
How IBM watsonx Assistant uses Knative Eventing to train machine learning models
Challenge
As IBM’s strategy on cloud evolved and moved towards private and hybrid cloud, solutions such as IBM Cloud Pak for Data and Managed Cloud Service Provider (MCSP) now require highly portable watsonx services capable of running on customer hardware, private infrastructure, and datastore providers that IBM will not have access to. Our existing machine learning training infrastructure, originally designed with a focus on public cloud infrastructure a few years ago, underwent an upgrade to ensure compatibility across various cloud infrastructure solutions. However, as our customer base expanded across these platforms, the associated cost of operations increased. In parallel there was growing pressure to improve the machine learning training time to improve the client experience. Over the course of time, we have heavily optimized our intent recognition algorithms and training infrastructure stack to reduce training time from 3.5 minutes to an impressive 90 seconds. Nevertheless, further optimizations posed challenges, including issues related to resource utilization and backpressure handling in a distributed setup. Recognizing the need for a comprehensive solution, we embarked on a paradigm shift to redefine our entire ML training infrastructure.
Solution
We were looking for a solution that would be simple enough to maintain while providing 100% ownership to the service team in all aspects. We prototyped a system in early 2022 using Knative Eventing (backed by Knative Kafka Broker) for our watsonx Assistant use-case. Our initial results exceeded our existing benchmarks at various levels. After investing enough time to make it production ready, we rolled it out across all production IBM cloud clusters in six geographical regions. After successfully handling hundreds of thousands of ML model trainings in this initial rollout period and monitoring the system’s resiliency and impact, we also upgraded our watsonx Assistant on CloudPak for Data and watsonx Orchestrate on AWS Marketplace offerings to utilize Knative Eventing for machine learning training via RedHat Openshift Serverless offering.
Impact
As a result of migrating to Knative to handle orchestration of our machine learning model training workloads we have seen several benefits from the simplified architecture:
60% Reduction in Training Time: The average training time has been significantly reduced from 50-90 seconds to just 15-35 seconds.
Enhanced User Experience: Users can now build a fully functional virtual agent with a few actions (approx. 6-8 trainings) in less than two minutes, offering a streamlined and improved user experience.
Number of Trainings: Millions of ML model trainings per month on IBM public cloud, globally.
Reduced Maintenance Overhead: Eliminated over 40,000 lines of code and an entire microservice with our adoption of Knative Eventing and utilization of serverless strategy, thereby simplifying maintenance processes.
Separation of Duties: Knative Eventing facilitates the isolation of brokers (via Kafka topics), allowing each watsonx service to encompass all configuration (secrets, configmaps) and routing (broker, trigger) within a single namespace. This streamlines our DevOps processes, eliminating the need to synchronize training-related secrets or certificates across various namespaces. Moreover, we can further achieve additional Separation of Duties (SOD) and regulatory compliance goals by setting up isolated data planes.
Cost Benefits: Both hardware and operational costs have been reduced, contributing to overall cost-effectiveness.
Serverless Setup: The adoption of a serverless setup paves the way for further transformation across the entire service stack, enhancing scalability and flexibility in the deployment of machine learning related microservices.
Projects used


By the numbers
Reduced overhead
Eliminated over 40,000 lines of code
build a functional virtual agent
Aprox. 6-8 trainings in less than two minutes
Millions of ML trainings
Every month on IBM public cloud
IBM watsonx Assistant is a leading conversational AI platform serving thousands of customers and millions of API calls daily across six geographic regions around the world in public cloud and private cloud customers through IBM Cloud Paks. Over 80% of these API calls engage our core machine learning infrastructure, utilized for both training and serving models. A critical part of building a conversational assistant in watsonx Assistant is the construction of “Actions” through our intuitive user interface. This process is integral to predicting the end user’s intent effectively and decides how their assistant should respond based on various conversational flows the customer has setup. In the background, each time a customer updates particular sections of an Action, it triggers the training process, leading to the creation of 5 to 6 machine learning models tailored to their unique dataset. Therefore, having a responsive authoring experience is critical. Customers of watsonx Assistant expect that the updates they make to their Actions in the build experience can be tested quickly to facilitate efficient iterations.
Our machine learning infrastructure is the backbone of the IBM watsonx Assistant service. It revolves around one major and critical premise: Efficiently managing a large volume of machine learning model training requests, characterized by rapid completion (ready to serve) within a few seconds to a few minutes. We’ve come a long way in building a common training and serving infrastructure for watsonx services on various platforms, starting with VMs a decade ago to container orchestration platforms (such as Apache Mesos/Marathon) to Kubernetes. One of the primary motivations behind our investment in a common infrastructure was to prevent service teams from dedicating time to building and maintaining infrastructure services.
Dynamic Workflow Training Infrastructure
IBM watsonx Assistant originally used a common machine learning infrastructure for training called “Dynamic Workflow.” The Dynamic Workflow training infrastructure runs on Kubernetes and uses the Kubernetes API. A well defined gRPC interface exposes methods to (a) Create a training request; (b) Check Status of a training request; (c) Delete a training request; and a few other helper methods which service teams shall implement. Service teams can create a Workflow using a pre-defined YAML template containing the training image to use and other K8s resource specifications to be included with it (such as request.cpu, replicas etc). The Dynamic Workflow infrastructure uses this specification to create a dedicated deployment (in its Kubernetes namespace) containing a pod coordinator sidecar image and the training service image. The pod-coordinator sidecar uses a pull mechanism to consume requests from a messaging queue and server training requests to the training service container. The ‘Lifecycle Manager’ has a state tracker for all of the trainings initiated and also for synchronizing the workflow specification.
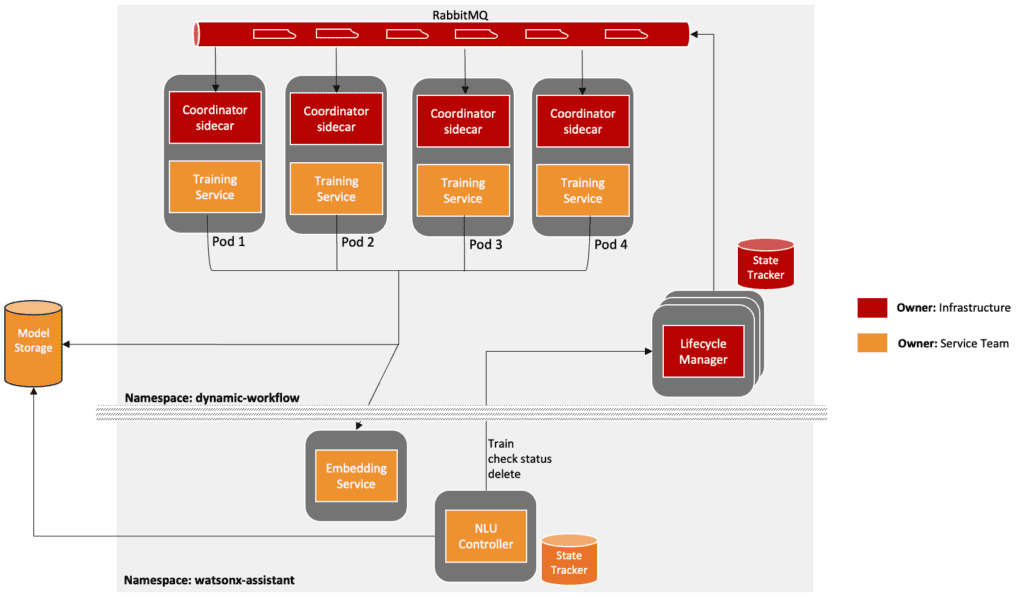
Although our dynamic workflow infrastructure simplified the overall training processes for services, as we moved towards private and hybrid cloud strategies, the following challenges and business needs became evident:
- Need for speed: As watsonx Assistant’s customer base grew bigger, the demand for training speed became very important. Even after heavy optimization strategies, nearly 55 to 75% of the total training time was attributed to infrastructural reasons with status polling and rate-limiting with further optimization leading to other impacts on the overall cost.
- Separation of Duties (SOD): Within our public cloud configuration, the service team has the option to execute its services within ‘Namespace A,’ while the training service specifically operates in ‘Namespace B,’ which is overseen by the dynamic workflow infrastructure. To maintain model version compatibility and ensure backward compatibility of serving models, synchronization between the “Training” and “Serving” services is imperative. Consequently, any new secrets or configurations introduced during releases must be replicated across both namespaces. We have implemented Role-Based Access Control (RBAC) and network policies to facilitate updates across multiple namespaces and enable seamless (and secure) communication between them. However, in the case of our private/hybrid cloud solutions, customers have direct control over the administration of such policies. Some customers may opt for strict regulatory compliance, where both the infrastructure and services operate within a single namespace. On the other hand, others may adopt diverse strategies beyond IBM’s control, contributing to potential technical support challenges.
- Information overhead: Developers and SREs work closely on any support and resiliency issues. Although we eliminated developer ownership of the ML infrastructure, in order to solve a resiliency issue, the developers on either team have to be aware of the full training process. For example, in the above picture, the communication between the training service and embedding service is very internal to the service team but the infrastructure team must be aware of it in order to attach and maintain appropriate network-policy to the namespace.
- Lack of HPA: Dynamic workflow infrastructure predates HorizontalPodAutoscaler and Custom Metrics. Consequently, efforts were made to develop an auto-scaling feature using the available Kubernetes APIs at that time. However, this implementation became complex with a custom controller and watch mechanism that posed a support risk on a private cloud. As HorizontalPodAutoscaler matured, we found ourselves exploring more straightforward alternatives, driven by various considerations outlined earlier.
The Knative Eventing Training Infrastructure
We have developed a robust machine learning training infrastructure by leveraging Knative Eventing with Kafka as the event streaming source. The knative-kafka client configurations were meticulously optimized to support our fast training use case. For instance, we achieve cooperative re-balancing by using ‘CooperativeStickyAssignor’ along with customized offset commit interval and max poll records for each consumer. By default, we support shared data-plane in both public and private/hybrid cloud platforms which customers can isolate as needed for regulatory compliance. The overall setup looks like the picture below
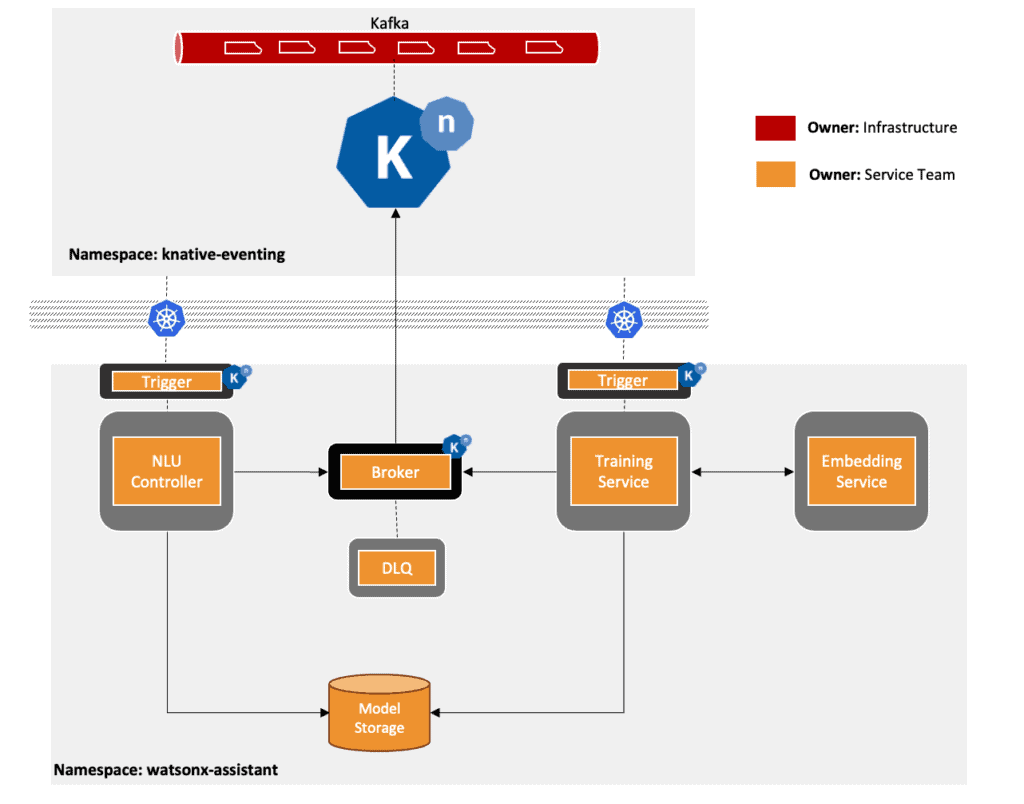
Events Specification
We have developed an internal specification for Watsonx Cloud Events, which serves as an extension to CloudEvents. This specification encompasses detailed guidelines for naming various fields within the cloud event specification, specifying permissible content for the “data” field, and outlining versioning policies. As an illustration, the “source” field adheres to a syntax “ke/{product}/{component name}/{deployment id}/{process}”. For instance, an event with the source “ke/assistant/nlu-controller/enterprise-01/train” signifies that the training event (a) belongs to the “watsonx Assistant” product; (b) Originates from the “nlu-controller” component; (c) Belongs to an enterprise customer with id “enterprise-01”; (d) Is from a method/process named “train.” This systematic approach enhances observability and facilitates the debugging process.
Training Events
Using the watsonx cloud events specification, three training events associated with the training lifecycle are defined for (1) Training Start; (2) Training Complete; (3) Training Failed.
Brokers & Triggers
We use Knative Eventing’s Broker that’s backed by Knative Kafka and Triggers as a way to send and collect events. One of the major benefits we get from using this approach is the configuration simplicity of the triggers. It’s fairly trivial for developers in our service teams to build a serverless service and then use our infrastructure by adding a few lines of configuration for a trigger.
Knative Eventing Helper Library
We created a helper library that provides a lightweight abstract EventHandler for building a serverless service that can be used on our knative eventing setup. Some critical features of this library include:
- Validation of an event payload
- Event payload construction mechanism through a builder pattern that takes care of default values. For example, developers don’t need to set the “time” or “datacontenttype”
- Lifecycle of a CloudEvents server that uses default or customizable health checks, graceful shutdown process
- An EventHandler mechanism that can be used to add custom code to process events, and set the limits on the number of events to handle at a time and various error handling mechanisms, with added support for the atomic processing of events within a pod.
- Standardized logging and metrics module for observability and for auto-scaling.
Dead Letter Sink
A common dead letter sink image is shared between service teams seeking to enable the dead letter sink service for their brokers. This service has built in metrics and alerting mechanisms needed for Service Reliability Engineers and Developers to take prompt action. Additionally, it also exposes an administrative endpoint to help with auditing and debugging outside of our regular observability dashboards.
Reflections
The introduction of the ML training infrastructure using Knative Eventing outlined above has enabled us to establish a well-defined operational boundary for the service teams. This empowers them to construct and manage their code autonomously, leveraging serverless services with complete freedom on both deployment and maintenance, including the ability to enable HPA. This autonomy has proven crucial in successfully deploying our services onto various cloud platforms, including CloudPak for Data, and Managed Cloud Service Providers (MCSP) such as AWS.
Our current setup has successfully addressed crucial aspects, and though there were initial gaps when we started, these are now actively being addressed. The Knative community has experienced continuous growth, actively contributing to address these gaps and enhance the overall robustness of the Knative Eventing architecture.