
Member post by Rohit Raveendran, Facets.Cloud
Introduction
What happens behind the scenes when a Kubernetes pod shuts down? In Kubernetes, understanding the intricacies of pod termination is crucial for maintaining the stability and efficiency of your applications. When a pod is terminated, it’s not just a simple shutdown; it involves a well-defined lifecycle that ensures minimal disruption and data loss. This process, known as graceful termination, is vital for handling in-progress requests and performing necessary clean-up tasks before a pod is finally removed.
This guide examines each lifecycle phase during pod termination, detailing the mechanisms for graceful handling, resource optimization strategies, persistent data management, and troubleshooting techniques for common termination issues. By the end of this blog, you will have a thorough understanding of how to effectively manage pod termination in your Kubernetes environment, ensuring smooth and efficient operations.
The Lifecycle Phases of Pod Termination
In Kubernetes, graceful termination means that the system gives the pods time to finish serving in-progress requests and shut down cleanly before removing them. This helps to avoid disruption and loss of data. Kubernetes supports graceful termination of pods, and it’s achieved through the following steps:
When a pod is asked to terminate, Kubernetes updates the object state and marks it as “Terminating”.
Kubernetes also sends a SIGTERM signal to the main process in each container of the pod.
The SIGTERM signal is an indication that the processes in the containers should stop. The processes have a grace period (default is 30 seconds) to shut down properly.
If a process is still running after the grace period, Kubernetes sends a SIGKILL signal to force the process to terminate.
To gracefully terminate the pod you can either add terminationGracePeriodSeconds to your spec or add kubectl delete pods <pod> –grace-period=<seconds>
The below contains a time series graph for graceful termination:
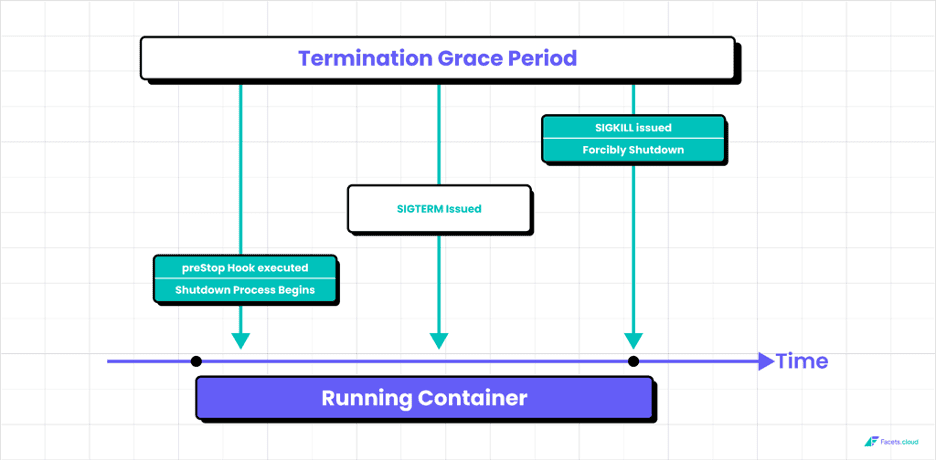
The “preStop” hook is executed just before a container is terminated.
When a pod’s termination is requested, Kubernetes will run the preStop hook (if it’s defined), send a SIGTERM signal to the container, and then wait for a grace period before sending a SIGKILL signal.
Here’s an example of how you might define a preStop hook in your pod configuration:
```yaml
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: my-image
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "echo Hello from the preStop hook"]
```In this example, the preStop hook runs a command that prints a message to the container’s standard output.
The preStop hook is a great place to put code that:
- Waits for connections to close
- Cleans up resources
- Notifies other components of the shutdown
NOTE: Remember that Kubernetes will run the preStop hook, then wait for the grace period (default 30 seconds) before forcibly terminating the container. If your preStop hook takes longer than the grace period, Kubernetes will interrupt it.
The above image explains it.
Factors Influencing Pod Termination
1. How resource constraints impact pod termination decisions.
- Pod Eviction due to Resource Constraints: Kubernetes nodes monitor for conditions that indicate system resources are running low. When resources such as CPU, memory, disk space, or filesystem inodes reach certain thresholds, the node enters a condition of ‘DiskPressure’ or ‘MemoryPressure.’ In such cases, the kubelet (the Kubernetes agent running on each node) tries to reclaim resources by evicting pods. Pods with a lower quality of service, such as BestEffort or Burstable pods exceeding their request, are evicted first.
- Pod Termination due to Out of Memory / CrashloopBackoff : If a node is severely low on memory, the Linux kernel’s Out of Memory (OOM) Killer process kicks in and starts terminating processes to free up memory. In a Kubernetes context, this could lead to abrupt termination of your pods. This is not a graceful termination, so it’s usually a situation to avoid. You can mitigate such scenarios by setting appropriate resource requests and limits for your pods.
- Pod Termination due to Unschedulable Pods: When you create a pod, if there is not enough resource in any of the nodes to meet the resource request of the pod, the pod remains in a state of Pending. This could lead to pod termination if it remains unscheduled for a long time.
2. Strategies for optimizing resource allocation to mitigate potential issues.
- Set Resource Requests and Limits: For each pod, you can specify resource requests and limits. The request is the amount of resource that Kubernetes guarantees for the pod, and the limit is the maximum amount of resource the pod can use. By setting these appropriately, you can ensure that your pods have the resources they need and also prevent them from using up too many resources and affecting other pods.
```yaml
resources:
limits:
cpu: "1"
memory: 1000Mi
requests:
cpu: 200m
memory: 500Mi
```- Use Quality of Service Classes: Kubernetes assigns pods to Quality of Service (QoS) classes (Guaranteed, Burstable, or BestEffort) based on their resource requests and limits. Pods with higher QoS classes are less likely to be evicted. You can optimize resource allocation by adjusting these settings to assign your most critical pods to the Guaranteed class.
Guaranteed: All containers in the pod have CPU and memory requests and limits, and they’re equal.
```yaml
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "64Mi"
cpu: "250m"
```Burstable: At least one container in the pod has a CPU or memory request. Or if limits and more than the requests
```yaml
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
```
BestEffort: No containers in the pod have any CPU or memory requests or limits.
```yaml
resources:{}
```- Namespace Resource Quotas: You can use ResourceQuotas to limit the total amount of resources that can be used in a namespace. This can prevent runaway consumption by a single team or project. Within a namespace, you can also use LimitRanges to set defaults and constraints on the resource requests and limits for individual pods.
```yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
spec:
hard:
pods: "10"
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi
```- Node Affinity Rules: These rules allow you to influence where pods are scheduled based on the labels of nodes. For example, you could use node affinity to ensure that high-memory pods are scheduled on high-memory nodes.
```yaml
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
containers:
- name: nginx-container
image: nginx
```- Taints and Tolerations: Taints allow a node to repel a set of pods, and tolerations can be added to pods to allow (but not require) them to be scheduled onto nodes with matching taints
kubectl taint nodes node1 key=value:NoSchedule
```yaml
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: my-image
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule"
```- Autoscaling: Using HPA and VPA to scale and right size deployments
Handling Persistent Data and Storage
In Kubernetes, a StatefulSet ensures that each Pod gets a unique and sticky identity, which is important in maintaining the state for applications like databases. When it comes to Pod termination, Kubernetes handles it a bit differently in StatefulSets compared to other Pod controllers like Deployments or ReplicaSets.
Here are the steps how Kubernetes handles pod termination in StatefulSets:
- Scaling Down/ Deleted : When a StatefulSet is scaled down or commissioned to be destroyed, Kubernetes will terminate the Pods in reverse order, starting from the highest to the lowest, ensuring that the state is maintained. For example, if you have pods named web-0, web-1, web-2, and scale down, web-2 would be deleted first, then web-1, and so on.
- Graceful Termination: Just like other pods, StatefulSet pods also go through the graceful termination process. When a pod is deleted, Kubernetes will send a SIGTERM signal to allow the pod to shut down gracefully. It allows the pod to finish processing any in-flight requests and prepare for shutdown before it is removed. If the process doesn’t exit within the grace period (default 30 seconds), a SIGKILL signal will be sent to forcibly shut it down. You can check the above explanations
- PreStop Hook: If a preStop lifecycle hook is defined in the pod specification within a StatefulSet, it will be executed before the pod is terminated. This provides an opportunity to perform any cleanup or final actions before the pod is deleted.
- Pod Identity: With StatefulSets, the identity of the pod is preserved across rescheduling. If a node fails and a pod needs to be rescheduled, the replacement pod will have the same network identity (name and hostname) and if persistent volumes are used, the same data from the same PersistentVolumeClaim (PVC).
- Pod Storage: If a pod in a StatefulSet has attached storage, the storage (PVC) is not removed when the pod is deleted. This ensures that if a new pod is scheduled with the same identity, it can resume where the old one left off.
Troubleshooting Pod Termination Issues
Identification of common issues related to pod termination:
- Pods stuck in Terminating state: Sometimes, pods can get stuck in the Terminating state due to various reasons like storage issues, finalizers stuck in deletion, or network issues.
- Pod Disruption Budgets: If you have set a Pod Disruption Budget (PDB) which limits the number of pods of a replicated application that are down simultaneously from voluntary disruptions, it can prevent voluntary termination of pods.
Practical troubleshooting tips and solutions:
- Pods stuck in Terminating state: For pods stuck in the Terminating state, you can force delete the pod with kubectl delete pod <PODNAME> –grace-period=0 –force. However, this should be a last resort as it can cause data loss. It’s better to identify the root cause by checking the pod description (kubectl describe pod <PODNAME>) and looking for any errors.
- Pod Disruption Budgets: If you have a PDB that’s preventing pod termination, you may need to reconsider your PDB settings. If necessary, you can delete the PDB, but be aware that this may impact the availability of your application. Always consider the implications and plan downtime accordingly.
Conclusion
A solid understanding of pod termination in Kubernetes keeps applications running smoothly as workloads grow. By mastering Kubernetes tools, configuring resources well, and using best practices, you can create a resilient environment. Solutions like Facets enhance these efforts, automating terminations, managing resources, and meeting scaling needs with ease.
Ultimately, a thoughtful approach to Kubernetes pod termination not only improves the stability and scalability of your infrastructure but also empowers teams to deliver higher-quality services faster, with minimal disruption to end-users.