
Member post by Gabriele Bartolini, VP Chief Architect of Kubernetes at EDB
Abstract
This article delves into the concept of cloud neutrality— a term I prefer over agnosticism— in PostgreSQL deployments. It highlights the transformative impact of Kubernetes as a cloud-neutral platform, enabling organizations to deploy and manage PostgreSQL across diverse environments, including on-premises, hybrid, and multi-cloud setups. Key organizational considerations, such as vendor lock-in, cost predictability, and development velocity, are examined alongside various deployment models, from traditional on-premises Linux to modern Kubernetes-based solutions. The discussion emphasizes the importance of involving database administrators (DBAs) in transitioning to cloud-native architectures and presents CloudNativePG as a robust solution for building a scalable, flexible, and cloud-neutral PostgreSQL ecosystem.
Introduction
The demand for databases continues to grow at a rapid pace. Gartner reports that the global database market grew by 13.4% in 2023, with nearly 80% of databases being relational systems like PostgreSQL. This surge is further propelled by the expanding presence of hyperscalers—Amazon, Google, and Microsoft—offering robust Database-as-a-Service (DBaaS) solutions. PostgreSQL has solidified its position as the most popular database, with increasing adoption not only for its technical strengths but also as a way to reduce vendor lock-in.
While public cloud services continue to dominate the market, many organizations that rely on PostgreSQL are increasingly adopting Kubernetes as a central part of their infrastructure strategy. This shift is motivated by the pursuit of cloud neutrality, enabling businesses to avoid vendor lock-in at the provider level and gain greater flexibility while consciously taking on more operational responsibilities. By embracing Kubernetes, organizations also unlock the potential to deliver multi-cloud and hybrid-cloud solutions, providing more versatile services to customers worldwide. Let’s explore how and why this transition is redefining the future of PostgreSQL deployments through the CloudNativePG stack.

On-Premises PostgreSQL
When I started using PostgreSQL in production in the early 2000s, I ran it on a bare metal Linux operating system with a hardware RAID controller and multiple locally attached disks. To optimize costs and resource utilization, I ran several PostgreSQL instances on the same machine, each assigned to different TCP ports. This was a common approach to consolidating database infrastructure at the time.
As technology advanced, the rise of virtualization and configuration management tools significantly improved on-premises database management. These innovations have fueled PostgreSQL’s global adoption, making on-prem deployments a solid option for organizations that require complete control and ownership of their infrastructure.
Today, on-premises deployments are often favored by organizations with a strong understanding of their workloads, who must manage their systems’ security, performance, business continuity, and compliance. Industry-specific regulations, government mandates, and data sovereignty requirements make this approach indispensable in certain sectors.
Postgres in the Cloud: Infrastructure as a Service (IaaS)
The late 2000s saw a significant shift with the rise of infrastructure-as-a-service (IaaS), driven by the rapid growth of cloud computing. By the early 2010s, Postgres databases were transitioning from traditional on-prem data centers to cloud-based solutions, allowing users to rent virtual servers and storage on demand while paying for actual resource usage.
With tools like Terraform and automation platforms like Ansible, the provisioning, deployment, and configuration of PostgreSQL databases has become far more efficient, particularly for Day 1 operations. However, despite the advantages in speed and flexibility, Day 2 operations—such as availability, maintenance, scaling, and optimization—still require substantial involvement from database administrators (DBAs) and often remain confined to the database domain, disconnected from the broader infrastructure and applications.
While IaaS solutions reduce lead times for provisioning compute and storage, they also bring challenges such as vendor lock-in and unpredictable costs, despite the promise of pay-as-you-go savings. Hybrid and multi-cloud strategies aim to reduce vendor dependency, but their implementation is often complex and resource-intensive.
Interestingly, IaaS also played a pivotal role in accelerating the rise of platform-as-a-service (PaaS) and software-as-a-service (SaaS). A prime example is Heroku, a pioneering PaaS that gained popularity among Ruby developers and significantly contributed to the growing adoption of PostgreSQL around 2010.
Postgres in the Cloud: Database as a Service (DBaaS)
Building on the IaaS model, Database-as-a-Service (DBaaS) for PostgreSQL has become increasingly popular since 2013, particularly for organizations seeking to outsource most Day 2 operations. With DBaaS, service providers manage the underlying infrastructure, operating system, and PostgreSQL server, allowing customers to focus on application development and business needs.
Today, DBaaS is synonymous with cloud databases. Major cloud providers offer DBaaS solutions like Amazon RDS for PostgreSQL, Google Cloud SQL for PostgreSQL, and Azure Database for PostgreSQL, alongside specialized solutions such as EDB Postgres AI Cloud Service from my company. These services simplify database management by providing high availability, disaster recovery, and observability, with geographical redundancy across multiple cloud regions.
While DBaaS significantly reduces infrastructure complexity and operational overhead, it limits direct control over the PostgreSQL backend, restricting access to a PostgreSQL connection, CLI, or web-based dashboard. This trade-off can accelerate development velocity, but it also introduces concerns like vendor lock-in, unpredictable costs, and data portability. The recent European Union Data Act highlights the importance of data portability (i.e. switching between cloud providers, implementing multi/hybrid solutions, and migrating data without downtime), urging organizations to consider these factors carefully when adopting DBaaS. Unless the DBaaS is designed with a multi-cloud approach and specifically optimized for PostgreSQL (as with EDB’s solution), migrating data away from the cloud service provider can be challenging.
Cloud-Neutral PostgreSQL
Managing PostgreSQL across on-premises, IaaS, and hybrid/multi-cloud environments exposes significant complexity and operational trade-offs. Each scenario brings its own challenges, making it difficult to maintain consistency and flexibility.
A cloud-neutral approach offers a solution by enabling highly portable infrastructure that facilitates seamless transitions between cloud and on-premise environments. This model supports Day 1 tasks (provisioning, setup) and Day 2 tasks (scaling, monitoring, backups), without sacrificing performance or manageability. By using open-source technologies and standardized APIs, organizations can avoid vendor lock-in, reduce operational overhead, and retain the flexibility to choose the best infrastructure.
The cloud-neutral PostgreSQL solution we propose is based on the CloudNativePG open-source stack, composed of Kubernetes, PostgreSQL, and CloudNativePG. This stack already empowers organizations worldwide to build highly portable infrastructures, deployable on-premises (including bare metal) or hybrid configurations. By leveraging Kubernetes-as-a-service (KaaS) solutions from hyperscalers like Amazon EKS, Azure AKS, and Google GKE, or container platforms like Red Hat OpenShift, or even the standard Kubernetes distribution, businesses can embrace cloud neutrality.
Cloud Neutrality with Kubernetes
Kubernetes is an open-source platform that provides a standard abstraction layer for managing infrastructure and applications within Linux containers. Its modular design, extensibility, fault tolerance, self-healing, and compliance with Infrastructure as Code (IaC) principles make it ideal for organizations looking for highly portable, cloud-neutral infrastructures.
Kubernetes is the most popular Cloud Native Computing Foundation (CNCF) project and can be deployed anywhere—from bare metal servers to virtual machines. Organizations can choose between self-managed Kubernetes or managed KaaS solutions depending on their expertise. Additionally, enterprise platforms based on Kubernetes, like Red Hat OpenShift, Suse Rancher, or VMware Tanzu, extend cloud neutrality to enterprise environments, facilitating seamless movement between on-premise, private, and public cloud infrastructures.

Kubernetes unlocks a truly cloud-neutral infrastructure, allowing organizations to deploy workloads in private, public, or hybrid clouds with minimal changes to code or configuration. Thanks to GitOps and the integration of IaC, Kubernetes is a key enabler for cloud-neutral PostgreSQL, providing the flexibility needed for future-proof database deployments.
Cloud-Neutrality for PostgreSQL with CloudNativePG
Kubernetes facilitates cloud neutrality for infrastructure and containerized workloads, but managing PostgreSQL databases in this environment presents unique challenges. While Kubernetes treats PostgreSQL as just another application, relying on standard resources like `Deployments` and `StatefulSets` is insufficient due to the database’s inherent complexity. Though we often strive to move away from treating databases as “pets” and adopt the “cattle” model, it’s important to remember that PostgreSQL’s mascot is an elephant—symbolizing strength and requiring careful management (instead of “cattle,” perhaps “herd” is the more fitting analogy).
This is where a PostgreSQL Operator comes into play. The operator pattern extends Kubernetes’ capabilities through custom resources, controllers, and declarative configurations, allowing the orchestration of complex applications like PostgreSQL in a cloud-native way.
A well-designed PostgreSQL operator provides the essential custom resources and controllers that enable Kubernetes to manage the database efficiently. This ensures PostgreSQL meets core cloud-native requirements such as high availability, self-healing, scalability, and security, while also leveraging its powerful business continuity features. These include native replication mechanisms like Hot Standby, synchronous replication, cascading replication, along with support for hot backups, continuous backup, and Point-in-Time Recovery (PITR). Together, these capabilities form a solid foundation for data integrity, resilience, and operational excellence in a cloud-native world.
There are several PostgreSQL operators available, but CloudNativePG is the one on which I will be focusing, for a few key reasons:
- I am one of the founders and maintainers of the project.
- It’s open-source, licensed under Apache License 2.0.
- It is the only PostgreSQL operator governed by a vendor-neutral community. While EDB, the original creator and major contributing organization, donated the intellectual property to the CloudNativePG community in May 2022, the community now openly manages the project.
- It is the only PostgreSQL operator submitted to the CNCF Sandbox.
- It’s the most popular PostgreSQL operator on GitHub with over 4.5k stars, 58M downloads, the fastest-growing adoption rate, and the highest level of community engagement.
- The documentation is very comprehensive.
- CloudNativePG is Kubernetes-native, fully leveraging and extending the Kubernetes API. It is entirely declarative, secure by default, and integrates seamlessly with cloud-native standard tools for observability.
- CloudNativePG collaborates with the Kubernetes storage project to address the unique demands of large database workloads, particularly in the areas of volume snapshot for backup/recovery and local storage for performance and data durability.
By defining a CloudNativePG `Cluster` resource, users can ensure their PostgreSQL database, with a primary node and any number of read-only replicas, operates in business continuity scenarios with minimal Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO), with 99.99% uptime realistically attainable over a year. The same resource can be deployed, unchanged, across any cloud environment or multiple Kubernetes clusters for hybrid and multi-cloud scenarios, handling most Day 2 operations automatically. Users retain full control over their data with no vendor lock-in, ensuring complete data portability as required by the European Union’s Data Act (PostgreSQL’s native streaming replication—logical or physical—supports this flexibility).
This is how the CloudNativePG stack, built on Kubernetes and PostgreSQL, delivers true cloud neutrality.
Additionally, Kubernetes’ scheduling capabilities allow users to allocate specific machines for PostgreSQL workloads. By applying labels and taints to nodes and defining affinity rules and tolerations on CloudNativePG `Cluster` resources, PostgreSQL can run in complete isolation from other applications at the physical layer, while seamlessly integrating at the logical layer. This approach mirrors a microservice database architecture, where the application and its backend coexist within the same Kubernetes namespace.
Cloud-Neutrality for PostgreSQL DBaaS with CloudNativePG
Moreover, the CloudNativePG stack is an excellent choice for isolating applications and backend databases at the logical layer while providing a cloud-neutral database-as-a-service (DBaaS) solution. Relying on standard resources, such as load balancer services, safely exposes PostgreSQL outside Kubernetes. This setup effectively serves both internal customers within your organization and external clients, as demonstrated by IBM’s Cloud Pak, EDB’s Postgres AI Cloud Service, and Tembo.
The Return of Bare Metal PostgreSQL
One of the most common misconceptions about Kubernetes is that it can only run on virtual machines. In reality, Kubernetes operates just as effectively—if not more efficiently—on bare metal infrastructure without the need for a hypervisor. The diagram below offers a simplified view of the key layers in bare metal and virtual machine Kubernetes nodes.
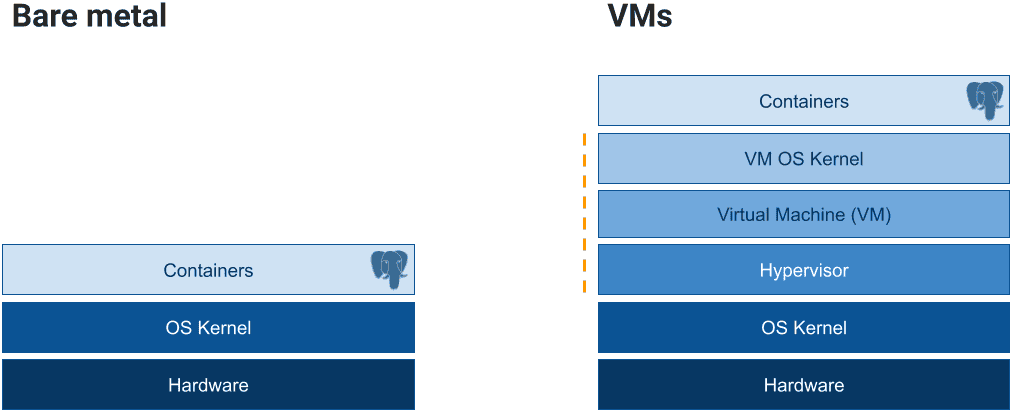
By running directly on the host, containers can fully exploit the underlying hardware, eliminating the overhead of virtualization and even doubling the efficiency and performance compared to VMs. This is especially important for stateful workloads, such as databases, which can be deployed on dedicated bare metal Kubernetes nodes and benefit from locally attached storage. This setup creates a unique opportunity for database professionals to implement highly performant, robust, shared-nothing architectures for PostgreSQL clusters, all managed seamlessly through declarative configuration. (After all, the very existence of CloudNativePG stems from the first fail-fast experiment my team conducted in late 2019, when we launched our Postgres initiative. The goal was to measure the performance of Kubernetes on bare metal—and, as you might have guessed, the results spoke for themselves.)
Thanks to the CloudNativePG stack, PostgreSQL DBAs can now run PostgreSQL on-premises in Kubernetes, on bare metal, and replicate it across private or public Kubernetes clusters using symmetric architectures. This offers a highly portable and standardized approach to hybrid cloud environments—a truly cloud-neutral PostgreSQL solution that can help reverse or slow the migration of databases to public clouds, enabling a shift back to hybrid or fully on-premises deployments.
The opportunity for PostgreSQL DBAs
As I have previously written, PostgreSQL DBAs are at a critical career crossroads when approaching Kubernetes: should they adopt, avoid, or deny it?
Having dedicated the past five years of my Cloud Native initiative to making it easier to run PostgreSQL on Kubernetes, I’m now shifting to the next phase—helping PostgreSQL experts transition smoothly into the Kubernetes ecosystem. While spinning up a PostgreSQL cluster in Kubernetes has now become remarkably straightforward, there is an expansive and largely uncharted realm of opportunities that only seasoned PostgreSQL experts can fully explore and master. This transition will undoubtedly require effort and adaptation from DBAs, who must develop sufficient Kubernetes knowledge (a T-shaped profile) to collaborate effectively with Kubernetes experts regarding the PostgreSQL database from day 0 (planning). However, the rewards are clear, as confirmed by PostgreSQL DBAs who have successfully navigated this journey. In many ways, this transition mirrors the shift DBAs experienced over the past two decades when moving from bare metal to virtual machines.
Based on my experience, PostgreSQL DBAs deeply appreciate open-source software and are well-versed in running Linux commands. Kubernetes, alongside Linux and PostgreSQL, is one of the most fascinating and transformative open-source projects and communities in history. While Kubernetes is vast and complex, it is also modular, meaning DBAs don’t need to master every aspect of it. Instead, they can focus on the essentials for managing CloudNativePG PostgreSQL clusters: understanding pods and containers, networking (service resources), storage (storage classes, persistent volume claims, and persistent volumes), and having enough familiarity to collaborate effectively with infrastructure administrators on areas like IaC, GitOps, TLS certificates, monitoring (using Prometheus for metrics and alerts), and logging (as logs aren’t stored on disk). Investing a month or two of study into this skill set can unlock a decade of new opportunities.
The Decision-Making Process Behind Cloud Databases
Achieving true cloud neutrality at the infrastructure level requires your organization to develop or acquire Kubernetes expertise through internal teams or external partnerships. This expertise varies depending on the platform choice—whether using upstream Kubernetes (which demands the most skills), Kubernetes-as-a-Service (KaaS), or enterprise-grade container platforms like Red Hat OpenShift and SUSE Rancher.
The diagram below outlines the decision-making process for adopting the CloudNativePG stack based on my experience and analysis of customer journeys and conversations over the past five years. While simplified, it accurately reflects the broader trends in the industry, even if some details may differ in specific contexts.
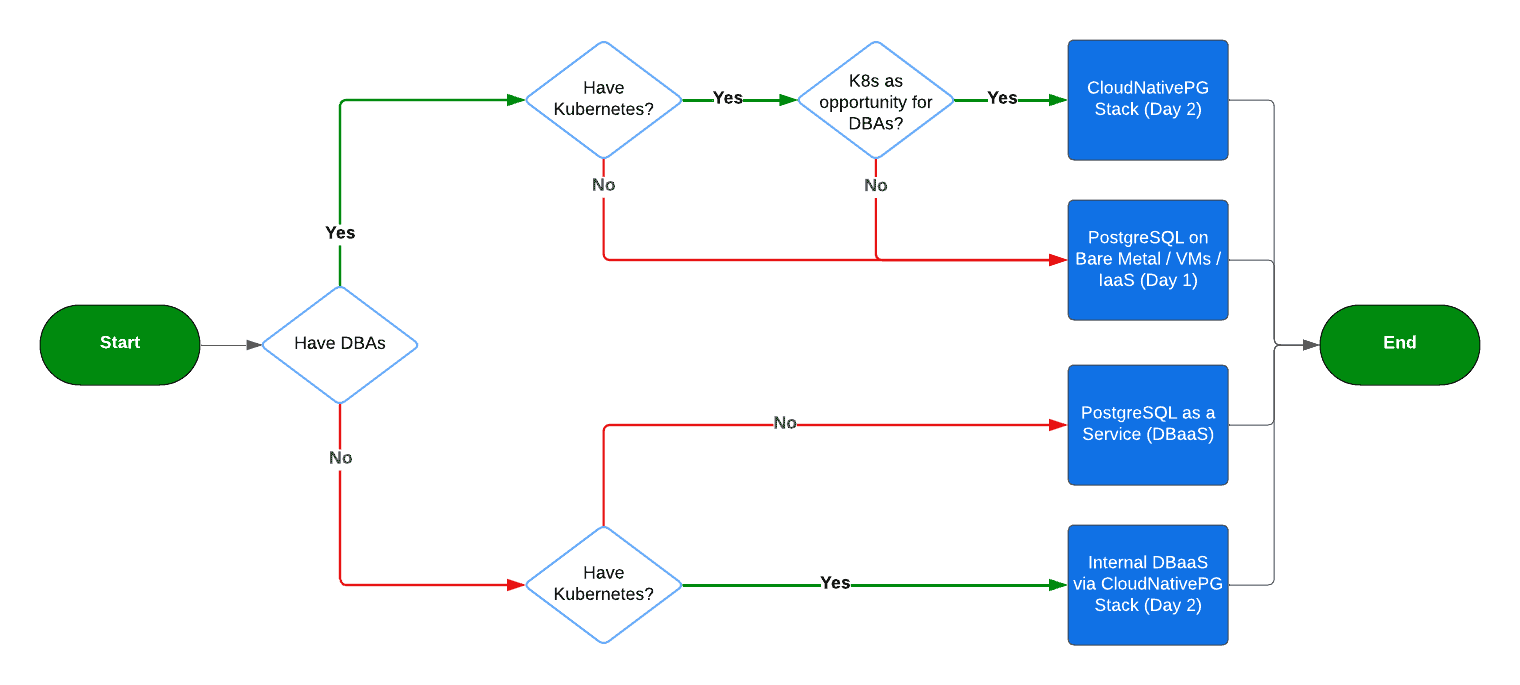
For organizations aiming to extend cloud neutrality to PostgreSQL and fully leverage the CloudNativePG stack, it’s essential for PostgreSQL DBAs to be engaged from the start. If your team lacks Kubernetes knowledge or your DBAs are reluctant to embrace this transition, it may be prudent to stick with more familiar options like running PostgreSQL on bare metal, virtual machines, or Infrastructure-as-a-Service (IaaS). Although not explicitly represented in the diagram for simplicity, in these cases, DBAs may also rely on Database-as-a-Service (DBaaS) solutions, especially when other stakeholders like developers drive the decision.
For organizations without dedicated DBAs or Kubernetes expertise, DBaaS remains a popular and pragmatic option.
However, a growing trend is emerging among organizations that have strategically adopted Kubernetes but don’t have dedicated DBAs. These companies are using the CloudNativePG stack to provide Database-as-a-Service to their internal customers—primarily developers and engineers from other departments. This approach offers a balanced solution between traditional infrastructure management and a fully managed cloud DBaaS. While I can’t disclose specific company names, this use case is increasingly common among larger enterprises in sectors like manufacturing, banking, finance, payments, automotive, and IT services. The trend is especially pronounced in Europe, where on-premise infrastructure is often preferred. The CloudNativePG stack’s ability to provide declarative isolation of workloads, both logically and physically, enables PostgreSQL consolidation on bare metal Kubernetes nodes, creating a win-win scenario for both infrastructure administrators and DBAs.
As a final note, it’s important to emphasize that EDB, the original creator and founder of CloudNativePG, is well-positioned to assist enterprises globally in migrating their Postgres databases to Kubernetes. EDB is at the forefront of PostgreSQL on Kubernetes technology, serving as a Silver Member of the CNCF and the only Kubernetes Certified Service Provider actively involved in PostgreSQL development. EDB offers a long-term supported version of CloudNativePG called EDB Postgres for Kubernetes (PG4K), which also provides access to EDB Postgres Advanced Server (EPAS), simplifying Oracle migrations, as well as EDB Postgres Distributed for Kubernetes (PGD4K) for active-active workloads.
Conclusions
To conclude, the rise of Kubernetes as a cloud-neutral platform is revolutionizing how PostgreSQL is deployed and managed across diverse environments. While blueprints and best practices can offer valuable guidance, the right deployment choice ultimately hinges on your organization’s specific needs and the expertise of its teams.
The table below summarizes key organizational considerations—such as vendor lock-in, cost predictability, and development velocity—across the major PostgreSQL deployment models available today, from traditional on-premises Linux setups to modern Kubernetes-based solutions.
| On-Premises PostgreSQL | PostgreSQL in the Cloud (IaaS) | PostgreSQL in the Cloud (DBaaS) | Cloud Neutral PostgreSQL (KaaS) | Cloud Neutral PostgreSQL (Self-Managed) | |
| Deployment model | Purchase / Consumption-based | Consumption-based | Consumption-based | Consumption-based | Purchase / Consumption-based |
| Cost predictability | High | Low/Medium | Low | Medium | High |
| Time to Market for DB Applications | Slow | Medium | Fast | Fast | Fast |
| Vendor Lock-In Risk | Low/None | High, typically | High | Low | Low/None |
| DBaaS Use | No | Yes, internal & external | N/A | Yes, external only | Yes, internal & external |
After addressing these organizational factors, we can dive deeper into the infrastructural and operating system layers to explore the key technical differences among the deployment options discussed in this article:
| On-Premises PostgreSQL | PostgreSQL in the Cloud (IaaS) | PostgreSQL in the Cloud (DBaaS) | Cloud Neutral PostgreSQL (KaaS) | Cloud Neutral PostgreSQL (Self-Managed) | |
| Hardware costs | High | None | None | None | High |
| Installation method | Packages on OS | Packages on OS | N/A | Immutable containers | Immutable containers |
| Bare Metal Support with Local Storage | Yes | No, typically | No | No, typically | Yes |
| Control Over System Configuration | High | High | None | None | High |
| Private Cloud Capability | Yes | No | No | No | Yes |
| Public Cloud Availability | No | Yes | Yes | Yes | Yes, potentially via IaaS |
| Hybrid Cloud Support | Yes | Yes | No | Yes | Yes |
| Multi-Cloud Support | No | Yes, but hard | No | Yes | Yes, potentially |
At this point, all major organizational and architectural considerations have been addressed, and your decision on which cloud model to adopt is likely clear. However, it’s equally important to evaluate aspects related to the Postgres database itself and the data it manages. These factors, summarized in the table below, can have a significant impact on your final deployment choice:
| On-Premises PostgreSQL | PostgreSQL in the Cloud (IaaS) | PostgreSQL in the Cloud (DBaaS) | Cloud Neutral PostgreSQL (KaaS) | Cloud Neutral PostgreSQL (Self-Managed) | |
|---|---|---|---|---|---|
| Business Continuity & Compliance | Yes, full responsibility | Yes, OS and up | No, database content only | Yes, database | Yes, full responsibility |
| Day 2 Operations (Maintenance) | Manual | Manual | Automated | Automated | Automated |
| Data portability (EU Data Act) | Yes | Yes | No | Yes | Yes |
| Control Over PostgreSQL Configuration | High | High | Limited | High | High |
| Database performance | High | Medium | Medium | Medium | High |
| Postgres Extensions Support | Full control | Full Control | Controlled by the provider | Full control | Full control |
| Postgres PKI Support (mTLS) | Yes, complex | Yes, complex | Yes | Yes | Yes |
With CloudNativePG, organizations can embrace a robust, high-performance, and standardized approach to running PostgreSQL clusters across bare metal, hybrid, or multi-cloud environments, all driven by declarative configuration. This empowers DBAs to implement cloud-neutral, shared-nothing architectures that avoid vendor lock-in while retaining full control over data and performance. As businesses increasingly move away from cloud-dependent models, CloudNativePG offers a scalable, future-proof solution for managing PostgreSQL in diverse and complex environments, including a return to on-premises deployments.