Cloud native infrastructure continues to scale, and with it, so does operational overhead. Kubernetes has become the backbone of modern platforms, but as cluster sizes grow past 100 nodes and thousands of workloads, the operational load can be intense.
At this scale, it’s not unusual for organizations to require at least five dedicated Site Reliability Engineers (SREs) to ensure uptime, manage costs, and handle scaling. SREs are stretched thin managing configurations, remediating failures, tuning resource limits, and staying ahead of performance issues.
Infrastructure as Code (IaC) tools and observability platforms have provided much-needed support. However, as systems evolve, we are hitting the ceiling of what human effort alone can maintain. So, the real question emerges: how can we manage modern infrastructure more efficiently and more sustainably?
The Role of LLMs in SRE Workflows
Large Language Models (LLMs) are often associated with natural language queries and code generation, but their potential in infrastructure operations goes far deeper.
LLMs can:
- Interpret complex logs and system events
- Summarize root causes based on error patterns
- Assist in decision-making by correlating signals across monitoring systems
- Suggest or automate configuration changes in real time
This isn’t about replacing SREs. It’s about supporting and enhancing their capabilities. While using LLMs to provision infrastructure, such as generating Terraform or Helm charts, is a popular use case, the more urgent challenge lies in real-time operations. The real question is what happens once your infrastructure is up and running.
Real-Time Ops: Where LLMs Truly Matter
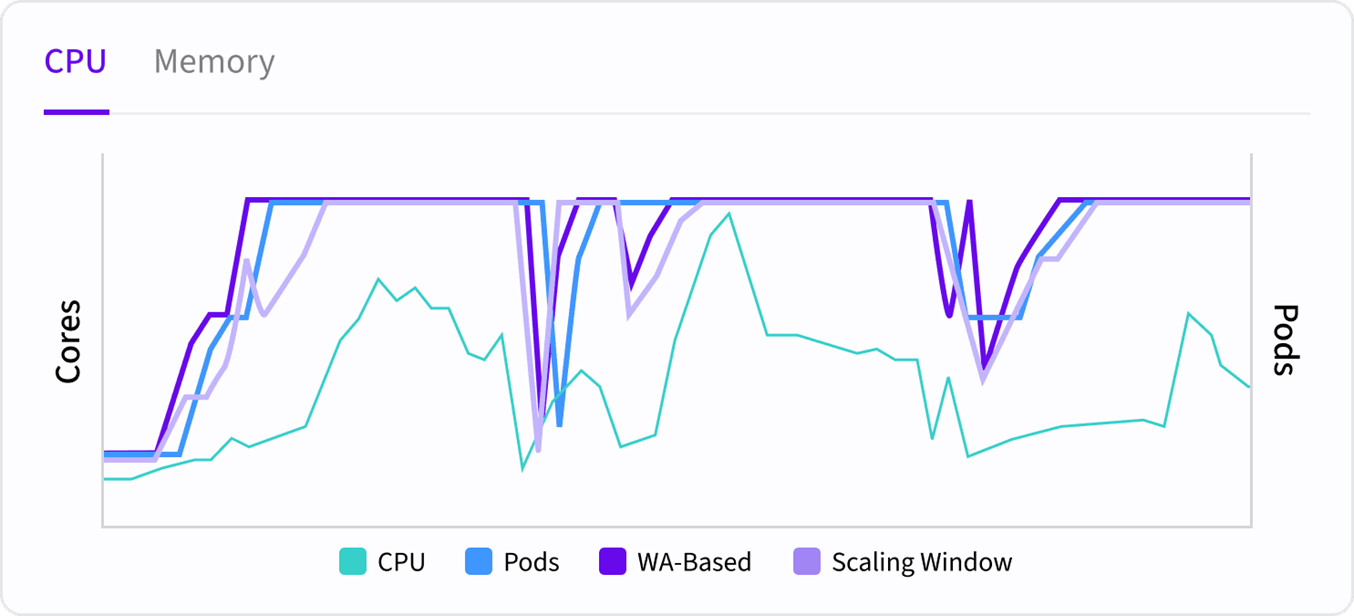
Modern SREs don’t just build systems. They operate them 24/7. This is where fatigue starts to build. Failures, scaling issues, and performance anomalies often arise without warning and require immediate attention. LLMs can serve as intelligent assistants here, helping with:
- Failure diagnosis: Parsing pod logs, container events, and alerting noise to pinpoint the actual issue
- Policy recommendations: Adjusting autoscaler thresholds, resource requests, or retry settings based on patterns
- Smart remediation: Applying known fix patterns automatically (or semi-automatically) when specific conditions are met
The combination of language understanding, pattern recognition, and system context gives LLMs a unique advantage in operational settings.
AI-Native Kubernetes Automation: What’s Emerging
Kubernetes platforms are beginning to integrate AI and large language models (LLMs) directly into their control loops. New solutions are emerging to enable intelligent automation at scale, particularly in large and complex Kubernetes environments where traditional operational approaches are reaching their limits.
Some examples of AI-native capabilities include:
- Autopilot: Fully automated horizontal scaling powered by a combination of LLMs and machine learning models, intelligently adjusting replicas based on workload patterns—no manual tuning required.
- Smart Sizing: Vertical scaling that uses ML to continuously right-size CPU and memory requests, optimizing performance and cost without guesswork.
- Pod Recovery AI: LLM-powered analysis of failure events such as crash loops or container restarts, capable of diagnosing issues and suggesting or triggering recovery actions.
These features are designed to reduce manual tuning and help SREs focus on higher-leverage tasks.
One Engineer, One Thousand Workloads?
This isn’t just a futuristic idea. It’s quickly becoming reality.
Just as GitOps changed how we manage configurations, LLMs and AI are reshaping how we manage the lifecycle of running infrastructure. We’re moving toward a world where one or two engineers can manage what used to take entire teams, thanks to assistive and autonomous capabilities powered by AI.
It’s not about minimizing headcount. It’s about maximizing impact.
Final Thoughts
The future of SRE in cloud native environments will be shaped by how effectively we bring intelligence into day-to-day operations. With the rapid advancement of LLMs, we are entering a new phase where scaling infrastructure no longer requires scaling teams at the same rate.
As AI-native platforms continue to evolve, SREs will spend less time firefighting and more time architecting for resilience, performance, and innovation.
Looking Ahead
Simplifying Kubernetes operations is no longer a distant goal. With the rise of intelligent automation, teams now can streamline workflows, improve resource efficiency, and reduce operational overhead.
As the ecosystem continues to evolve, adopting AI-driven approaches could be the key to managing complexity and unlocking the full potential of cloud native infrastructure. Now is the time to explore what’s possible.