








End user post by Dan Williams, Senior Infrastructure Engineer at loveholidays
In this blog post, we’ll share how loveholidays was able to utilise Linkerd to provide uniform metrics across all services, leading to a decrease in incident Mean Time To Discovery (MTTD) and an increased customer conversion rate by reducing search response times.
Introducing loveholidays
Founded in 2012, loveholidays is the largest and fastest growing online travel agency in the UK and Ireland. Having launched in the German market in May 2023, we’re on a mission to open the world to everyone. Our goal is to offer our customers unlimited choice with unmatched ease and unmissable value, providing the perfect holiday experience. To achieve that, we process trillions(!) of hotel/flight combinations per day, with millions of passengers travelling with us annually.
Meet the engineering team
loveholidays has around 350 employees across London (UK) and Düsseldorf (Germany), with more than 100 of us in Tech and Product, and we are constantly growing. Our current engineering headcount sits at around 60 software engineers and 5 platform engineers.
Engineering at loveholidays is scaled based on 5 simple principles, embodying our “you build it, you run it” engineering culture. Our engineers are empowered to own the full software delivery lifecycle (SDLC), meaning each and every engineer in our company is responsible for their services at every step of the journey, from initial design through to deploying to production, building monitoring alerts/dashboards and being on-call for all day-2 operations.
The platform infrastructure team at loveholidays works to enable developers to operate in a self-serve manner. We do this by identifying common problems and friction points, then solving them with infrastructure, process and tooling. We are huge advocates for open source tooling, meaning we are constantly pushing the boundaries and working on the cutting edge of technology.
Our infrastructure
We are a team of Google Cloud Platform evangelists. In 2018, we migrated from on-prem to GCP (see our Google case study here!), with 100% of our infrastructure now in the cloud. We run 5 GKE clusters spread across production, staging and development environments, with all services running in one primary region in London. We are actively working on introducing a multi-cluster, multi-region architecture. Learn more about our multi-cluster expansion in this blog post.
We run somewhere in the region of 5000 production pods with around 300 Deployments / StatefulSets, all managed by our development teams. The languages, frameworks, and tooling used are all governed by the teams themselves, so we have services in Java, Go, Python, Rust, JavaScript, TypeScript, and more. One of our engineering principles is “Technology is a means to an end”, meaning teams are empowered to pick the correct language for the task rather than having to conform to existing standards.
We use Grafana’s LGTM Stack (Loki, Grafana, Tempo, Mimir) for all of our observability needs, along with other open-source tools such as the Prometheus-Operator to scrape our application’s metrics, ArgoCD for GitOps along with Argo Rollouts and Kayenta powering our canary deployments.
With GitOps powered deployments, we deploy to production over 1500 times a month. We move fast and we occasionally break stuff.
Time is money; latency is cost
Search response time has a direct correlation with customer conversion rate — the likelihood for a customer to complete their purchase on our website. In other words, it’s absolutely vital for us to monitor the latency and uptime of our services to spot regressions or poorly behaving components. Latency also correlates with infrastructure cost as faster services are cheaper to run.
Since teams are in charge of creating their own monitoring dashboards and alerts, historically, each team reinvented the wheel for monitoring their applications. This resulted in inconsistent visualisations, incorrect queries/calculations, or completely missing data. A simple example of this is one application reporting throughput in requests per minute, another with requests per second. Some applications would record latency in averages, some with percentiles such as P50/P95/P99, but not even consistently the same set of percentiles.
These small details made it nearly impossible to quickly compare the performance of any given service, where the observer would have to learn the dashboards for each application before beginning to evaluate its health. We couldn’t quickly identify when one application was performing particularly badly, meaning our MTTD for regressions introduced with new deployments would have a direct impact on our sales / conversion rate.
Linkerd: the answer to our disparate metrics and observability problem
Each language and framework we use brings with it a new set of metrics and observability challenges. Just creating common dashboards wouldn’t be an option, as no two applications present the same set of metrics, and this is where we decided that a service mesh could help us. Using a service mesh, we would immediately have a uniform set of Golden Signals (latency, throughput, errors) for HTTP traffic, regardless of the underlying languages or tooling.
As well as uniform monitoring, we knew a service mesh would help us with a number of other items on our roadmap, such as mTLS authentication, automated retries, canary deploys, and even east-west multi-cluster traffic.
The next question was which service mesh? Like most companies, we decided to evaluate Linkerd and Istio, the only two CNCF-graduated service meshes. Our team had brief previous exposure to both Istio and Linkerd, having tried and failed to implement both meshes in the very early days of our GKE migration. We knew Linkerd had been completely rewritten with 2.0, so we decided to pursue this first as our Proof of Concept (PoC).
One of our core principles is “Invest in simplicity”, and this is embodied throughout Linkerd’s entire philosophy and product. For our initial PoC, we installed Linkerd to our dev cluster using their CLI, we added the Viz plugin (which provides real-time traffic insights in a nice dashboard), and finally added the `linkerd/inject: enabled` annotation to a few deployments. That was it. It just worked. We had standardised golden metrics being generated by the sidecar Linkerd proxies, mTLS securing pod-to-pod traffic and we could listen to live traffic using the tap feature, all within about 15 minutes of deciding to install Linkerd in dev.
Linkerd as a product aligned exactly with how we approach engineering, by investing in simplicity. We had a clear goal in mind of the problem we wanted to solve, without additional complexity or overhead, and our findings during the PoC stage made it immediately clear that Linkerd was the correct solution to the problems we set out to solve, and the entire open source community around Linkerd deserves a mention as everyone involved is incredibly open and willing to help.
The implementation
To roll out Linkerd into production, we took a very slow and calculated approach. It took us over six months to get to full coverage, as we onboarded a small number of applications at a time and then carefully monitored these in production for any regressions. Our implementation journey is detailed in a three part series on our tech blog: “Linkerd at loveholidays — Our journey to a production service mesh” blog post.
This slow approach may seem counterintuitive given we went with Linkerd for both ease and speed of deployment. The reality is that edge cases exist, and things will always break in ways you don’t expect as no two production environments are the same.
Throughout our onboarding journey, we identified and fixed a number of issues with edge case issues such as connection leaking and memory leaks, requests being dropped due to malformed headers and a number of other network related issues that were previously hidden before the Linkerd proxy exposed them.
I like the following excerpt from the Debugging 502s page in Linkerd’s documentation: “Linkerd turns connection errors into HTTP 502 responses. This can make issues which were previously undetected suddenly visible.”
Our efforts combined with the Linkerd maintainer’s receptiveness and willingness to help, led to code fixes both in ours and Linkerd’s code to address some of the issues we found. As we progressed through our onboarding journey and identified different failure modes, we added new Prometheus and Loki (logs) alerts to quickly alert us to issues related to the service mesh before they become problems.
Since finishing our onboarding in early 2023, `linkerd/inject: enabled`has become the default setting for all new applications deployed via our common Helm Chart and isn’t even something we think about anymore.
We built a common dashboard based on Linkerd metrics, automatically showing for all meshed applications:
- “Golden Signals” HTTP metrics (throughput, latency, errors, success rate)
- Service to service traffic:
- Inbound traffic & success rate per service
- Outbound traffic & success rate per service
- TCP connections
- Per-Route HTTP metrics (driven by ServiceProfiles)
- Resource information (pods, CPU, memory etc via kube-state-metrics)
- Linkerd-Proxy logs
…and more. All new services are automatically meshed, meaning we provide near-full observability for all services from the moment they are deployed.
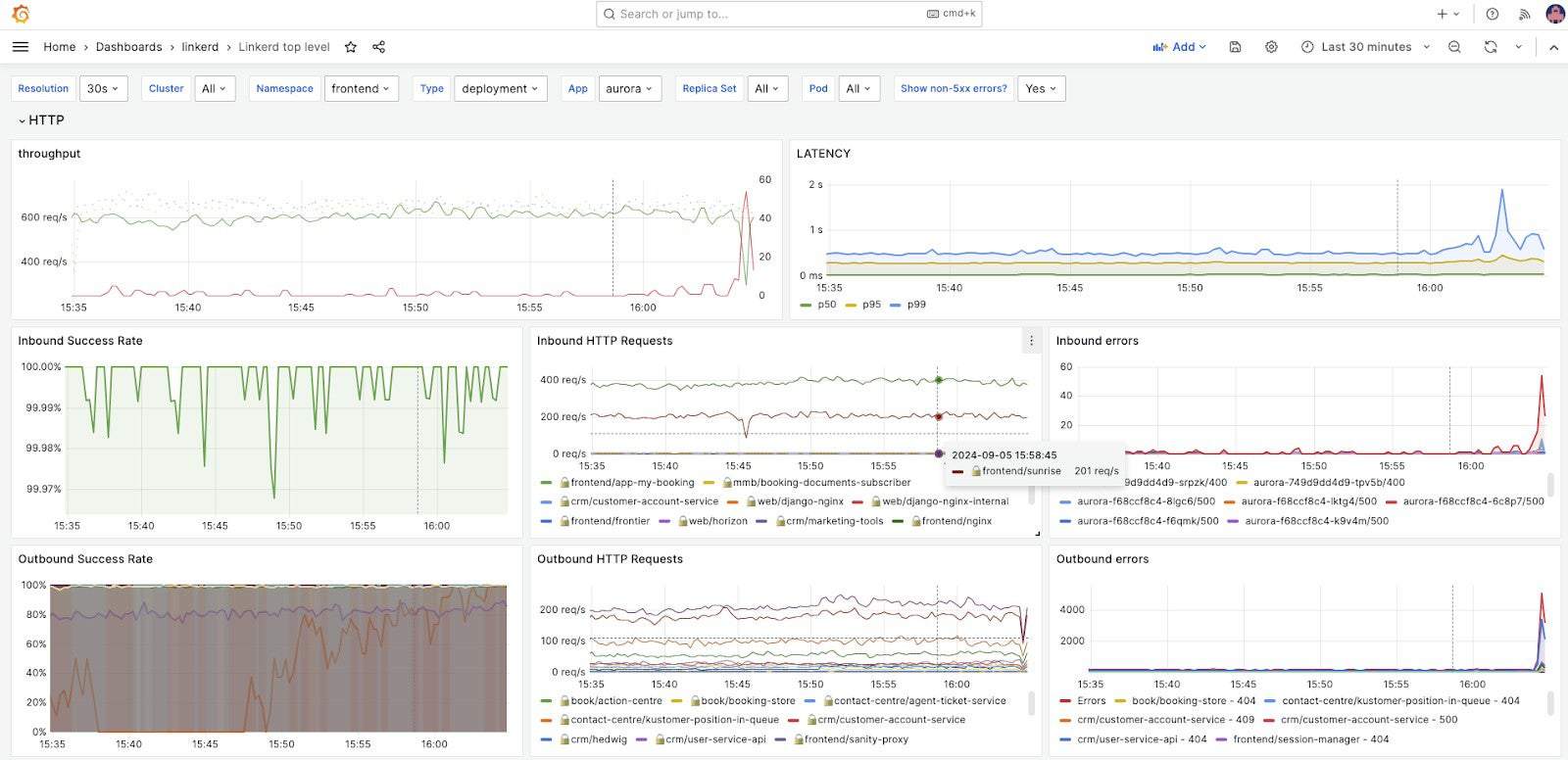
For each service, we can see the traffic from and to different services, so we can quickly identify if, for example, a particular downstream service is responding slow or erroring. Previous dashboards might tell us requests were failing, but not be able to easily identify the source or destination service for those failing requests.
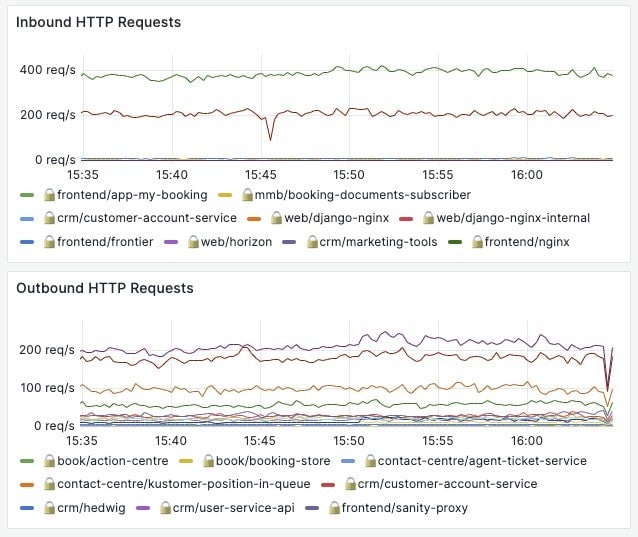
With Linkerd’s throughput metrics, combined with some pod labels from Kube State Metrics, we have been able to produce dashboards identifying cross-zone traffic inside the Cluster, which we’ve then used to optimise our traffic and save significant amounts on our networking spend. We plan to use Linkerd’s HAZL to further reduce our cross-zone traffic.
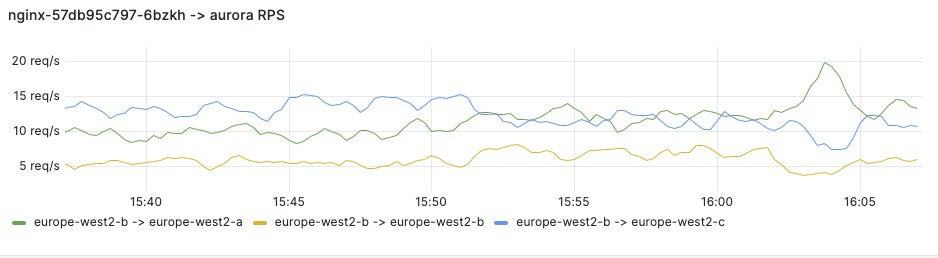
Using a combination of Argo Rollouts and Kayenta, we use the metrics provided by Linkerd to perform Canary deployments with automated rollbacks in case of failure. A new deployment will create 10% of pods using the new image, then we use the Linkerd metrics captured from the new and old pods to perform statistical analysis and identify issues before the new version is promoted to stable. This means if, for example, an application’s P95 response time increases by a certain % compared to the previous stable version, we can consider it a failed deployment and rollback automatically.
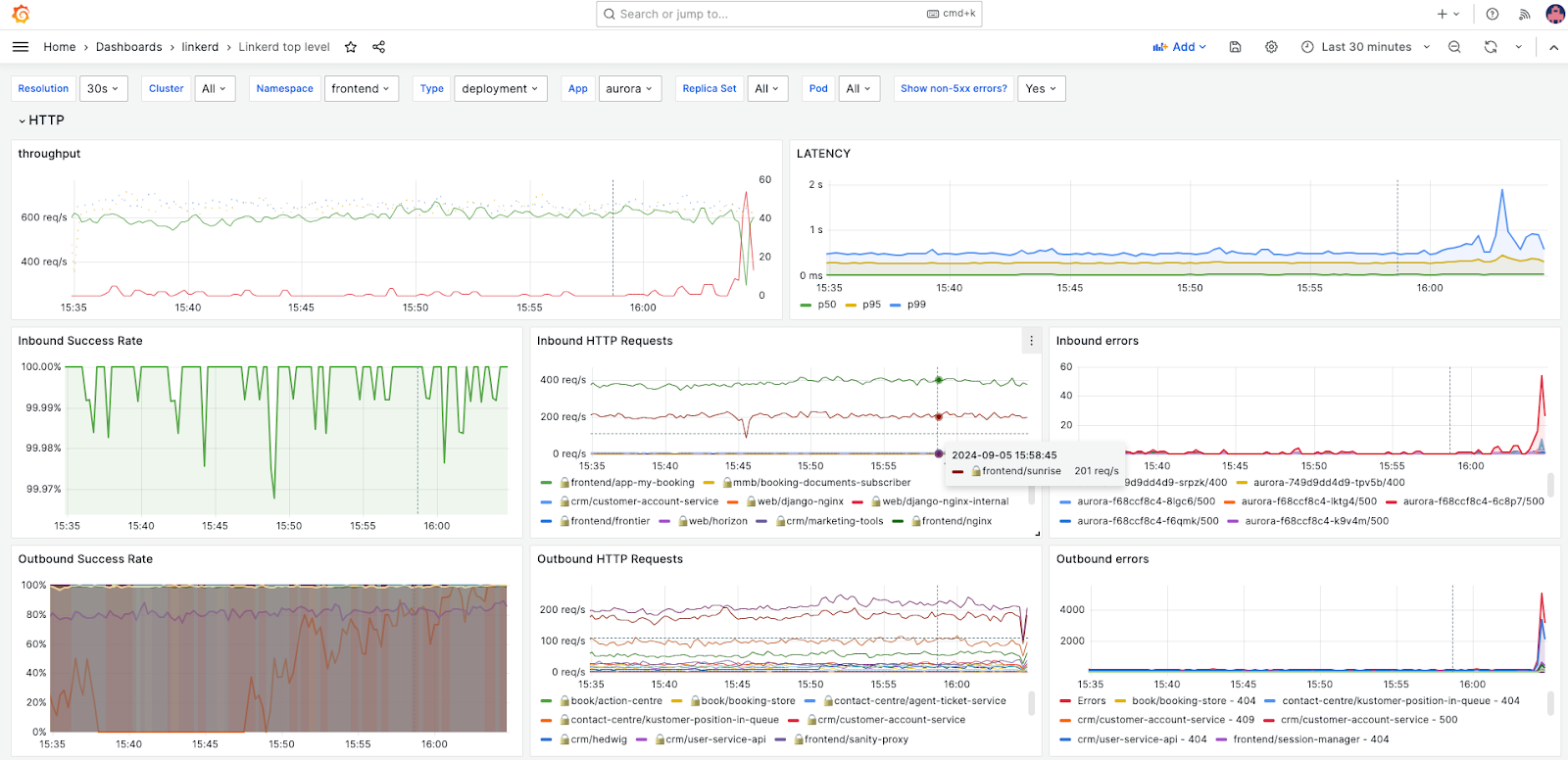
We have caught hundreds of failed deployments with this approach, significantly reducing our MTTD and incident response time. Oftentimes, issues that would have become full-scale production outages, are caught and rolled back long before they would have been caught by an engineer. This type of metrics based analysis is only possible when you collect data from your applications in a consistent way.
We’ve also built automated latency and success SLIs and SLOs based on Linkerd metrics, using a combination of open source tools: Pyrra and Sloth.
The final use case we’ll share is that we export all of the Linkerd metrics to BigQuery, and have an Application Performance Monitoring dashboard which shows us Latency and RPS for all applications since the start of us collecting Linkerd metrics. This is very useful for identifying regressions (or improvements as shown below!) over time:
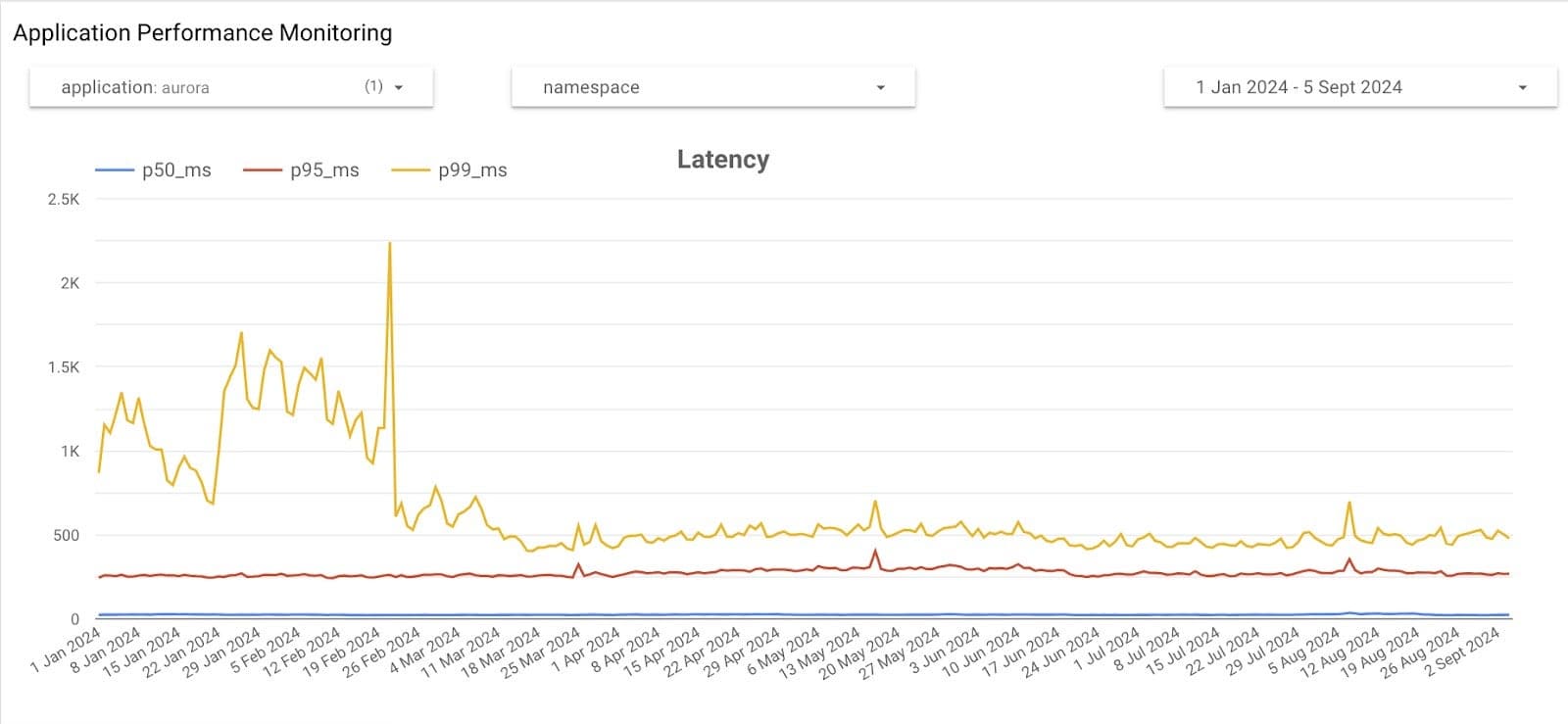
Of course, Linkerd offers so much more than just metrics, and we have been able to utilise these features in other areas but we are barely scratching the surface of what is possible. We’ve utilised Service Profiles to define Retries and Timeouts at the Service level, meaning this becomes a uniform configuration to make an endpoint automatically retryable, allowing us to shift this logic out of application code.
With the new advances in HTTPRoutes from Linkerd, we are excited to get into seeing how we can utilise new features such as Traffic Splitting and Fault Injection to further enhance our use of the service mesh.
You can read more about our experience using Linkerd for monitoring at Linkerd at loveholidays — Monitoring our apps using Linkerd metrics.
Achieving metrics nirvana.. and increasing the conversion rate by 2.61%
A great user journey is at the heart of everything we do, with a fast search being crucial to the holiday browsing experience for our customers. And as mentioned above, search response time has a direct correlation with customer conversion rate. A refactor of our internal content repository tooling with a decreased P95 search time resulted in a 2.61% increase in conversion, based on a 50% traffic split A/B test. Based on the numbers published in the atol report, with loveholidays flying nearly 3 million passengers in 2023, this means an additional ~75,000 passengers travelled with us as a result of a faster search, all monitored and powered with the metrics produced by the Linkerd proxy.
We love holidays and CNCF projects!
At loveholidays, we are big open source fans, and as such, we use many CNCF projects. Here’s a quick overview of our current CNCF stack. At the core of it all is, of course, Kubernetes. All of our production applications are hosted in Google Kubernetes Engine, with Gateway API used for all ingress traffic.
We’ve recently migrated from Flux to ArgoCD, which we use as our GitOps controller with a combination of Kustomize and Helm to deploy our manifests. We have canary analysis and automated rollbacks using Argo Rollouts, Kayenta and Spinnaker all powered by Linkerd metrics. We’ve also developed an in-house “common” Helm chart, powering all of our applications. This ensures consistent labels and resources for all applications.
Some of our workloads use KEDA to scale pods based on GCP’s Pub/Sub and/or RabbitMQ. We have processes which dump thousands of messages at once into a Pub/Sub Queue, so we use KEDA to scale up hundreds of pods at a time to rapidly handle this load.
We use Conftest / OPA as part of both our Kubernetes and Terraform pipelines. This enables us to enforce best practices as a platform team (check out Enforcing best practice on self-serve infrastructure with Terraform, Atlantis and Policy As Code for more details).
We store our secrets in Hashicorp Vault, with Vault Secret Operator for Cluster integration.
Our monitoring system is fully open source. We built it with Grafana’s Mimir, Grafana, Prometheus, Loki, and Tempo. We use the prometheus-operator with kube-stack-prometheus. We also use OpenTelemetry and collect distributed tracing with otel-collector and Tempo, and Pyroscope for Application Performance Monitoring.
Known internally as Devportal, we use Backstage to keep track of our services as an internal service catalogue. We have tied Backstage “service” resources into our common Helm chart to ensure every deployment inside Kubernetes has a Backstage / Devportal reference, with quick links to the Github repository, logs, Grafana dashboards, Linkerd Viz, and so on.
Velero is used for our cluster backups, and Trivy is used to scan our container images. Kubeconform is used as part of our CI pipelines for K8s manifest validation.A combination of cert-manager and Google-managed certificates, both using Let’s Encrypt, power loveholidays’ certificates, and external-dns automates DNS record creation via Route53. We use cert-manager to generate the full certificate chain for Linkerd, which is the third part of our Linkerd blog series – Linkerd at loveholidays — Deploying Linkerd in a GitOps world.