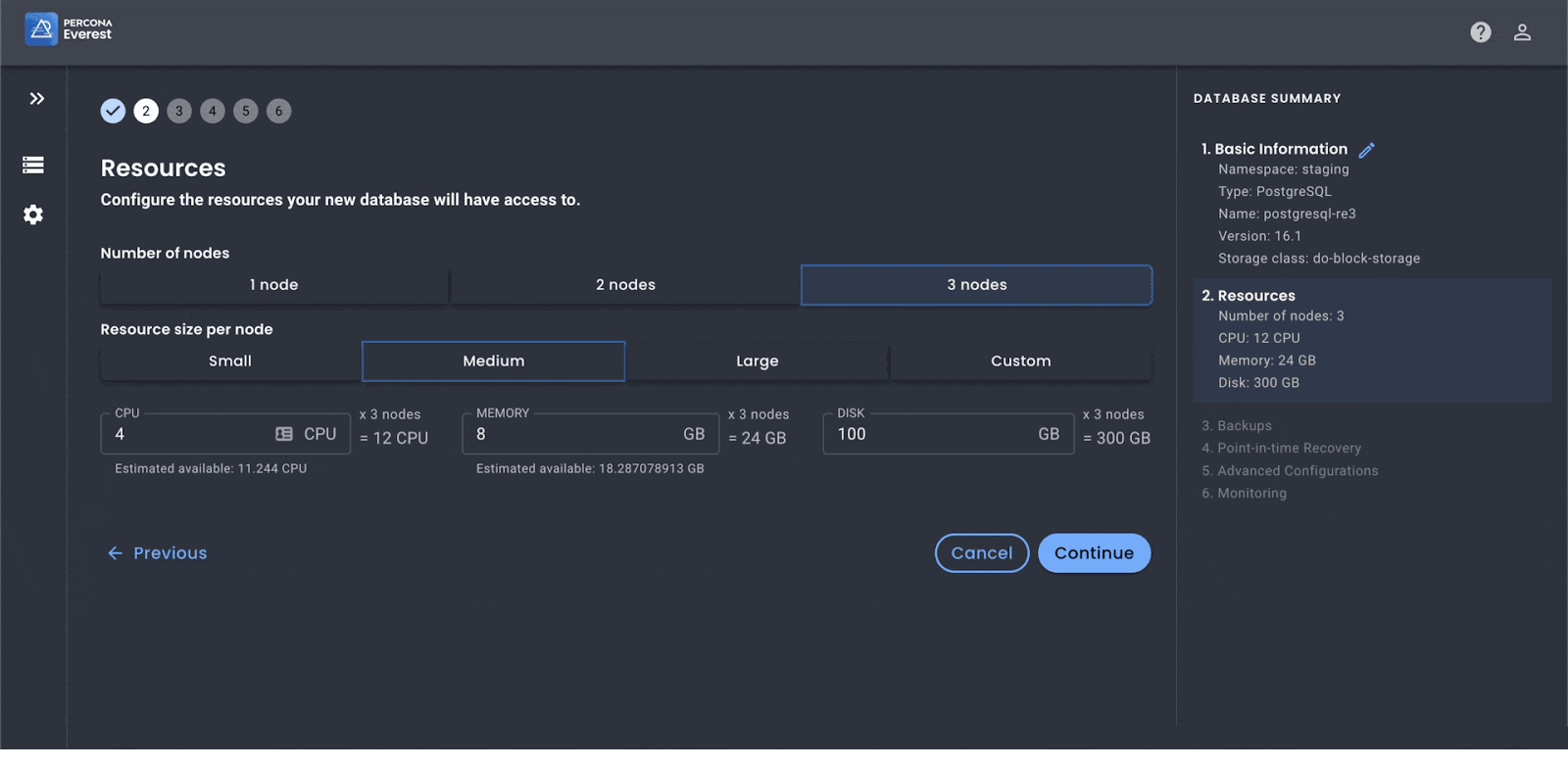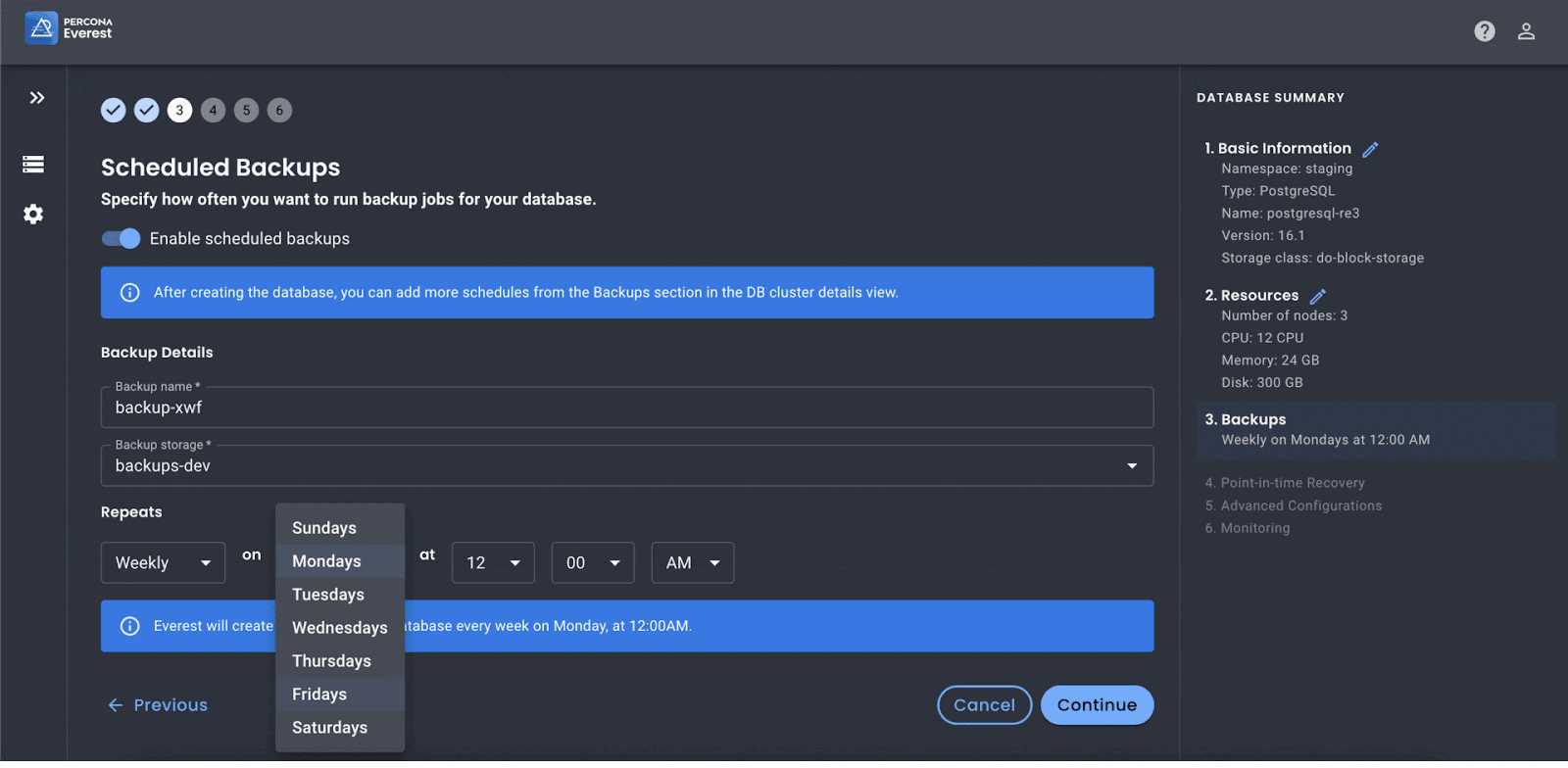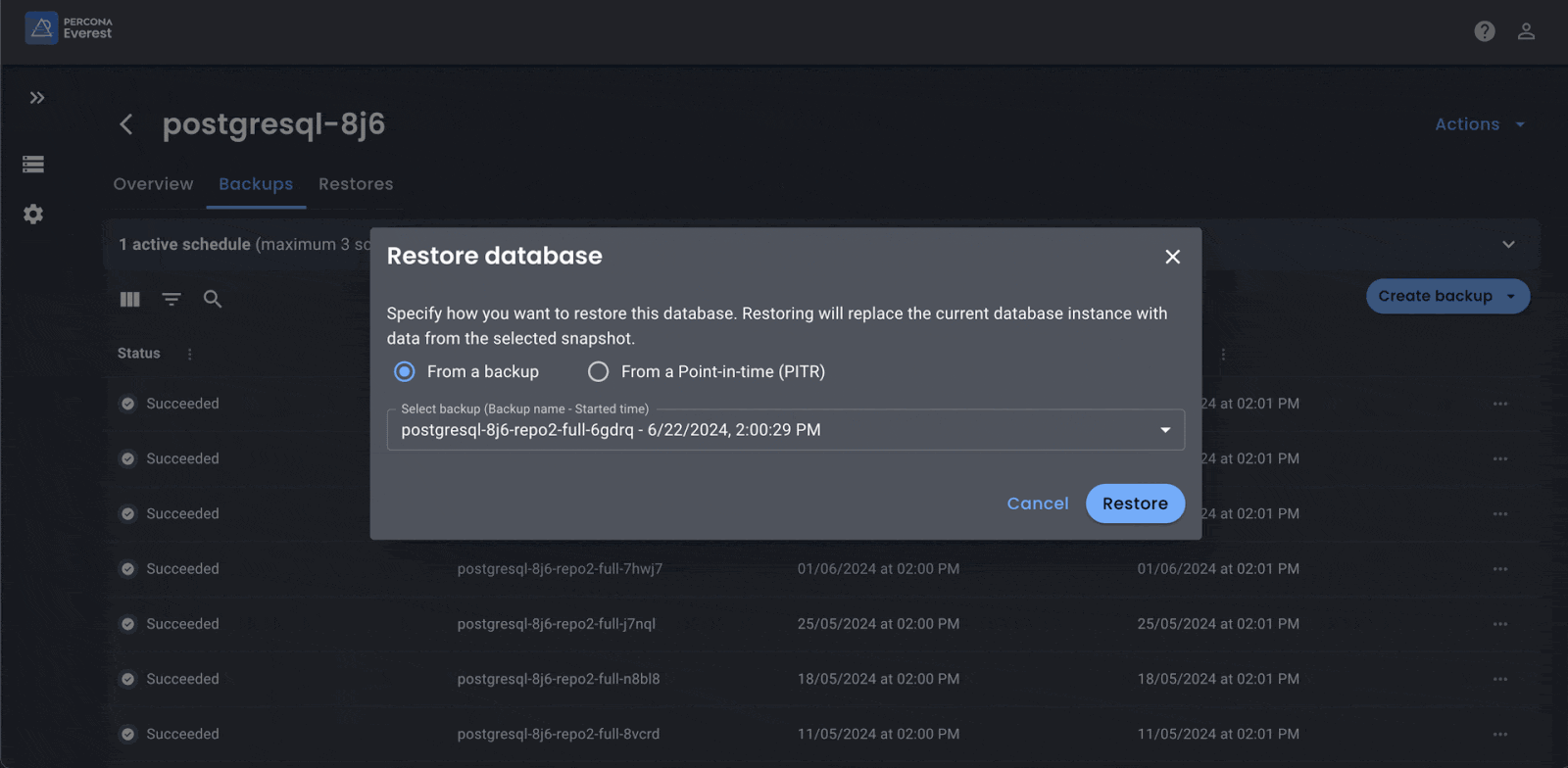
In summary, as we see more and more companies adopting Kubernetes we will continue to discover ways in which we can enhance the way we work saving developer time and corporate dollars. Percona Everest is one example and we look forward to streamlining and strengthening its capabilities as we get to GA. Cheers to 10 years of Kubernetes and the next 10 of continued innovation in the cloud!
Open source thrives when a passionate community comes together. Your voice is crucial! Experience the power of Percona Everest firsthand with our quick start guide. Share your feedback in our forum, connect with fellow engineers, and help shape the future of cloud-native database management by contributing to our GitHub repository. Let’s build Percona Everest together.