

Member post originally published on the Middleware blog by Sam Suthar
In the race to adopt cutting-edge technologies like Kubernetes, microservices, and serverless computing, monitoring often becomes an afterthought. Many enterprises assume their legacy observability tools will suffice. However, as they transition to the cloud and adopt distributed architectures, they face challenges that are significantly harder to resolve.
Take the case of Generation Esports, a platform supporting large-scale online gaming tournaments. Their shift from a monolithic architecture to microservices revealed critical issues. Latencies in their services increased by 40%, and cascading failures disrupted key operations, leading to delays in tournament schedules and affecting user satisfaction.
By leveraging observability 2.0 practices tailored for distributed systems, Generation Esports achieved a 75% reduction in observability costs and improved their mean time to resolution (MTTR) by 75%.
These improvements not only enhanced system reliability but also ensured a seamless user experience, allowing them to scale their platform efficiently to meet growing demand.
This real-world example demonstrates how outdated observability solutions fall short in modern environments. Observability 2.0 addresses these gaps with unified telemetry, AI-driven anomaly detection, and proactive troubleshooting.
Understanding observability 2.0
As systems evolve into distributed architectures powered by microservices, traditional observability approaches struggle to keep up. Observability 2.0 represents a significant shift, addressing the limitations of traditional methods while introducing tools and practices designed for modern, cloud-native environments.
Key differences between traditional observability and observability 2.0
- Data handling:
- Traditional: Relies on separate tools for metrics, logs, and traces, creating silos and requiring manual correlation.
- 2.0: Unifies telemetry data into a single platform, offering a comprehensive view of system health.
- Problem detection:
- Traditional Uses static thresholds and alerts that are often reactive and miss subtle issues.
- 2.0: Employs AI and machine learning to identify anomalies in real-time, enabling proactive issue resolution.
- Focus on context:
- Traditional: Provides raw technical data without linking it to broader business outcomes.
- 2.0: Maps telemetry data to business metrics, ensuring decisions align with organizational goals.
- Scalability and adaptability:
- Traditional Struggles with dynamic environments like Kubernetes and serverless, often requiring custom setups.
- 2.0: Designed for dynamic scaling, adapts with ease to changes in cloud-native architectures.
Why traditional methods fall short
Traditional observability tools work well in static environments but falter when applied to dynamic, distributed systems. For example, a legacy monitoring system might flag increased latency but fail to trace its root cause across interdependent services.
Observability 2.0 addresses this by correlating data across metrics, logs, and traces, providing a clear path to the root cause. This approach ensures faster resolution and minimizes downtime, even in complex architectures.
By embracing Observability 2.0, teams can move beyond surface-level observability to gain actionable insights that improve reliability and performance across their systems.
How observability 2.0 enables modern software development
Moving beyond traditional monitoring
Traditional monitoring tools focus on predefined metrics and static alerts. While they can indicate symptoms like high CPU usage or increased error rates, they fail to correlate data across distributed services, leaving teams guessing about root causes.
Observability 2.0 shifts the focus to comprehensive insights by integrating metrics, logs, traces, and events. This correlation provides real-time analytics, helping teams diagnose and resolve issues faster, even in complex environments.
The role of metrics, logs, traces, telemetry data, and events in observability 2.0
Observability 2.0 combines these core telemetry data types to create a complete picture of system behavior:
- Metrics: Numerical data points representing resource utilization, such as CPU and memory usage, that indicate overall system health.
- Logs: Time-stamped records of system activities, capturing events and errors for detailed analysis.
- Traces: End-to-end request tracking, mapping service interactions, and pinpointing bottlenecks in distributed architectures.
- Events: Key occurrences that highlight changes in system behavior, such as deployment updates or scaling actions.
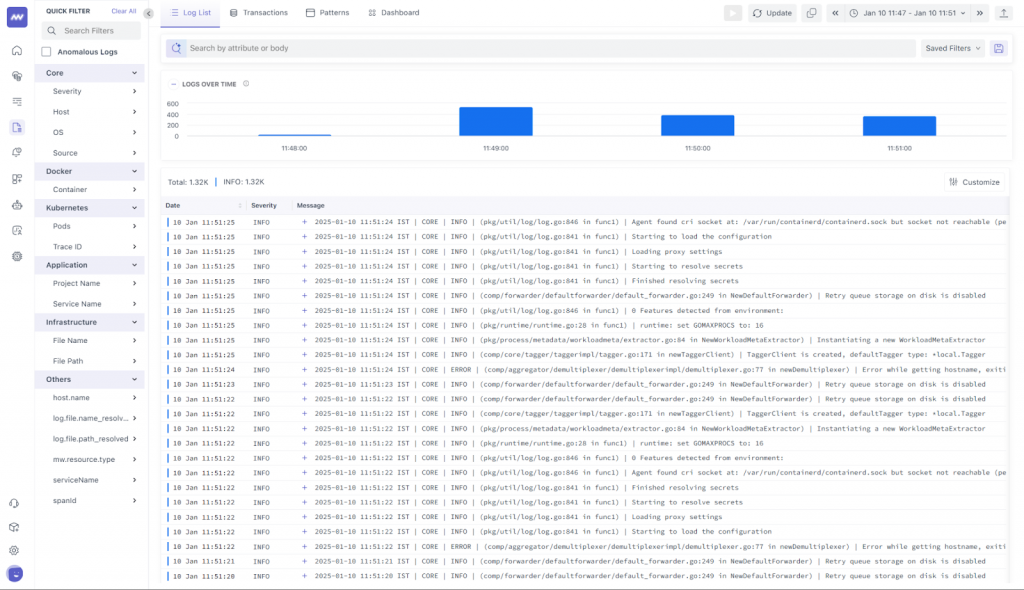
By integrating these data types into a unified platform, Observability 2.0 enables faster and more accurate root cause identification.
Example: Diagnosing API latency
Imagine a scenario where an API experiences latency spikes during peak hours, affecting application performance. Traditional monitoring tools might flag high response times but fail to identify the underlying cause. With Observability 2.0:
- Metrics reveal the spike in latency.
- Logs indicate slow database queries during those times.
- Traces pinpoint the exact microservice responsible for the delay.
- Events highlight a recent deployment that impacted performance.
This holistic view enables teams to address the issue quickly, minimizing user impact.
Comparing logs and traces in traditional observability vs. observability 2.0
While traditional observability tools utilize logs and traces, their approach is fragmented and lacks real time correlation. Observability 2.0, on the other hand:
- Centralizes telemetry data for easy access.
- Uses machine learning to detect patterns and anomalies.
- Provides actionable insights by linking telemetry data across services.
By bridging these gaps, Observability 2.0 gives teams more power to manage modern systems more effectively and improve software development processes.

Why observability 2.0 outperforms traditional methods
Traditional observability tools were designed for more straightforward, monolithic architectures. They rely on fragmented telemetry, static rules, and manual processes, making them inefficient for modern, dynamic environments.
Observability 2.0 enhances visibility, automates data collection and correlation, and uses machine learning to uncover insights that would otherwise be missed. This enables faster incident resolution, reduced downtime, and improved system performance.
Top 5 key features of observability 2.0
Observability 2.0 brings a modern approach to monitoring systems, overcoming the limitations of traditional tools. Here’s how it stands out and why it’s a game-changer for dynamic environments:
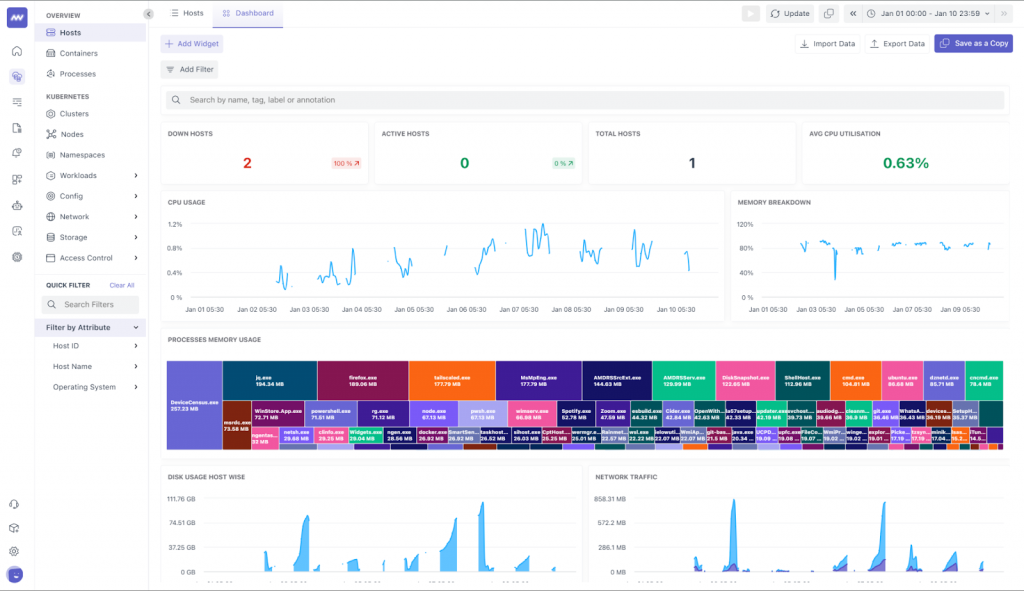
1. Unified telemetry streams
Modern systems generate vast amounts of telemetry data: metrics, logs, traces, and events. Observability 2.0 brings these data types together into one platform, eliminating the silos that traditional tools often create. With everything in one place, teams can connect the dots more easily, moving between metrics and traces without wasting time switching tools or piecing together incomplete information. This unification makes troubleshooting easier and fosters better collaboration across teams.
2. AI-Powered anomaly detection
Traditional monitoring tools rely on predefined thresholds, which often fail to catch subtle problems. Observability 2.0 takes a different approach by using machine learning to understand system behavior over time. It identifies patterns, sets dynamic baselines, and flags deviations before they escalate into major issues. This shift from reactive to proactive monitoring reduces downtime and gives teams more confidence in managing complex systems.
“AI-driven anomaly detection capabilities enable the identification of unknown unknowns, detecting unusual patterns of behavior not seen before, and allowing for timely investigation and remediation.” Sam Suthar, Founding Director, Middleware
3. Telemetry data contextualization
Telemetry data in isolation can be overwhelming and hard to act on. Observability 2.0 changes this by adding context linking raw data to business metrics like revenue impact or customer satisfaction. This means that teams can focus on resolving issues that have the greatest business value rather than chasing technical anomalies with little relevance. Contextualization bridges the gap between engineering teams and business goals, helping organizations make smarter decisions.
4. Proactive root cause analysis
Pinpointing the root cause of an issue in traditional setups often feels like searching for a needle in a haystack. Observability 2.0 simplifies this process by automatically correlating telemetry data to identify where the problem started. With tools that map dependencies and analyze historical data, teams can quickly zero in on the source of failures, resolve them faster, and implement measures to prevent recurrence.
5. Scalability and flexibility
Dynamic environments like Kubernetes and multi-cloud architectures demand tools that can keep up. Observability 2.0 is built to handle this complexity, scaling smoothly with your infrastructure. Whether it’s monitoring a spike in traffic during a global event or integrating with diverse tech stacks, Observability 2.0 ensures that performance and visibility remain consistent, even as your systems grow.
Challenges solved by observability 2.0
Modern software systems face several challenges due to their complexity and dynamic nature. Observability 2.0 addresses these issues effectively, ensuring better performance and reliability.
Complex distributed systems
Distributed architectures like Kubernetes, microservices, and serverless computing introduce intricate dependencies between components in a distributed system. A failure in one service can trigger cascading issues across others, making root cause identification difficult with traditional tools.
Observability 2.0 simplifies this by linking telemetry data across services. Correlating metrics, logs, and traces provides end-to-end visibility, enabling teams to pinpoint root causes quickly and restore normal operations with minimal disruption.
Improving MTTD and MTTR
Mean Time to Detect (MTTD) and Mean Time to Resolve (MTTR) are critical metrics for any system’s reliability. Traditional tools often delay issue detection due to fragmented data and manual correlation.
Observability 2.0 uses automation and machine learning to reduce these times significantly. With proactive alerts and real-time anomaly detection, teams can identify incidents earlier and resolve them faster, minimizing downtime and enhancing user experience.
Proactive monitoring and incident management
Observability 2.0 takes monitoring beyond simple alerts by using AI to predict and prevent potential disruptions. AI-driven insights detect anomalies in system behavior, correlate them with historical data, and trigger automated responses.
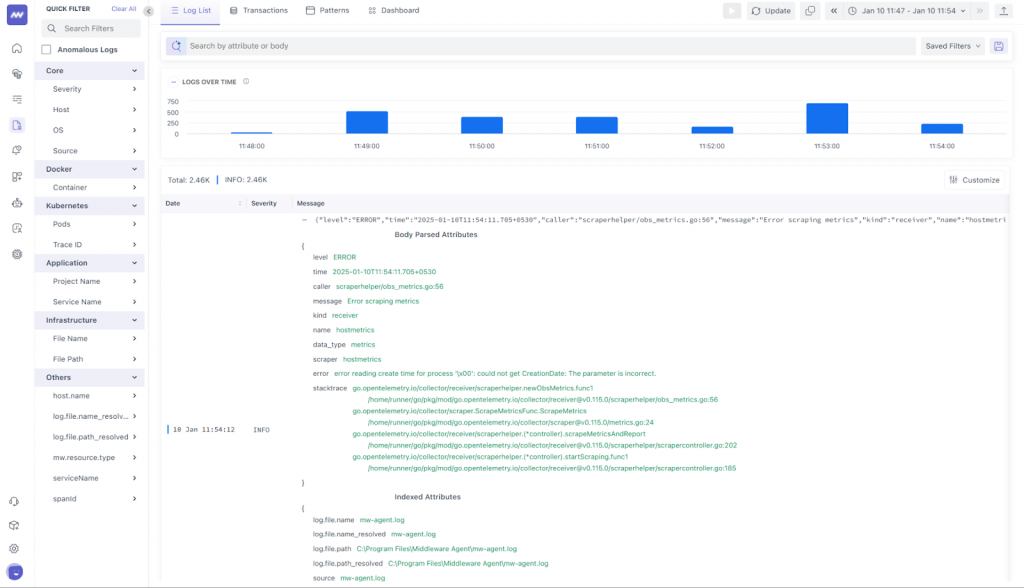
This proactive approach ensures minimal downtime and enhances overall system reliability. Teams can address issues before they affect users, maintaining consistent performance even during peak loads or unexpected traffic spikes.
Observability 2.0 in action: Tools and frameworks
To implement Observability 2.0 effectively, organizations can use a range of tools designed to integrate with modern architectures and deliver actionable insights. These tools provide the foundation for unifying telemetry, automating incident management, and ensuring scalability.
Top 8 observability 2.0 tools
- Middleware: A cloud-agnostic observability platform offering AI-driven insights, unified telemetry, and proactive troubleshooting to manage modern distributed systems effectively.
- OpenTelemetry: An open-source observability tool for collecting metrics, logs, and traces across applications.
- Prometheus and Grafana: Tools for collecting, aggregating, and visualizing metrics across distributed systems.
- Jaeger: A distributed tracing tool that provides insights into service dependencies and bottlenecks.
- Datadog and Dynatrace: Full-stack observability solutions with integrated telemetry, anomaly detection, and performance monitoring.
- New Relic: A cloud-based platform with AI integrations to align technical metrics with business outcomes.
Choosing the right tools
Selecting the best observability platform depends on your system’s architecture, scalability needs, and business goals:
- Scalability: Tools like Prometheus and Datadog excel in handling massive deployments.
- Ease of Use: Grafana and New Relic offer user-friendly dashboards that simplify data interpretation.
- Integration: OpenTelemetry is ideal for hybrid environments with diverse tech stacks.
- Business KPIs: Tools like Middleware align telemetry insights with metrics like revenue impact and customer satisfaction.
Note: Specific implementation steps may vary, but a few tools offer detailed guides for instrumenting telemetry data and achieving Observability 2.0.
Scaling observability with distributed architectures
Modern systems generate massive amounts of telemetry data across microservices, creating correlation, latency, and data overload challenges. Observability 2.0 tackles these challenges with:
- Sampling and filtering: Configuring tools like OpenTelemetry to collect representative data without overwhelming storage.
- Aggregated metrics: Using Prometheus to summarize data for more efficient analysis.
- Dynamic visualization: Leveraging Grafana to create dashboards that adapt to large-scale telemetry data.
By implementing these practices, organizations can scale observability to handle high data volumes and maintain performance in distributed environments.
Measuring success with observability 2.0
Key Performance Indicators (KPIs)
Observability 2.0 goes beyond technical metrics, linking system health to business outcomes by understanding how to collect data from different endpoints and services. Here are the KPIs organizations should track:
- Application health:
- Uptime: Ensure systems are operational nearly 100% of the time, especially for mission-critical applications.
- Error rates: Monitor errors across application and infrastructure levels to address systemic issues early, such as repeated HTTP 500 errors.
- Business metrics:
- Revenue impact: Identify technical issues affecting revenue, such as dropped transactions during critical events.
- User engagement: Correlate performance with customer behavior, like session duration and tournament participation rates.
- User experience:
- Latency: Measure API and page load times, as even small delays can frustrate users.
- Response times: Focus on quick responses to critical user actions, ensuring smooth interaction and customer satisfaction.
Aligning observability with business goals
Observability 2.0 connects technical performance to strategic objectives, enabling organizations to:
- Use telemetry insights to identify performance improvement opportunities.
- Ensure every technical decision aligns with business KPIs, such as reduced downtime or increased user retention.
- Optimize user experiences to boost customer loyalty and satisfaction.
Observability as a revenue accelerator
The next iteration of observability shifts the perception of telemetry data from a technical necessity to a business enabler. By embedding observability across teams and aligning it with business goals, organizations can:
- Identify performance improvement opportunities proactively.
- Ensure IT decisions positively impact revenue and customer retention.
- Deliver optimized user experiences that drive growth and success.
The challenges of implementing observability 2.0
Implementing Observability 2.0 can be transformative but comes with its own set of challenges:
1. Integration complexity
Adopting new tools in systems with legacy architectures or hybrid environments, especially those involving control systems, can be difficult.
- Challenge: Instrumenting older monolithic systems may require significant code changes.
- Example: Monolithic applications often lack native tracing support, requiring extensive modifications to collect telemetry.
- Tie-back: Without careful planning, this complexity can create additional silos, undermining the goal of unified observability.
- Solution: Tools like OpenTelemetry help bridge modern observability with legacy applications.
2. Data overload
Modern systems generate immense amounts of telemetry data, which can overwhelm teams trying to deduce internal states from external outputs.
- Challenge: Millions of telemetry events daily can make it difficult to identify critical issues.
- Example: Excessive logs can obscure important signals, leading to analysis paralysis.
- Tie-back: This noise hinders decision-making and diverts focus from resolving key issues.
- Solution: Intelligent filtering systems and anomaly detection can focus on relevant data, reducing noise and improving signal clarity.
3. Cost considerations
Scaling observability across large systems using observability platforms can become expensive.
- Challenge: Costs for data storage, premium tools, and training can grow rapidly.
- Example: Large-scale implementations may lead to high storage expenses for telemetry data.
- Tie-back: Mismanaged costs can reduce ROI and strain budgets.
- Solution: Start with open-source tools like Prometheus and monitor tool utilization to eliminate redundancy.
The solution?
- Integration made simpler:
- Use tools that support open standards, such as OpenTelemetry.
- Adopt gradual rollouts to minimize disruptions and allow teams to adapt incrementally.
- Managing data overload:
- Implement anomaly detection to prioritize critical events.
- Use aggregated metrics to provide a concise overview of system health.
- Balancing costs:
- Take advantage of free-tier plans or open-source tools during the initial phase.
- Regularly monitor usage to identify and eliminate redundant services.
- Overcoming challenges with control theory:
- Control theory, a foundational concept that informs observability, helps engineers infer internal states from external data.
- Use tools that support open standards, such as OpenTelemetry.
- Adopt gradual rollouts to minimize disruptions and allow teams to adapt incrementally.
- Managing data overload:
- Implement anomaly detection to prioritize critical events.
- Use aggregated metrics to provide a concise overview of system health.
- Balancing costs:
- Take advantage of free-tier plans or open-source tools during the initial phase.
- Regularly monitor usage to identify and eliminate redundant services.
Final thoughts
Modern systems demand more than traditional monitoring can provide. Observability 2.0 addresses this challenge by delivering unified telemetry, AI-driven insights, and automation to manage the growing complexity of infrastructure. By adopting Observability 2.0, organizations can reduce downtime, enhance user experiences, and align their technical efforts with business objectives.
The future of observability will see even greater integration of AI and automation. Predictive capabilities will detect issues before they arise, while automated remediation will expedite incident response. Organizations adopting Observability 2.0 today are positioning themselves for a future of self-optimizing, highly reliable systems.