Member post by Rajdeep Saha, Principal Solutions Architect, AWS and Praseeda Sathaye, Principal SA, Containers & OSS, AWS
Introduction
Karpenter is an open-source project that provides node lifecycle management to optimize the efficiency and cost of running workloads on Kubernetes clusters. AWS created and open sourced Karpenter in 2021 to help automate how customers select, provision, and scale infrastructure in their clusters and provide more flexibility for Kubernetes users to take full advantage of unique infrastructure offerings across different cloud providers. In 2023, the project graduated to beta, and AWS contributed the vendor-neutral core of the project to the Cloud Native Computing Foundation (CNCF) through the Kubernetes Autoscaling Special Interest Group (SIG). In 2024, AWS released Karpenter version 1.0.0 that marks the final milestone in the project’s maturity. With this release, all Karpenter APIs will remain available in future 1.0 minor versions and will not be modified in ways that results in breaking changes. Karpenter is available as open-source software (OSS) under an Apache 2.0 license. It separates the generic logic for Kubernetes application-awareness and workload binpacking from the creation and running of API requests to launch or terminate compute resources for a given cloud provider. By developing cloud provider-specific integrations that interact with their respective compute APIs, Karpenter enables individual cloud providers such as AWS, Azure, GCP, and others to leverage its capabilities within their respective environments. In 2023 Microsoft released Karpenter Provider for running Karpenter on Azure Kubernetes Service (AKS).
Today, Karpenter has gained widespread popularity within the Kubernetes community, with a diverse range of organizations and enterprises using its capabilities to help improve application availability, lower operational overhead, and increase cost-efficiency.
How Karpenter works
Karpenter’s job in a Kubernetes cluster is to make application and Kubernetes-aware compute capacity decisions. It is built as a Kubernetes Operator, runs in the Kubernetes cluster, and manages cluster compute infrastructure. There are two kinds of decisions Karpenter makes: to provision new compute and to deprovision that compute when it’s no longer needed. Karpenter works by watching for pods that the Kubernetes scheduler has marked as unschedulable, evaluating scheduling constraints (resource requests, node-selectors, affinities, tolerations, and topology spread constraints) requested by the pods, provisioning nodes that meet the requirements of the pods, and deprovisioning the nodes when the nodes are no longer needed. Karpenter’s workload consolidation feature proactively identifies and reschedules underused workloads onto a more cost-efficient set of instances, either by reusing existing instances within the cluster or by launching new, optimized instances, thereby maximizing resource usage and minimizing operational costs.
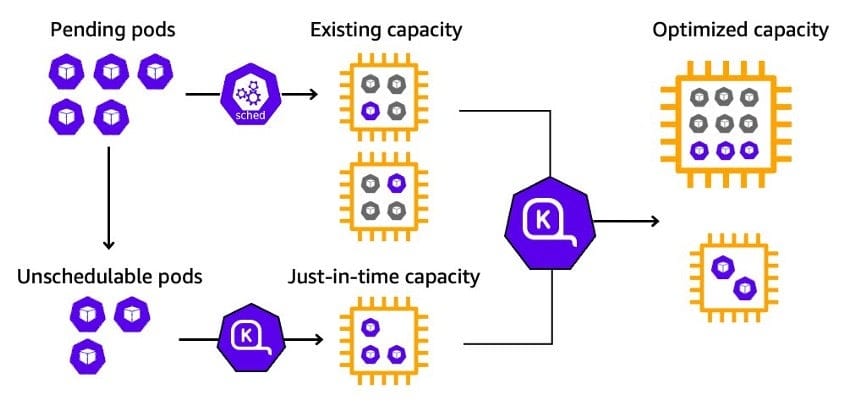
Karpenter scaling is controlled using Kubernetes native YAMLs, specifically through the use of NodePool and NodeClass custom Kubernetes resources.
NodePools set constraints on the nodes that Karpenter provisions in the Kubernetes cluster. Each NodePool defines requirements such as instance types, availability zones, architectures (for example AMD64 or ARM64), capacity types (spot or on-demand), and other node settings that apply to all the nodes launched in the NodePool. It also allows setting limits on total resources such as CPU, memory, and GPUs that the NodePool can consume. The following is an example of NodePool configuration.
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
requirements:
- key: karpenter.k8s.aws/instance-category
operator: In
values: ["c","m","r","t"]
- key: "karpenter.k8s.aws/instance-family"
operator: In
values: ["m5","m5d","c5","c5d","c4","r4"]
- key: karpenter.k8s.aws/instance-size
operator: NotIn
values: ["nano","micro","small","medium"]
- key: topology.kubernetes.io/zone
operator: In
values: ["us-west-2a","us-west-2b"]
- key: kubernetes.io/arch
operator: In
values: ["amd64","arm64"]
limits:
cpu: 100Refer to the Karpenter documentation for the complete list of fields for NodePool requirement.
The following is the example of NodePool with taints, user-defined labels and annotations that are added to all the nodes provisioned by Karpenter.
apiVersion: karpenter.sh/v1beta1
kind: NodePool
spec:
template:
metadata:
annotations:
application/name: "app-a"
labels:
team: team-a
spec:
taints:
- key: example.com/special-taint
value: "true"
effect: NoScheduleapiVersion: apps/v1
kind: Deployment
metadata:
name:
spec: myapp
nodeSelector:
team: team-aKarpenter supports all standard Kubernetes scheduling constraints, such as node selectors, node affinity, taints/tolerations, and topology spread constraints. This allows applications to use these constraints when scheduling pods on the nodes provisioned by Karpenter.
NodeClasses in Karpenter allow you to configure cloud provider-specific settings for your nodes in Kubernetes cluster. Each NodePool references a NodeClass that determines the specific configuration of nodes that Karpenter provisions. For example, you can specify settings such as the Amazon Machine Image (AMI) family, subnet and security group selectors, AWS Identity and Access Management (IAM) role/instance profile, node labels, and various Kubelet configurations in AWS EC2NodeClass and similarly for Azure AKSNodeClass.
Beyond scaling
Karpenter is more than an efficient cluster autoscaler for Kubernetes. Karpenter optimizes compute costs, helps upgrade and patch data plane worker nodes, and delivers powerful and explorative use cases by pairing with other CNCF tools.
Cost optimization
In the previous section, we saw how Karpenter provisions appropriate worker virtual machines (VMs) based on pod resource requests. As the workloads in a Kubernetes cluster change and scale, it can be necessary to launch new instances to make sure they have the compute resources they need. Over time, those instances can become under-used as some workloads scale down or are removed from the cluster. Workload consolidation for Karpenter automatically looks for opportunities to reschedule these workloads onto a set of more cost-efficient instances, whether they are already in the cluster or need to be launched.
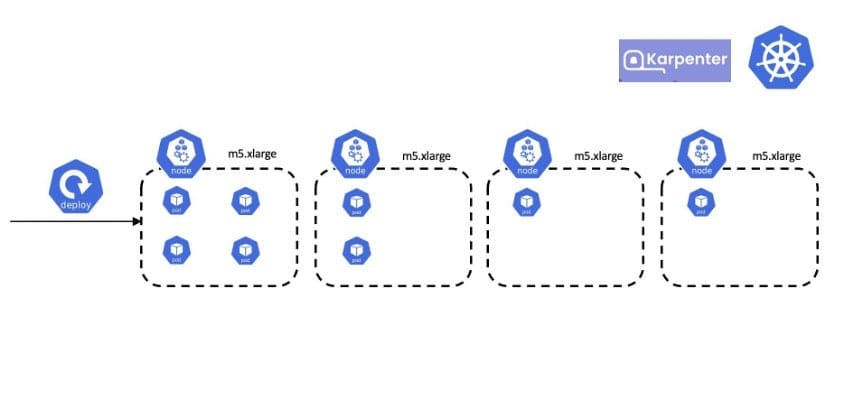
In the preceding diagram, the first node is highly used but the others aren’t used as well as they could be. With Karpenter, you can enable the consolidation feature in the NodePool YAML:
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: default
spec:
disruption:
consolidationPolicy: WhenEmptyOrUnderutilizedKarpenter is always evaluating and working to reduce the cluster cost. Karpenter consolidates workloads onto the fewest, lowest-cost instances, while still respecting the pod’s resource and scheduling constraints. With the preceding scenario, Karpenter moves the pods from the last two nodes into the second node, and terminates the resultant empty nodes:
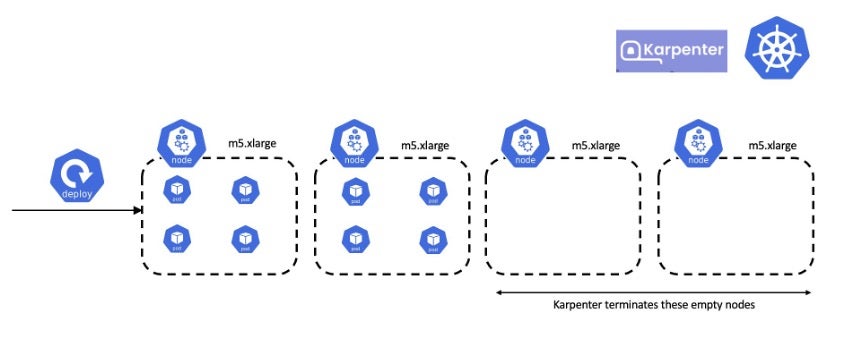
Karpenter prioritizes nodes to consolidate based on the least number of pods scheduled. For users with workloads that experience sudden spikes in demand or interruptible jobs, frequent pod creation and deletion (pod churn) might be a concern. Karpenter offers a consolidateAfter setting to control how quickly it attempts to consolidate nodes to maintain optimal capacity and minimize node churn. By specifying a value in hours, minutes, or seconds, users can determine the delay before Karpenter initiates consolidation actions in response to pod additions or removals.
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: default
spec:
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized
consolidateAfter: 1h With consolidation, Karpenter also rightsizes the worker nodes. For example, in the following case, if Karpenter consolidates the pod from the third node to the second (m5.xlarge), then there is still underusage. Karpenter instead provisions a smaller node (m5.large) and consolidates the pods, resulting in lower cost.
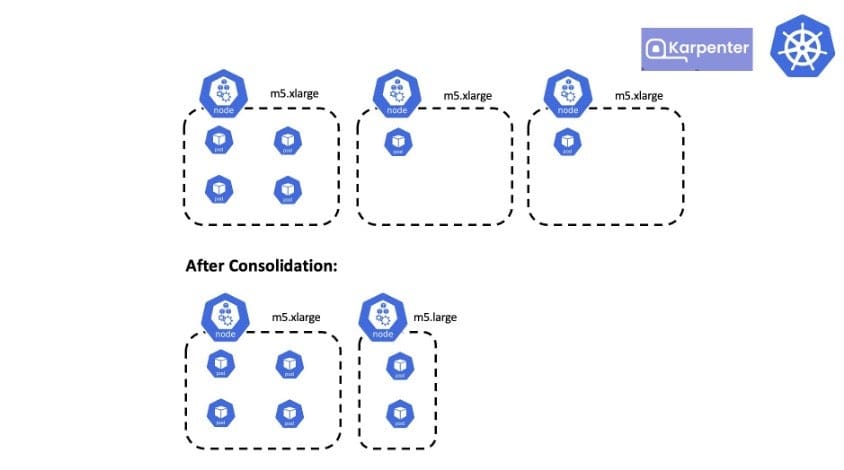
To know more about consolidation, refer to this official documentation
Lifecycle Management of Worker Nodes
Karpenter can make sure your worker nodes always run with the latest node image/Amazon Machine Image (AMI). In the NodeClass YAML, you can specify the AMI family and version as follows:
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: default
spec:
amiSelectorTerms:
- alias: bottlerocket@latestamiSelectorTerms is a necessary field of the NodeClass and a new term, alias, has been introduced with version 1.0, which consists of an AMI family and a version (family@version). If an alias exists in the NodeClass, then Karpenter selects the AMI supplied by the cloud provider for that family. With this new feature, users can also pin to a specific version of an AMI. For AWS, the following Amazon Elastic Kubernetes Service (Amazon EKS) optimized AMI families can be configured: al2, al2023, bottlerocket, windows2019, and windows2022
All the nodes provisioned by this NodeClass, will have the latest bottlerocket AMI. Because this alias uses @latest version, when the cloud provider releases a new optimized AMI for the Kubernetes version cluster is running with, then Karpenter updates the worker node AMIs automatically, respecting the Kubernetes scheduling constraints. Worker nodes are upgraded in a rolling deployment fashion. If the cluster is upgraded to a newer version, then Karpenter automatically upgrades the worker nodes with the latest AMI for this new version, automatically and without manual intervention. This takes away management overhead and lets you always run with the latest and most secure AMI. This works well in pre-production environments where it’s nice to be auto-upgraded to the latest version for testing, but more control over AMI versions is recommended in production environments.
Alternatively, you can also pin your worker nodes to a specific version of the AMI as follows:
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: default
spec:
amiSelectorTerms:
- alias: bottlerocket@v1.20.3In this case, if the cloud provider releases new bottlerocket AMI, Karpenter doesn’t drift the worker nodes.
Karpenter also supports custom AMIs. You can use the existing tags, name, or ID field in amiSelectorTerms to select an AMI. In the following case, the AMI with ID ami-123 is selected to provision the nodes. The amiFamily Bottlerocket injects pre-generated user data into the provisioned node.
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: default
spec:
...
amiFamily: Bottlerocket
amiSelectorTerms:
- id: ami-123To upgrade the worker nodes, change the amiSelectorTerms to select a different AMI, and nodes drift and upgrade to the assigned AMI.
Karpenter Working with Other CNCF projects
Karpenter can be used with other CNCF projects to deliver powerful solutions for common use cases. One prominent example of this is using Kubernetes Event Driven Autoscaling (KEDA) with Karpenter to implement event driven workloads. With KEDA, you can drive the scaling of any container in Kubernetes based on the number of events needing to be processed. One popular implementation is to scale up worker nodes to accommodate pods that process messages coming into a queue:
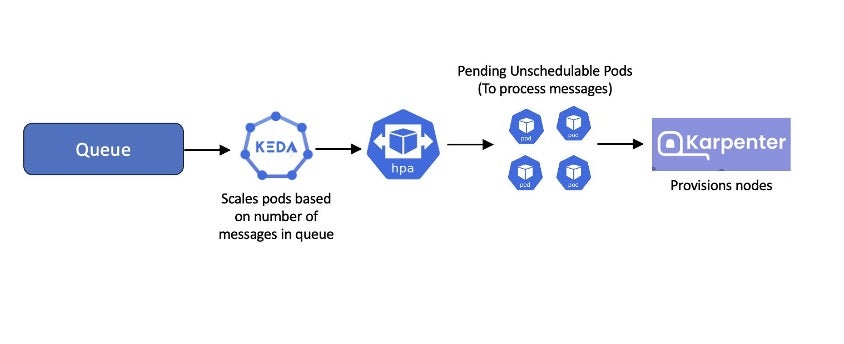
Often users want to scale down the number of worker nodes during off hours. KEDA and Karpenter can support this use case:
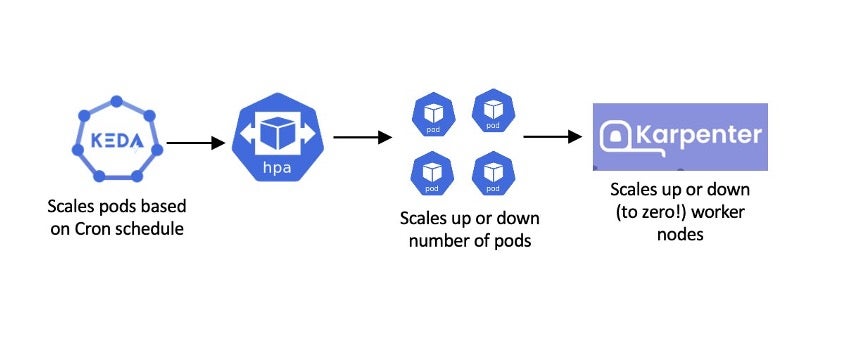
Karpenter can be combined with other CNCF projects such as Prometheus, Argo Workflows, Grafana to achieve diverse use cases. Check out this previous talk from Kubecon EU 2024 how Argo Workflows can be combined with Karpenter to migrate from Cluster Autoscaler.
Adopting Karpenter
To get started with Karpenter, you can follow the official Getting Started with Karpenter guide, which provides a step-by-step procedure for creating an EKS cluster using eksctl and adding Karpenter to it. Alternatively, if you prefer using Terraform, then you can use the Amazon EKS Blueprints for Terraform, which includes a Karpenter module, thus streamlining the process of setting up Karpenter alongside your EKS cluster. Furthermore, there are guides available for setting up Karpenter with other Kubernetes distributions such as kOps on AWS. And if you want to migrate from Kubernetes Cluster Autoscaler to Karpenter for automatic node provisioning on an existing EKS cluster, then you can refer this guide for the detailed steps.
What’s next
Karpenter has evolved far beyond being a tool for autoscaling, showcasing its versatility and deeper integration within the cloud-native ecosystem. Karpenter not only scales worker nodes but also drives cost efficiencies, seamlessly managing diverse workloads such as generative AI, facilitating data plane upgrades with precision, and more.
Looking ahead, the possibilities for Karpenter are endless, especially as organizations explore groundbreaking use cases. We are only beginning to scratch the surface of what Karpenter can achieve when combined with other CNCF projects. The potential for Karpenter to contribute to next-generation infrastructure is immense, and we can’t wait to observe the inventive and powerful use cases users come up with, making their cloud operations more efficient, scalable, and intelligent.
To shape the future of Karpenter, let us know what features we should work on by upvoting and commenting here.
If you are attending KubeCon NA 2024, then you can meet with us at the AWS Booth F1, or attend our Karpenter workshop Tutorial: Kubernetes Smart Scaling: Getting Started with Karpenter to learn more.
Authors
Rajdeep Saha, Principal Solutions Architect, AWS
Raj is the Principal Specialist SA for Containers, and Serverless at AWS. Rajdeep has architected high profile AWS applications serving millions of users. He is a published instructor on Kubernetes, Serverless, DevOps, and System Design, has published blogs, and presented well-received talks at major events, such as AWS Re:Invent, Kubecon, AWS Summits.

Praseeda Sathaye, Principal SA, Containers & OSS
Praseeda Sathaye is a Principal Specialist for App Modernization and Containers at Amazon Web Services, based in the Bay Area in California. She has been focused on helping customers accelerate their cloud-native adoption journey by modernizing their platform infrastructure and internal architecture using microservices strategies, containerization, platform engineering, GitOps, Kubernetes and service mesh. Praseeda is an ardent advocate for leveraging Generative AI (GenAI) on Amazon Elastic Kubernetes Service (EKS) to unlock the full potential of cutting-edge technologies, enabling the development of AI-powered applications.
