
Project post by the Jaeger maintainers
Jaeger, the popular open-source distributed tracing platform, has had a successful 9 year history as being one of the first graduated projects in the Cloud Native Computing Foundation (CNCF). After over 60 releases, Jaeger is celebrating a major milestone with the upcoming release of Jaeger v2. This new version is a new architecture for Jaeger components that utilizes OpenTelemetry Collector framework as the base and extends it to implement Jaeger’s unique features. It brings significant improvements and changes, making Jaeger more flexible, extensible, and better aligned with the OpenTelemetry project.
In this blog post, we’ll dive into the details of Jaeger v2, exploring its design, features, and benefits. Sharing what users can expect from this exciting new release and what is next for the project.
OpenTelemetry Foundation
OpenTelemetry is the de-facto standard for application instrumentation providing the foundation for observability. Jaeger is now based on the cornerstone of this project, the OpenTelemetry Collector. Jaeger is a complete tracing platform that includes storage and the UI. OpenTelemetry Collector is usually an intermediate component in the collection pipelines that are used to receive, process, transform, and export different telemetry types. The two systems have some overlaps, for example, `jaeger-agent` and `jaeger-collector` play a role similar to what can be done with OpenTelemetry Collector, but only for traces.
Historically, both Jaeger and OpenTelemetry Collector reused each other’s code. Collector supports receivers for legacy Jaeger formats implemented by importing Jaeger packages. And Jaeger reuses Collector’s receivers and data model converters. Because of this synergy, it’s been our goal for a while to bring the two projects closer.
OpenTelemetry Collector has a very flexible and extensible design, which makes it easy to extend with additional components needed for Jaeger use cases.
Features and Benefits
By aligning the Jaeger v2 architecture with OpenTelemetry Collector, we deliver several exciting features and benefits for users, including:
- Native OpenTelemetry processing: Jaeger v2 natively supports OTLP data format, eliminating the translation step from OTLP to Jaeger’s internal data format and improving performance.
- Batched data processing: the OpenTelemetry Collector pipelines operate on batches of data, which can be especially important for storage backends like ClickHouse that are much more performant with batch inserts. Jaeger v2 will be able to utilize this batch-based internal pipeline design.
- Familiar developer experience: Jaeger v2 follows the same configuration and deployment model as OpenTelemetry Collector, providing a more consistent developer experience.
- Access to OpenTelemetry Collector features: Jaeger v2 inherits all the core features of the Collector, including auth, cert reloading, internal monitoring, health checks, z-pages, etc.
- Advanced sampling capabilities: Jaeger v2 introduces the ability to perform tail-based sampling, using the upstream OpenTelemetry-contrib processor. It also fully supports Jaeger’s original Remote and Adaptive head-based sampling methods.
- Access to OpenTelemetry Collector ecosystem: Jaeger v2 can use a multitude of extensions available for OpenTelemetry Collector, such as span-to-metric connector, telemetry rewriting processors, PII filtering, and many others. For example, we are able to reuse Kafka exporter and receiver and replicate the Jaeger v1 collector-ingester deployment model without maintaining any extra code.
The result is a leaner code base and more importantly the ability to future proof Jaeger as OpenTelemetry evolves to ensure Jaeger is always the first tracing system for open source users. Compatibility between OpenTelemetry and Jaeger will be supported on day 1 due to the tight integration between the projects. This will continue collaboration between both projects, getting more users to adopt open source technologies more quickly.
Design and Architecture
Overall, Jaeger v2 architecture is very similar to a standard OpenTelemetry Collector that has pipelines for receiving and processing telemetry (a pipeline encapsulates receivers, processors, and exporters), and extensions that perform functions not directly related to processing of telemetry. Jaeger v2 makes a few design decisions in how to use the Collector framework.
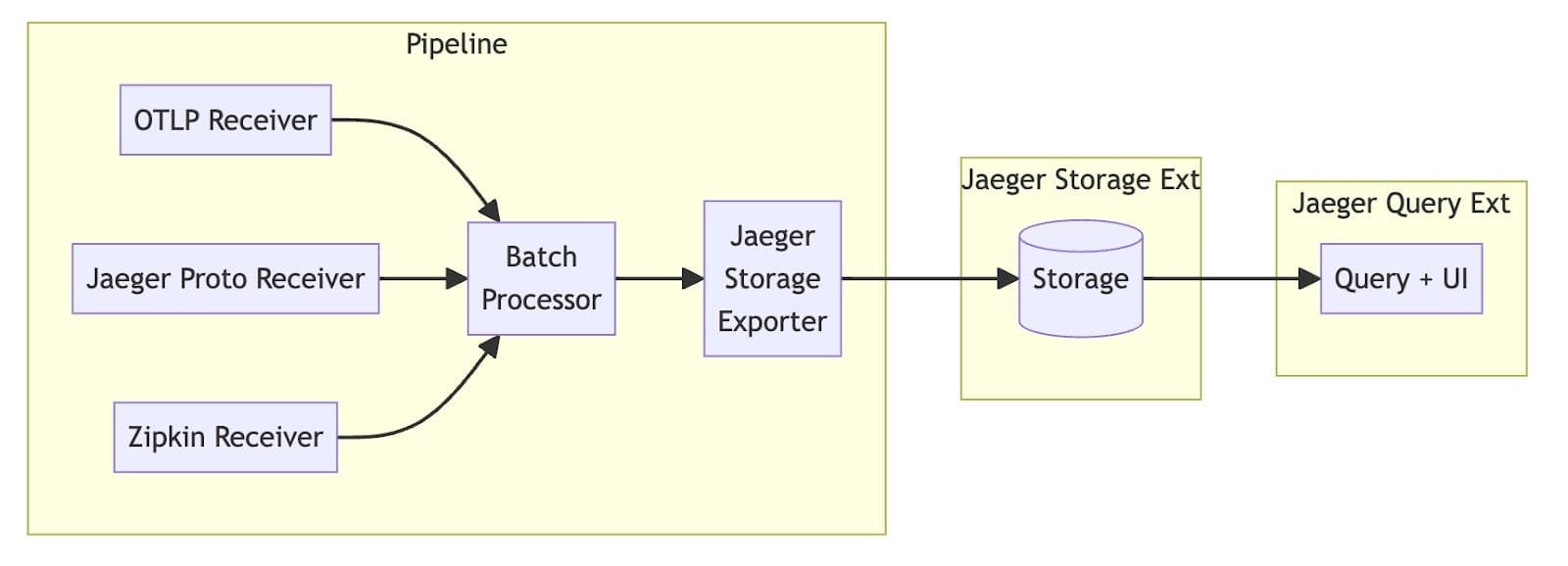
Query Extension 🔎
Since Collector is primarily designed for data ingestion, querying for traces and presenting them in the UI is an example of functionality that is not in its remit. Jaeger v2 implements it as a Collector extension.
Single Binary
Jaeger v1 provided multiple binaries for different purposes (agent, collector, ingester, query). Those binaries were hardwired to perform different functions and exposed different configuration options passed via command line. We realized that all that complexity was unnecessary in the v2 architecture as we achieve the same simply by enabling different components in the configuration file. We also did some benchmarking of executable size and noticed that if we bundle all possible Jaeger v2 components in a single binary, including ~3Mb (compressed) of UI assets, we end up with a container image of ~40Mb in size, versus ~30Mb in v1. As a result, Jaeger v2 ships just a single binary `jaeger`, and it will be configurable for different deployment roles via YAML configuration file, the same as the OpenTelemetry Collector.
Storage Implementation
Both Jaeger and OpenTelemetry Collector process telemetry data, but they differ in how they handle it.
- OpenTelemetry Collector: Focuses on one-way data processing (receive, process, export). To store data, it uses specific exporters for each database (e.g., Elasticsearch Exporter).
- Jaeger: Handles both writing and reading data, allowing queries and visualization through a UI. This requires a shared storage backend, unlike the Collector’s approach.
Jaeger v2 implements a storage extension to abstract the storage layer. This allows both the query component (read path) and a generic exporter (write path) to interact with various storage backends without dedicated implementations for each. This approach provides flexibility and maintains compatibility with Jaeger v1’s multi-storage capabilities.
What’s in v2
- ✅ A single binary & Docker image configurable to run in different roles, such as collector, ingester, query, and a collection of configuration file templates for these roles.
- ✅ Support for all official storage backends with full backwards compatibility with Jaeger v1.
- ✅ Support for Kafka as intermediate queue, in both OTLP and Jaeger legacy data formats.
- ✅ Support for primary and archive storage.
- ✅ Support for remote and adaptive head sampling.
- ✅ Support for tail sampling .
- ✅ Service Performance Management (SPM).
- ✅ Internal observability integrated with OpenTelemetry Collector configuration.
- ✅ Refreshed documentation and v1→v2 migration guide.
▶️ Try Jaeger v2 today and check out the Getting Started documentation for more options:
docker run –rm –name jaeger \
-p 16686:16686 \
-p 4317:4317 \
-p 4318:4318 \
jaegertracing/jaeger:2.0.0
What’s Next
Version 2.0.0 already supports all the core features of Jaeger, but the development will continue in 2025 to add remaining feature parity, improving performance, and enhancing the overall user experience.
The roadmap for Jaeger v2 includes the following milestones:
- 🚧 Helm Chart for Jaeger v2.
- 🚧 Jaeger v2 support natively in the OpenTelemetry Operator.
- 📅 Upgrading storage backend implementations to Storage v2 interface to use OpenTelemetry data natively.
- 📅 Support ClickHouse as official storage backend.
- 🔮 Upgrading UI to use OpenTelemetry data natively.
- 🔮 Upgrading UI to normalize dependency views.
Leveraging Mentorship Programs 🎓
The Jaeger v2 roadmap was designed to minimize the amount of changes we needed to make to the project by avoiding a big-bang approach in favor of incremental improvements to the existing code base. Yet it was still a significant amount of new development, which is often difficult to sustain for a volunteer-driven project. We were able to attract new contributors and drive the Jaeger v2 roadmap by participating in the mentorship programs run by Linux Foundation, CNCF, and Google, such as LFX Mentorship and Google Summer of Code. This has been a rewarding and mutually beneficial engagement for both the project and the participating interns. Stay tuned for our next mentorships to build out the roadmap items.
Conclusion
Jaeger v2 represents a significant step forward for the Jaeger project, bringing improved flexibility, extensibility, and alignment with the OpenTelemetry project. With its native OTLP ingestion, simplified deployment model, and access to OpenTelemetry Collector features, Jaeger v2 promises to provide a more efficient and scalable distributed tracing solution.
As the development of Jaeger v2 continues, we can expect to see a more robust and feature-rich system emerge. Stay tuned for updates and get ready to experience the next generation of distributed tracing with Jaeger v2!